
I came across this technique while doing some research for the next post and found it so interesting that it seemed to warrant it’s own post.
Histograms and Multisets
Firstly, histogram is just a fancy word for a list of items that have an associated count.
If I were to make a histogram of the contents of my office, I would end up with something like:
- Books = 20
- Phone = 1
- Headphones = 2
- Sombrero = 1 (thanks to the roaming tequilla cart, but that’s another story…)
- VideoGames = 15
- (and so on)
Another term for a histogram is multiset, so if you see that word, just think of it as being the same thing.
Quick Dot Product Refresher
Just to make sure we are on the same page, using dot product to get the angle between two vectors is as follows:
cos(theta) = (A * B) / (||A||*||B||)
Or in coder-eese, if A and B are vectors of any dimension:
cosTheta = dot(A,B) / (length(A)*length(B))
To actually do the “dot” portion, you just multiply the X’s by the X’s, the Y’s by the Y’s, the Z’s by the Z’s etc, and add them all up to get a single scalar value. For a 3d vector it would look like this:
dot(A,B) = A.x*B.x + A.y*B.y + A.z*B.z
The value from the formulas above will tell you how similar the direction of the two vectors are.
If the value is 1, that means they are pointing the exact same way. if the value is 0 that means they are perpendicular. If the value is -1 that means they are pointing the exact opposite way.
Note that you can forgo the division by lengths in that formula, and just look at whether the result is positive, negative, or zero, if that’s enough information for your needs. We’ll be using the full on normalized vector version above in this post today though.
For a deeper refresher on dot product check out this link:
Wikipedia: Dot Product
Histogram Dot Products
Believe it or not, if you treat the counts in a histogram as an N dimensional vector – where N is the number of categories in the histogram – you can use the dot product to gauge similarity between the contents of two histograms by using it to get the angular difference between the vectors!
In the normal usage case, histograms have counts that are >= 0, which ends up meaning that two histogram vectors can only be up to 90 degrees apart. That ends up meaning that the result of the dot product of these normalized vectors is going to be from 0 to 1, where 0 means they have nothing in common, and 1 means they are completely the same.
This is similar to the Jaccard Index mentioned in previous posts, but is different. In fact, this value isn’t even linear (although maybe putting it through acos and dividing by pi/2 may make it suitably linear!), as it represents the cosine of an angle, not a percentage of similarity. It’s still useful though. If you have histogram A and are trying to see if histogram B or C is a closer match to A, you can calculate this value for the A/B pair and the A/C pair. The one with the higher value is the more similar pairing.
Another thing to note about this technique is that order doesn’t matter. If you are trying to compare two multisets where order matters, you are going to have to find a different algorithm or try to pull some shenanigans – such as perhaps weighting the items in the multiset based on the order they were in.
Examples
Let’s say we have two bags of fruit and we want to know how similar the bags are. The bags in this case represent histograms / multisets.
In the first bag, we have 3 apples. In the second bag, we have 2 oranges.
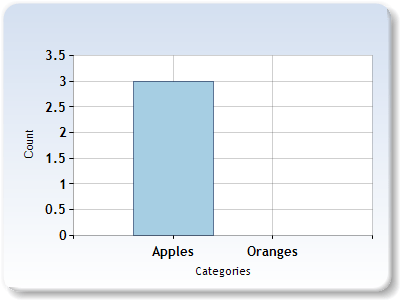
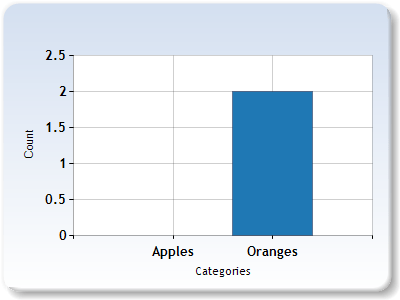
If we have a 2 dimensional vector where the first component is apples and the second component is oranges, we can represent our bags of fruit with these vectors:
Bag1 = [3, 0]
Bag2 = [0, 2]
Now, let’s dot product the vectors:
Dot Product = Bag1.Apples * Bag2.Apples + Bag1.Oranges * Bag2.Oranges
= 3*0 + 0*2
= 0
We would normally divide our answer by the length of the Bag1 vector and then the length of the Bag2 vector, but since it’s zero we know that won’t change the value.
From this, we can see that Bag1 and Bag2 have nothing in common!
What if we added an apple to bag 2 though? let’s do that and try the process again.
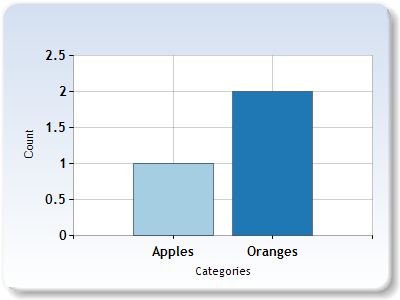
Bag1 = [3,0]
Bag2 = [1,2]
Dot Product = Bag1.Apples * Bag2.Apples + Bag1.Oranges * Bag2.Oranges
= 3*1 + 0*2
= 3
Next up, we need to divide the answer by the length of our Bag1 vector which is 3, multiplied the length of our Bag2 vector which is the square root of 5.
Cosine Angle (Similarity Value) = 3 / (3 * sqrt(5))
= ~0.45
Lets add an orange to bag 1. That ought to make it more similar to bag 2, so should increase our similarity value of the two bags. Let’s find out if that’s true.
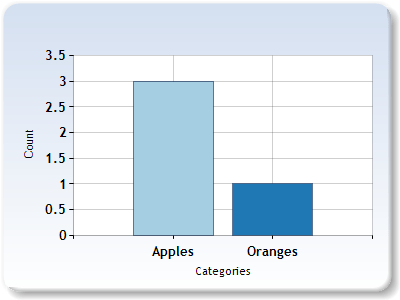
Bag1 = [3,1]
Bag2 = [1,2]
Dot Product = Bag1.Apples * Bag2.Apples + Bag1.Oranges * Bag2.Oranges
= 3*1 + 1*2
= 5
Next, we need to divide that answer by the length of the bag 1 vector which is the square root of 10, multiplied by the length of the bag 2 vector which is the square root of 5.
Cosine Angle (Similarity Value) = 5 / (sqrt(10) * sqrt(5))
= ~0.71
So yep, adding an orange to bag 1 made the two bags more similar!
Example Code
Here’s a piece of code that uses the dot product technique to be able to gauge the similarity of text. It uses this to compare larger blocks of text, and also uses it to allow you to search the blocks of text like a search engine!
#include
#include
#include
#include
#include
typedef std::unordered_map THistogram;
// These one paragraph stories are from http://birdisabsurd.blogspot.com/p/one-paragraph-stories.html
// The Dino Doc : http://birdisabsurd.blogspot.com/2011/11/dino-doc.html
const char *g_storyA =
"The Dino Doc:n"
"Everything had gone according to plan, up 'til this moment. His design team "
"had done their job flawlessly, and the machine, still thrumming behind him, "
"a thing of another age, was settled on a bed of prehistoric moss. They'd "
"done it. But now, beyond the protection of the pod and facing an enormous "
"tyrannosaurus rex with dripping jaws, Professor Cho reflected that, had he "
"known of the dinosaur's presence, he wouldn't have left the Chronoculator - "
"and he certainly wouldn't have chosen "Stayin' Alive", by The Beegees, as "
"his dying soundtrack. Curse his MP3 player";
// The Robot: http://birdisabsurd.blogspot.com/2011/12/robot.html
const char *g_storyB =
"The Robot:n"
"The engineer watched his robot working, admiring its sense of purpose.It knew "
"what it was, and what it had to do.It was designed to lift crates at one end "
"of the warehouse and take them to the opposite end.It would always do this, "
"never once complaining about its place in the world.It would never have to "
"agonize over its identity, never spend empty nights wondering if it had been "
"justified dropping a promising and soul - fulfilling music career just to "
"collect a bigger paycheck.And, watching his robot, the engineer decided that "
"the next big revolution in the robotics industry would be programming "
"automatons with a capacity for self - doubt.The engineer needed some company.";
// The Internet: http://birdisabsurd.blogspot.com/2011/11/internet.html
const char *g_storyC =
"The Internet:n"
"One day, Sandra Krewsky lost her mind.Nobody now knows why, but it happened - "
"and when it did, Sandra decided to look at every page on the Internet, "
"insisting that she wouldn't eat, drink, sleep or even use the washroom until "
"the job was done. Traps set in her house stalled worried family members, and by "
"the time they trounced the alligator guarding her bedroom door - it managed to "
"snap her neighbour's finger clean off before going down - Sandra was already "
"lost… though the look of despair carved in her waxen features, and the cat "
"video running repeat on her flickering computer screen, told them everything "
"they needed to know.She'd seen too much. She'd learned that the Internet "
"played for keeps.";
void WaitForEnter ()
{
printf("nPress Enter to quit");
fflush(stdin);
getchar();
}
template
void ForEachWord (const std::string &source, L& lambda)
{
size_t prev = 0;
size_t next = 0;
while ((next = source.find_first_of(" ,.-":n", prev)) != std::string::npos)
{
if ((next - prev != 0))
{
std::string word = source.substr(prev, next - prev);
std::transform(word.begin(), word.end(), word.begin(), ::tolower);
lambda(word);
}
prev = next + 1;
}
if (prev < source.size())
{
std::string word = source.substr(prev);
std::transform(word.begin(), word.end(), word.begin(), ::tolower);
lambda(word);
}
}
void PopulateHistogram (THistogram &histogram, const char *text)
{
ForEachWord(text, [&histogram](const std::string &word) {
histogram[word] ++;
});
}
float HistogramDotProduct (THistogram &A, THistogram &B)
{
// Get all the unique keys from both histograms
std::set keysUnion;
std::for_each(A.cbegin(), A.cend(), [&keysUnion](const std::pair& v)
{
keysUnion.insert(v.first);
});
std::for_each(B.cbegin(), B.cend(), [&keysUnion](const std::pair& v)
{
keysUnion.insert(v.first);
});
// calculate and return the normalized dot product!
float dotProduct = 0.0f;
float lengthA = 0.0f;
float lengthB = 0.0f;
std::for_each(keysUnion.cbegin(), keysUnion.cend(),
[&A, &B, &dotProduct, &lengthA, &lengthB]
(const std::string& key)
{
// if the key isn't found in either histogram ignore it, since it will be 0 * x which is
// always anyhow. Make sure and keep track of vector length though!
auto a = A.find(key);
auto b = B.find(key);
if (a != A.end())
lengthA += (float)(*a).second * (float)(*a).second;
if (b != B.end())
lengthB += (float)(*b).second * (float)(*b).second;
if (a == A.end())
return;
if (b == B.end())
return;
// calculate dot product
dotProduct += ((float)(*a).second * (float)(*b).second);
}
);
// normalize if we can
if (lengthA * lengthB dpAC)
printf(""The Dino Doc" and "The Robot" are more similarn");
else
printf(""The Dino Doc" and "The Internet" are more similarn");
// let the user do a search engine style query for our stories!
char searchString[1024];
printf("nplease enter a search string:n");
scanf("%[^n]", searchString);
// preform our search and gather our results!
THistogram search;
PopulateHistogram(search, searchString);
struct SSearchResults
{
SSearchResults (const std::string& pageName, float ranking, const char* pageContent)
: m_pageName(pageName)
, m_ranking(ranking)
, m_pageContent(pageContent)
{ }
bool operator other.m_ranking;
}
std::string m_pageName;
float m_ranking;
const char* m_pageContent;
};
std::vector results;
results.push_back(SSearchResults("The Dino Doc", HistogramDotProduct(TheDinoDoc, search), g_storyA));
results.push_back(SSearchResults("The Robot", HistogramDotProduct(TheRobot, search), g_storyB));
results.push_back(SSearchResults("The Internet", HistogramDotProduct(TheInternet, search), g_storyC));
std::sort(results.begin(), results.end());
// show the search results
printf("nSearch results sorted by relevance:n");
std::for_each(results.begin(), results.end(), [] (const SSearchResults& result) {
printf(" "%s" : %0.4fn", result.m_pageName.c_str(), result.m_ranking);
});
// show the most relevant result
printf("n-----Best Result-----n%sn",results[0].m_pageContent);
WaitForEnter();
return 0;
}
Here is an example run of this program:
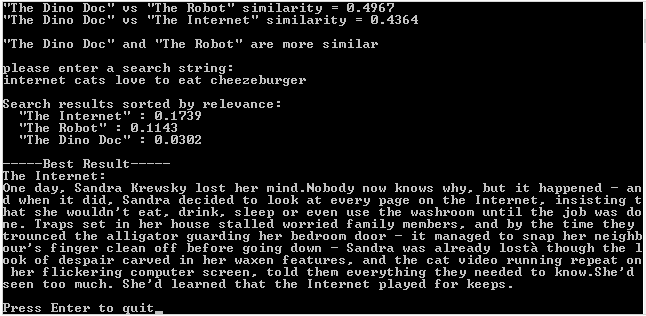
Improvements
Our “search engine” code does work but is pretty limited. It doesn’t know that “cat” and “Kitty” are basically the same, and also doesn’t know that the words “and”, “the” & “it” are not important.
I’m definitely not an expert in these matters, but to solve the first problem you might try making a “thesaurus” lookup table, where maybe whenever it sees “kitten”, “kitty”, “feline”, it translates it to “cat” before putting it into the histogram. That would make it smarter at realizing all those words mean the same thing.
For the second problem, there is a strange technique called tf–idf that seems to work pretty well, although people haven’t really been able to rigorously figure out why it works so well. Check out the link to it at the bottom of this post.
Besides just using this technique for text comparisons, I’ve read mentions that this histogram dot product technique is used in places like machine vision and object classification.
It is a pretty neat technique 😛
Links
Wikipedia: Cosine Similarity – The common name for this technique
Easy Bar Chart Creator – Used to make the example graphs
Wikipedia: tf-idf – Used to automagically figure out which words in a document are important and which aren’t
