There is ~500 lines of simple standalone C++ code that goes with this post, that generated all data used and implements the things talked about. You can find it at: https://github.com/Atrix256/BasicRootFinding
Simple equations can be solved using algebra without too much fuss:

You can even solve more complicated equations by cleverly using identities, the quadratic equation, and other mathematical tools you might have in your tool belt.
Some equations are beyond our ability to solve them using simple algebra though, like high degree polynomials:
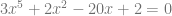
We still can find where functions like that equal zero, but we can’t do it analytically, we have to do it numerically.
That is, we do things like roll a ball down hill and hope we find a zero.
(Apparently there are some analytical solutions to be had from that function. I don’t know how to get them though, so would have to resort to numerical methods!)
This post talks about a few methods for finding zeroes of equations we can’t solve analytically, and talks about how to use those methods to find minimum and maximum values of functions as well.
The Basic Idea
Let’s say I tell you that the value of a function at a specific point is “3” and that for every step to the right you take, it subtracts 1 from that value.
Then I ask: “Where does this function equal zero?”
If you answered “three steps to the right” you are correct, and guess what – you’ve just used Newton’s method for root finding.
There is an asterisk here though. The slope (how the function value changes as you take a step to the right. Also called the derivative.) was constant in the above example, but is not going to be constant in the functions we want to solve. That slope is going to change depending where you are on the graph.
To deal with this, Newton’s method takes the step it thinks it should take, and then asks again for the value and slope (derivative) and takes another step.
The hope is that with a good initial guess, Newton’s method will find a zero without too much effort.
We’re going to get a little more formal, while also showing some results, but all the rest of what we are going to talk about is based on Newton’s method (or is even simpler).
Newton’s Method
We’ve seen this informally, but formally, a single step of Newton’s method looks like this:

That is, we divide the y value at our current point by the derivative at our current point, and subtract that from our current x to get our new x.
Bullet Points:
- Requires f(x) and f'(x)
- Requires a “good guess” for an initial x value
- Converges Quadratically
More info: https://en.wikipedia.org/wiki/Newton’s_method
Secant Method
What if you don’t have the analytical first derivative to your function and still want to use Newton’s Method?
Well, you can use finite differences to get the first derivative: move the x over a little bit, see how the y value changes over distance, and use that as your numerical derivative, instead of the analytical one. (A blog post of mine on finite differences: https://blog.demofox.org/2015/08/02/finite-differences/)
If you do that, you are now using the secant Method.
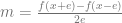
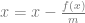
The above uses “central differences” to calculate the first derivative numerically. e is a tuneable parameter, but should be small (without triggering numerical issues) – like perhaps maybe 0.01.
Bullet Points:
- Requires f(x)
- Requires a “good guess” for an initial x value
- Converges at a rate of 1.618… (the golden ratio! ??!) so is slower than Newton’s method, but can be handy if you don’t have the first derivative.
More info: https://en.wikipedia.org/wiki/Secant_method
Halley’s Method (& Householder’s method)
If the first derivative helped us find a zero, surely the second derivative can help us find it even faster, right?
Yep. If you generalize Newton’s method to using the second derivative, you get Halley’s method.
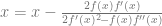
Bullet Points:
- Requires f(x), f'(x) and f”(x). You can get the derivatives numerically but it will slow down convergence.
- Requires a “good guess” for an initial x value
- Converges cubically (fast!!)
Both Newton and Halley are part of a larger family of methods called “Householder’s Method” which generalizes Newton’s method to any order derivative.
More info:
https://en.wikipedia.org/wiki/Halley%27s_method
https://en.wikipedia.org/wiki/Householder%27s_method
Bisection
Bisection is simpler than the other methods. You start with a left x and a right x, with the requirement that the signs of the y values for these x’s have to be different (one positive, one negative) which means that a zero must be between the two x’s.
The algorithm itself is just a binary search, where you look at the value in the middle of the left and right x, and update the left or right x to be the middle, based on the sign of the y value at the middle.
Bullet Points:
- Requires f(x)
- Requires a min x and a max x that contains a zero between them, and the y values at those x’s have to have opposite signs
- Converges Linearly (slow!)
More info:
https://en.wikipedia.org/wiki/Bisection_method
Experimental Results: y = x^2 – 1
Here’s the first equation:


You can see visually that there’s a zero at x=-1 and at x=1.
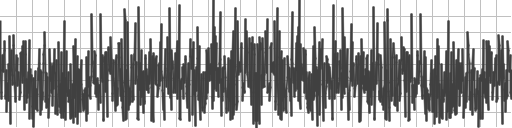
Here’s how the various methods did at finding the roots. the x axis is how many steps were taken and the y axis is the absolute value of y at that step, which also happens to be the error too, since we are finding zeros.

Halley is the winner which is unsurprising with it’s cubic convergence rate, then newton with it’s quadratic convergence rate, then secant with it’s golden ratio convergence rate, and bisect comes in last after a strong start, with it’s linear convergence rate. Our experimental results match the theory, neat!
The values in the legend next to the result name specify what parameters were used. For newton and Halley, the value shown is the initial guess. For secant, x is the initial guess and px is the previous initial guess. For bisect it shows the range given to the bisection algorithm.
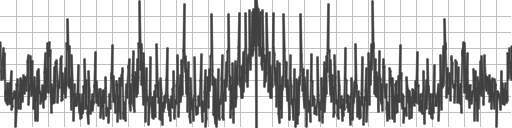
Choosing different parameters for those can drastically affect performance of the algorithms. Here are some less well chosen values shown along with the previous results. The previous results are the blue shades.
Bisection is now so bad that it dwarfs everything else. Let’s remove that.

Removing bisection, the first worst data point dropped to 100 from 2500 for all the “more poorly chosen parameters” which are orange, yellow and green. The previous values are the blues and the grey line, which basically look flat.
In these larger values with worse parameters, we are still seeing Halley winning, Newton coming in second, secant coming next, and then bisection, but we are seeing much worse performance. These parameters are important to getting good performance!
Experimental Results: y = sin(x)
Here’s the next equation:

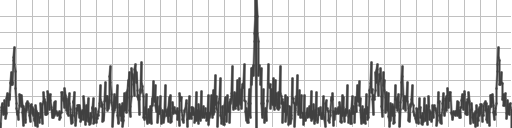
Here is the convergence for each technique:
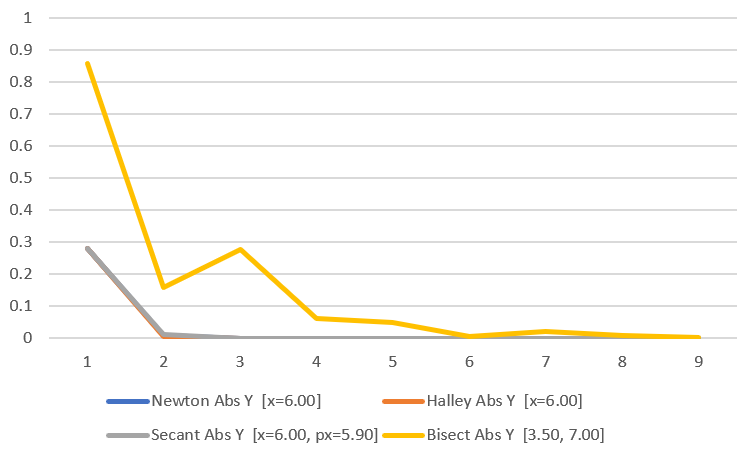
You can’t see it, but the orange, grey and blue are all basically overlapping. Looking at the actual data below though, you can see that the winners are in the same order again.
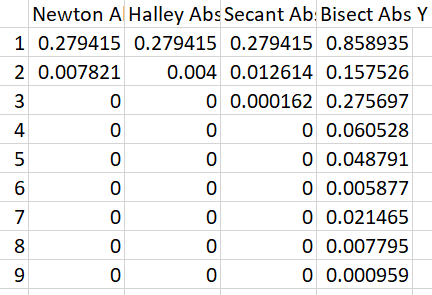
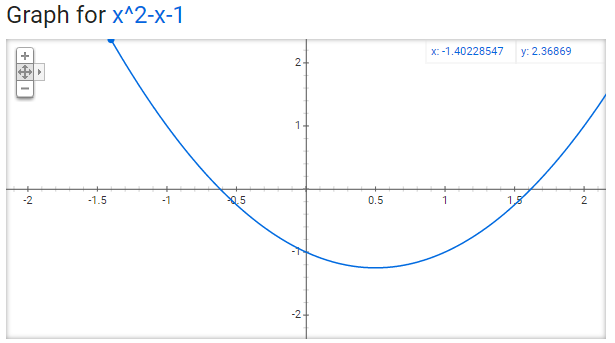
Experimental Results: y = x^2-x-1
This is a fun equation, because a zero is at the golden ratio (and the other is at -1/goldenRatio):

Here is the convergence graph:
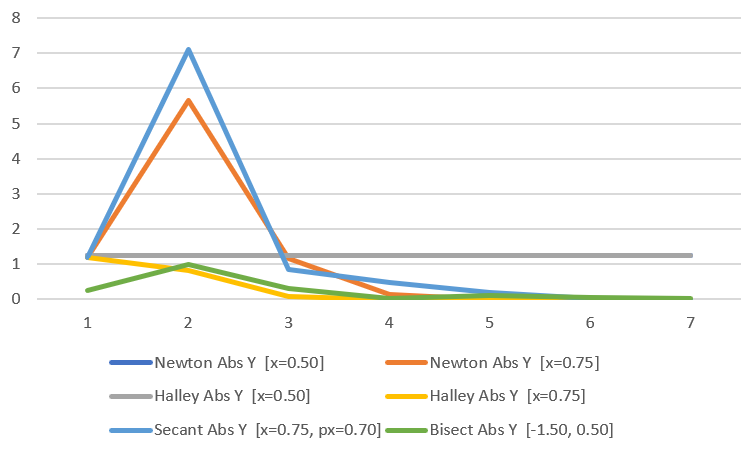
An interesting thing happens here if we choose to start at the value “0.5” for Newton and Halley. The dark blue line for Newton is under the grey line for Halley which is flat and doesn’t go up and down. The reason this happens is that the first derivative is 0 at 0.5 so the algorithm doesn’t know which direction to go and gets stuck.
Using other initial guess values causes it not to be stuck, but you can see that newton and secant starting at 0.75 has a pretty big jump in error in the beginning.
Error Case: x^2+1
For the next equation we have:
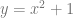
This graph has no zeroes. Our bisect bounds also do not have their needs met since one side is supposed to be negative and the other positive, but this graph is positive everywhere. That means we don’t have any results for bisect on this one.
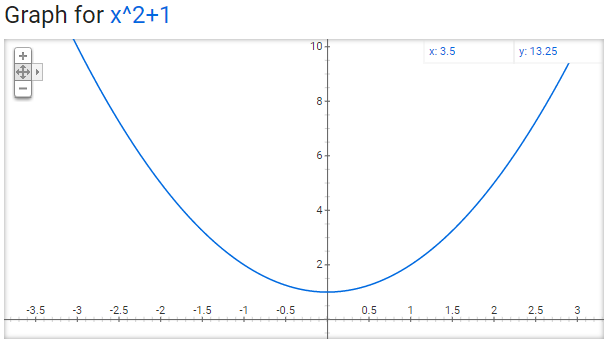
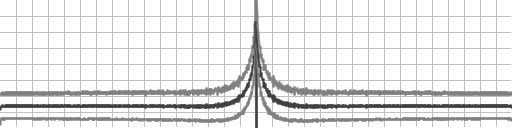
Here’s the convergence graph:

Newton goes absolutely off the rails for a few samples. Lets remove it to see what the others are doing:
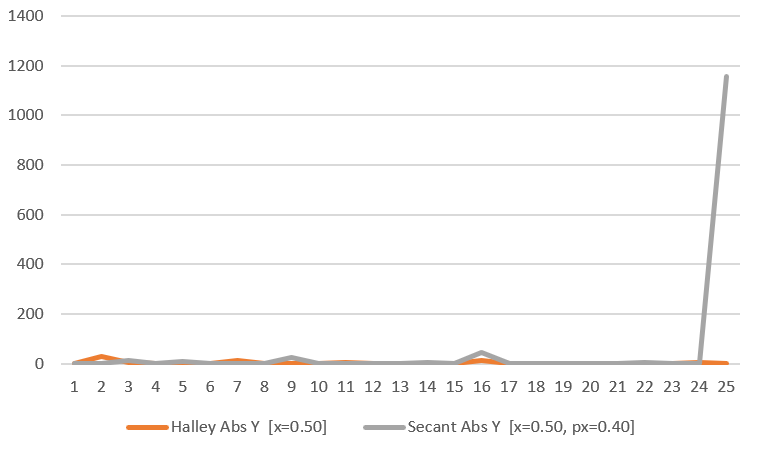
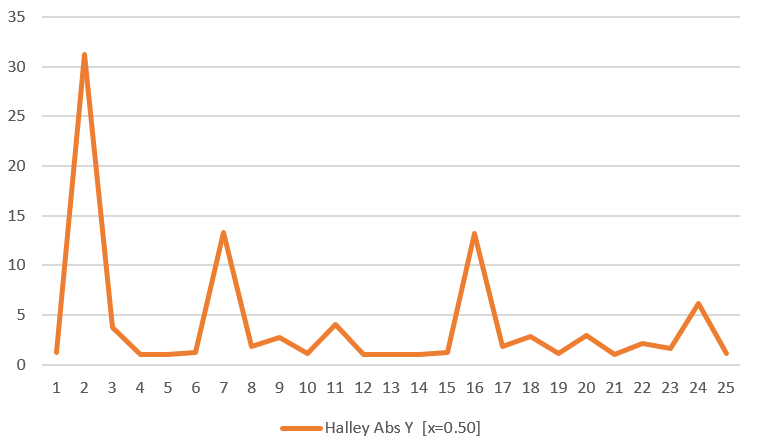
Secant goes real bad at the end, so let’s remove it to see that Halley is pretty well behaved despite there not actually being a root to find:
Ray vs Sphere
Let’s do something more interesting… let’s use these methods to find where a ray intersects a sphere. We can do this analytically (there is a formula to calculate this!) but we can use this as a simpler example of a more complex usage case.
We need a formula that is zero where a ray hits a sphere, and we need to be able to calculate it’s first and second derivative analytically ideally.
I fought with this for a bit but came up with a solution.
Here are the variables involved:
- rayPos and rayDir, both are vec3’s
- spherePos which is a vec3 and a sphereRadius which is a scalar
- t – how far down the ray we are, and is a scalar
We are going to make the sphere center be the origin by subtracting it out of the ray position (then we don’t need spherePos anymore), so then all we have to find is where the magnitude of the vector from the origin to the ray position at time t is the sphere radius. To simplify calculating the derivatives, we are going to square both sides of the equation.

If we can find where that equation is zero, that will tell us the time t that the ray hits the sphere, and we can get the actual intersected position (then normal, etc) from that.
For a 3d vector, Magnitude squared is just the below which is the distance equation without the square root.

If you expand f(t) out for just the x axis to get the pattern per axis, you get:

You would add a similar thing for y and z – but not do the sphere radius part because it’s already handled above.
We can take the derivative of the above with respect to t, to get:

So the first derivative is that equation, but also adding in the y and z axes:

That looks a bit like spaghetti but is way cleaner in code with a loop iteration for each axis 😛
We can then take the derivative of that first derivative to get the second derivative (still, with respect to t). That gives us this:

Ok cool, now that we have our equations, I used (0,0,0) for the ray position, (0,0,1) for the ray direction, (0.2, 0.3, 5.0) for the sphere position, and a sphere radius of 2.0.
Let’s see how our methods did at finding the intersection time of the ray vs the sphere.
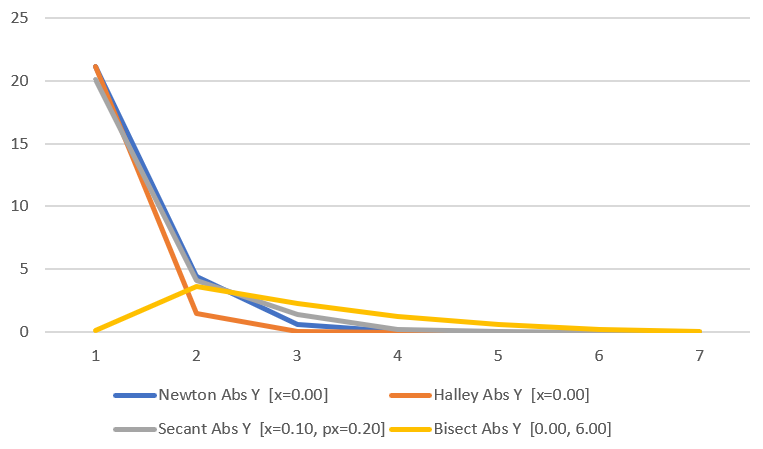
Once again, Halley wins, newton comes in second, then secant, then bisect. Neat!
Finding Function Mins & Maxes
For being one of the headlines of the blog post title, this is actually a really simple thing to explain now that you know the rest.
The minimum and maximum of a function – by definition! – has a derivative (slope) of zero, because it’s right where the function goes flat. The function has either climbed to the top of a mountain, gone flat, and is heading back down, or it has gone to the bottom of a valley, gone flat, and is heading back up. There is actually also a third option called a saddlepoint where it is pausing it’s ascent or descent momentarily and then continues.
In any case, to find the minimum or maximum of a function, we need to find where it’s derivative is zero. We do this by doing root finding on it’s first derivative.
From there, we can plug that x value found into the original f(x) function to get our extrema value.
The code that goes with this blog post uses this technique to find the maximum value for the function 
It finds that the derivative (

Links
The code that goes with this blog post can be found at: https://github.com/Atrix256/BasicRootFinding
A good 10 minute video on Newton’s Method
Here’s a way to get an analytic derivative of a function without having to do it symbolically. Dual numbers are a form of automatic differentiation, just like backpropagation is.
https://blog.demofox.org/2014/12/30/dual-numbers-automatic-differentiation/
You can extend this stuff to higher dimensions using the gradient instead of the derivative, and maybe a Jacobian matrix or Hesian matrix for higher derivatives. That might make a good future blog post.
We actually do something similar to Newton’s method when doing sphere tracing (ray marching with a distance estimate). We divide the distance value at a point in space (the y value, or f(x)) by the length of the gradient (which is basically the slope aka generalized derivative) to know that a surface can’t be any closer than that value, so we can step that length in whatever direction our ray wants to move. This also has applications to drawing 2d graphics. You can read about that here:
https://www.iquilezles.org/www/articles/distance/distance.htm