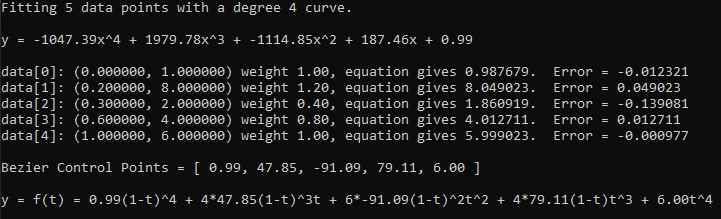
This post will first talk about how to do equality constraints in least squares curve fitting before showing how to fit multiple piecewise curves to a single set of data. The equality constraints will be used to be able to make the curves c0 continuous, c1 continuous, or higher continuity, as desired.
Point Constraints
The previous blog post (https://blog.demofox.org/2022/06/06/fitting-data-points-with-weighted-least-squares/) showed how to give weights to points that were fit with least squares. If you want a curve to pass through a specific point, you could add it to the list of points to fit to, but give it a very large weighting compared to the other points, such as a weight of 1000, when the others have a weight of 1.
There is a more direct way to force a curve to go through a point though. I’ll link to some resources giving the derivation details at the end of the post, but for now I’ll just show how to do it.
For ordinary least squares, when making the augmented matrix to solve the system of linear equations it looks like this:

You can use Gauss Jordan Elimination to solve it for instance (more on that here: https://blog.demofox.org/2017/04/10/solving-n-equations-and-n-unknowns-the-fine-print-gauss-jordan-elimination/)
Doing that solves for c in the equation below, where c is the vector of coefficients of the polynomial that minimizes the sum of squared error for all of the points.
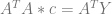
For weighted least squares it became this:

Which again solves for c in the equation below:

If you want to add an equality constraint to this, you make a vector C and a scalar value Z. The vector C is the values you multiply the polynomial coefficients by, and Z is the value you want to get out when you do that multiplication. You can add multiple rows, so C can be a matrix, but it needs to have as many columns as the 
![\left[\begin{array}{rr|r} A^TWA & C^T & A^TWY \\ C & 0 & Z \end{array}\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B%5Cbegin%7Barray%7D%7Brr%7Cr%7D+A%5ETWA+%26+C%5ET+%26+A%5ETWY+%5C%5C+C+%26+0+%26+Z+%5Cend%7Barray%7D%5Cright%5D&bg=ffffff&fg=666666&s=0&c=20201002)
When solving that and getting the coefficients out, you can ignore the extra values on the right where 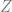
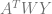
Let’s see an example of a point constraint for a linear equation.
A linear equation is 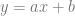
in our case, our equation is more generalized into 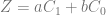


To make a point constraint, we set 
So, more specifically, if we wanted a linear fit to pass through the point (2, 4), our C vector would be ![[1, 2]](https://s0.wp.com/latex.php?latex=%5B1%2C+2%5D&bg=ffffff&fg=666666&s=0&c=20201002)
If we wanted to give the same point constraint to a quadratic function, the C vector would be ![[1, 2, 4]](https://s0.wp.com/latex.php?latex=%5B1%2C+2%2C+4%5D&bg=ffffff&fg=666666&s=0&c=20201002)
For a cubic, the C vector would be ![[1, 2, 4, 8]](https://s0.wp.com/latex.php?latex=%5B1%2C+2%2C+4%2C+8%5D&bg=ffffff&fg=666666&s=0&c=20201002)
If you wanted to constrain a quadratic function to 2 specific points (2,4) and (3, 2), C would become a matrix and would be:

Z would become a vector and would be 
Hopefully makes sense.
There are limitations on the constraints you can give, based on the hard limitations of mathematics. For instance, you can’t tell a linear fit that it has to pass through 3 non colinear points.
Point Constraints vs Weights
Let’s see how weights work versus constraints. First in a linear equation where we fit a line to two points, and have a third point that starts off with a weight of 0, then goes to 1, 2, 4, and then 100. Finally we’ll show what the fit looks like with an actual constraint, instead of just a weighted point.
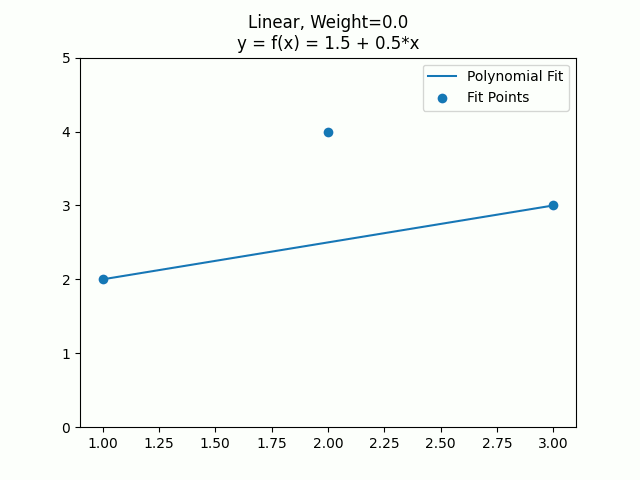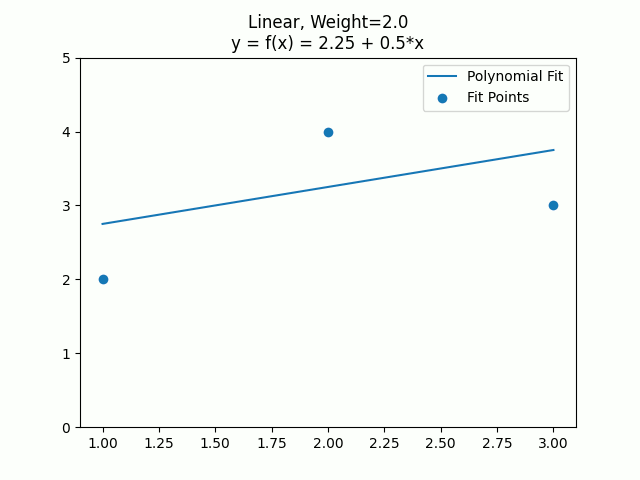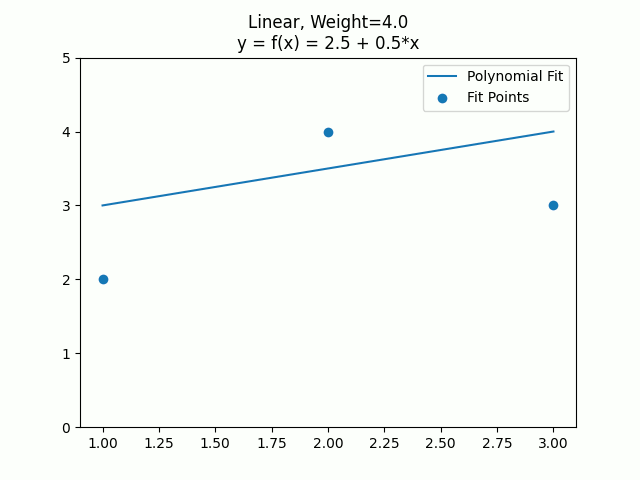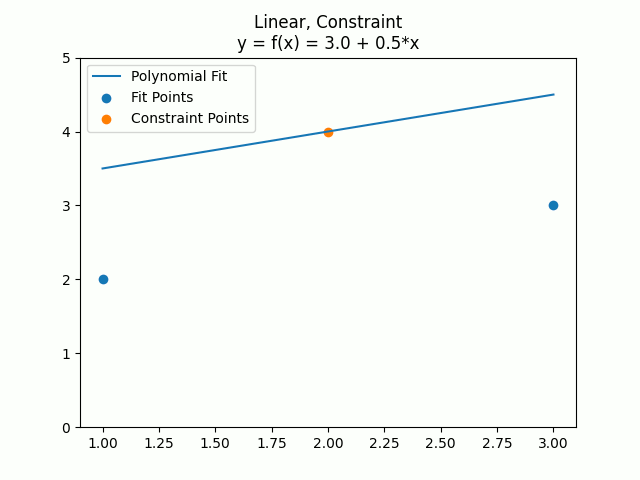
Here is the same with a quadratic curve.

The constraints let you say “This must be true” and then it does a least squares error solve for the points being fit, without violating the specified constraint. As the weight of a point becomes larger, it approaches the same effect that a constraint gives.
Derivative Constraint
A nice thing about how constraints are specified is that they aren’t limited to point constraints. You are just giving values (Z) that you want when multiplying the unknown polynomial coefficients by known values (C).
If we take the derivative of a quadratic function 
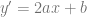
We can use this to specify that we want a specific derivative value at a specific x location. We plug the derivative we want in as the Z value, and our C constraint vector becomes ![[0, 1, 2x]](https://s0.wp.com/latex.php?latex=%5B0%2C+1%2C+2x%5D&bg=ffffff&fg=666666&s=0&c=20201002)
![[0, 1, 2]](https://s0.wp.com/latex.php?latex=%5B0%2C+1%2C+2%5D&bg=ffffff&fg=666666&s=0&c=20201002)
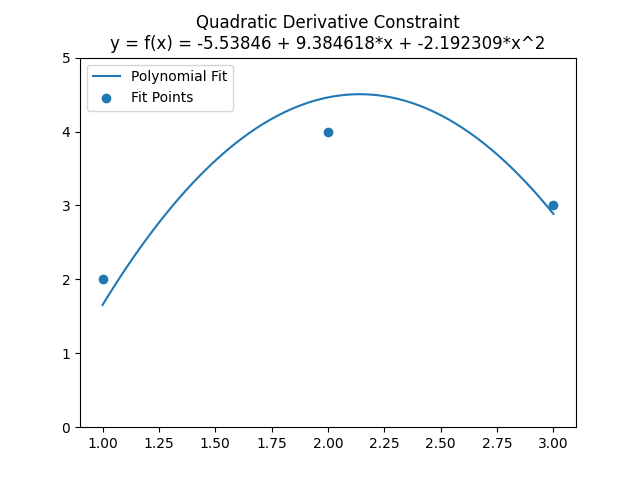
You can check the equation to verify that when x is 1, it has a slope of 5. Plugging in the coefficients and the value of 1 for x, you get 9.384618 + 2 * -2.192309 = 5.
It made sure the slope at x=1 is 5, and then did a quadratic curve fit to the points without violating that constraint, to find the minimal sum of squared errors. Pretty cool!
Piecewise Curves Without Constraints
Next, let’s see how to solve multiple piecewise curves at a time.
The first thing you do is break the data you want to fit up along the x axis into multiple groups. Each group will be fit by a curve independently, as if you did an independent curve fit for each group independently. We’ll put them all into one matrix though so that later on we can use constraints to make them connect to each other.
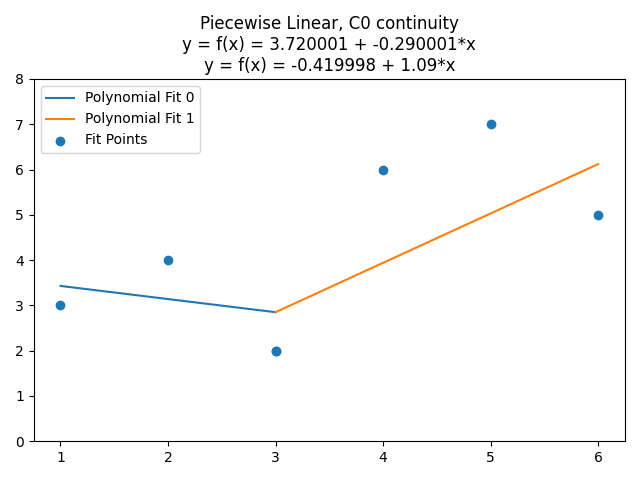
Let’s say that we have 6 points (1,3), (2,4), (3,2), (4, 6), (5,7), (6,5), and that we want to fit them with two linear curves. The first curve will fit the data points where x <= 3, and the second curve will fit the data points where x > 3. If we did that as described, there’d be a gap between the 3rd and 4th point though, so we’ll duplicate the (3,2) point, so that it can be the end of the first curve, and the start of the second curve.
For handling multiple curves, we change what is in the A matrix. Normally for a linear fit of 7 points, this matrix would be 2 columns and 7 rows. The first column would be x^0 for each data point, and the second column would be x^1 for each data point. Since we want to fit two linear curves to these 7 data points, our A matrix is instead going to be 4 columns (2 times the number of curves we want to fit) by 7 rows (the number of data points). The first 3 points use the first two columns, and the last four points use the second two columns, like this:

When we plug in the x values for our points we get:

Multiplying that A matrix by it’s transpose to get
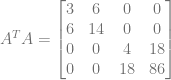
Multiplying the A matrix transposed by the y values of our points, we get:

Making that into an augmented matrix of ![[A^TA | A^TY]](https://s0.wp.com/latex.php?latex=%5BA%5ETA+%7C+A%5ETY%5D&bg=ffffff&fg=666666&s=0&c=20201002)

The top two coefficients are for the points where x <= 3, and the bottom two coefficients are for the points where x > 3.
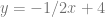


Piecewise Curves With Constraints
If we wanted those lines to touch at x=3 instead of being disjoint, we can do that with a constraint!
First remember we are solving for two sets of linear equation coefficients, which we’ll call 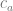
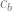
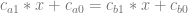
now we plug in 3 for x, and we’ll add an explicit multiplication by 1 to the constant terms:
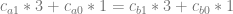
Now we move the right side equation over to the left side:

We can now turn this into a constraint vector C and a value Z! When making the C vector, keep in mind that it goes constant term, then x1 term for the first curve, then constant term, then x1 term for the second curve. That gives us:
![C = [1, 3, -1, -3]](https://s0.wp.com/latex.php?latex=C+%3D+%5B1%2C+3%2C+-1%2C+-3%5D&bg=ffffff&fg=666666&s=0&c=20201002)
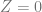
This constraint says “I don’t care what the value of Y is when X is 3, but they should be equal to each other in both linear curves we are fitting”.
Even though the contents of our A matrix changed, the formulation for including equality constraints remains the same:
If you plug this in and solve it, you get this:
We can take this farther, and make it so the derivative at x=3 also has to match to make it C1 continuous. For a line with an equation of 
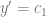
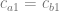

As a constraint vector, this gives us:
![C = [0, 1, 0, -1]](https://s0.wp.com/latex.php?latex=C+%3D+%5B0%2C+1%2C+0%2C+-1%5D&bg=ffffff&fg=666666&s=0&c=20201002)
If we put both constraints in… that the y value must match at x=3 and also that the slope must match at x=3, we get this, which isn’t very interesting:

Since you can define a linear function as a point on the line and a slope, and we have a “must do this” constraint on both a specific point (y matches when x=3) and a slope (the slopes of the lines need to match), it came up with the same line for both parts. We’ve jumped through a lot of extra hoops to fit a single line to our data points. (Note that it is possible to say the slopes need to match and don’t say anything about the lines needing to have a matching y value. You’d get two parallel lines that fit their data points as well as they could, and would not be touching).
This gets more interesting though if we do a higher degree fit. let’s first fit the data points with two quadratic functions, with no continuity constraints. It looks like they are already C0 continuous, by random chance of the points I’ve picked, but they aren’t. Equation 1 gives y=1.999998 for x=3, while equation 2 gives 2.000089. They are remarkably close, but they are not equal.

Changing it to be C0 continuous doesn’t really change it very much, so let’s skip straight to C1 continuity (which also has the C0 constraint). Remembering that the derivative of a quadratic
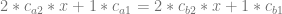


That makes our constraint be:
![C = [0, 1, 6, 0, -1, -6]](https://s0.wp.com/latex.php?latex=C+%3D+%5B0%2C+1%2C+6%2C+0%2C+-1%2C+-6%5D&bg=ffffff&fg=666666&s=0&c=20201002)
Plugging that in and solving, we get this very tasty fit, where the quadratic curves are C1 continuous at x=3, but otherwise are optimized to minimize the sum of the squared error of the data points:
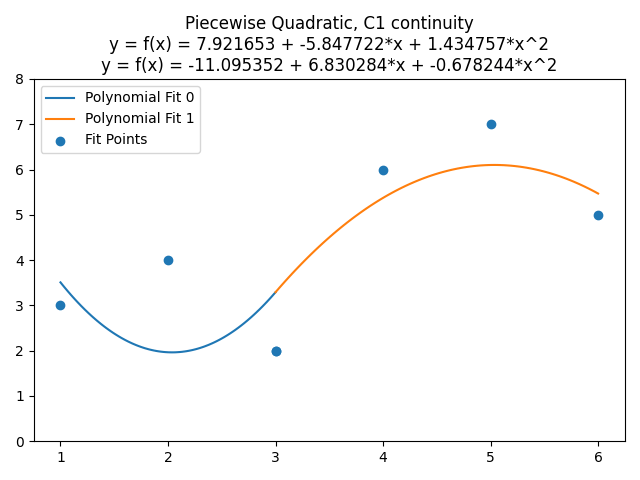
An Oddity
I wanted to take OLS to a non matrix algebra form to see if I could get any better intuition for why it worked.
What I did was plug the symbols into the augmented matrix, did Gauss Jordan elimination with the symbols, and then looked at the resulting equations to see if they made any sense from that perspective.
Well, when doing a constant function fit like 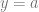

This makes a lot of sense intuitively, since the sum of x values to the 0th power is just the number of points of data. That makes 
Moving onto a linear fit 
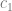

What’s strange about this formula, is that it ALMOST looks like the covariance of x and y, divided by the covariance of x and x (aka the variance of x). Which, that kinda does look like a slope / derivative: rise over run. It isn’t exactly covariance though, which divides by the number of points to get EXPECTED values, instead of sums.
Then, the 

It again ALMOST makes sense to me, in that we have the expected value of y for the constant term, like we did in the constant function, but then we need to account for the
This almost makes sense but not quite. I don’t think taking it up to quadratic would make it make more sense at this point, so I left it at that.
If you have any insights or intuition, I’d love to hear them! (hit me up at https://twitter.com/Atrix256)
Closing
The simple standalone C++ code that goes with this post, which made all the data for the graphs, and the python script that graphed them, can be found at https://github.com/Atrix256/PiecewiseLeastSquares.
A nice, more formal description of constrained least squares can be found at http://www.seas.ucla.edu/~vandenbe/133A/lectures/cls.pdf.
Here is another nice one by https://twitter.com/sandwichmaker : https://blog.demofox.org/wp-content/uploads/2022/06/constrained_point_fitting.pdf
Here is a nice read about how to determine where to put the breaks of piecewise fits, and how many breaks to make: https://towardsdatascience.com/piecewise-linear-regression-model-what-is-it-and-when-can-we-use-it-93286cfee452
Thanks for reading!
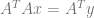
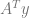 .
.![\left[\begin{array}{r|r} A^TA & A^Ty \end{array}\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B%5Cbegin%7Barray%7D%7Br%7Cr%7D+A%5ETA+%26+A%5ETy+%5Cend%7Barray%7D%5Cright%5D+&bg=ffffff&fg=666666&s=0&c=20201002)
![\left[\begin{array}{r|r} I & x \end{array}\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B%5Cbegin%7Barray%7D%7Br%7Cr%7D+I+%26+x+%5Cend%7Barray%7D%5Cright%5D+&bg=ffffff&fg=666666&s=0&c=20201002)
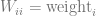 .
.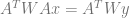
![\left[\begin{array}{r|r} A^TWA & A^TWy \end{array}\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B%5Cbegin%7Barray%7D%7Br%7Cr%7D+A%5ETWA+%26+A%5ETWy+%5Cend%7Barray%7D%5Cright%5D+&bg=ffffff&fg=666666&s=0&c=20201002)
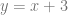 . It’s interesting to see that data points 0 and 2 each have an error of +3 while data point 1 has an error of -6.
. It’s interesting to see that data points 0 and 2 each have an error of +3 while data point 1 has an error of -6.