
In this post we are going to explore two things:
- Learn how to easily be able to expand
for ANY value
using the binomial theorem (well, N has to be a positive integer…)
- Use that for coming up with the equation for a Bezier curve of any degree (any number of control points)
Binomial Theorem
The binomial theorem is a way of easily expanding
Let’s check out how the values look when
|
Expanded |
| 1 |  |
| 2 |  |
| 3 |  |
To help make the patterns more visible, let’s make things a bit more explicit:
|
Expanded |
| 1 | 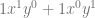 |
| 2 | 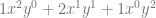 |
| 3 | 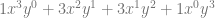 |
The easiest pattern to see is that there are N+1 terms.
The next pattern that might jump out at you looking at the above table, is that in the first term, y starts out at power 0, and the next term has a power of 1, and the power of y keeps increasing by 1 for each term left to right until we run out of terms. Similarly, x starts out at a power of 0 on the last term, has a power of 1 on the second last term, and counts up going from right to left, until we run out of terms.
Those patterns explain how many terms there are and the powers of x and y for each term. There is one piece left of the puzzle though, which is those constants that each term is multiplied by.
Those constants are called the “binomial coefficients” and they also appear as rows on pascal’s triangle. In short, each number in pascal’s triangle is a sum of the numbers directly above it. Below is an image to show what I’m talking about. Check the links section at the end for more detailed info.

So if you notice, the 2nd row of pascal’s triangle is “1,1”. Those are the constants multiplied by each term for the 


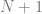
There are algorithms for calculating the
TADA! That is the binomial theorem.
Bezier Curve Equation Generalized (Again)
You may remember that I previously showed you a generalized way to get the equation for a bezier curve of any order in Bezier Curves Part 2 (and Bezier Surfaces).
It wasn’t too difficult, but it DID require you to manually expand
What you do is evaluate 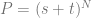


Boom, you are done, that’s all!
Here’s the quadratic (N=2) version to see the end result:

Formalized Mathematical Description
The above makes a lot of sense and is easy to understand, wouldn’t it be neat if math could describe it that way?
Well… it turns out it can, and does. Here is the formal “explicit definition” of bezier curves:

If you remember from above, s is the same as (1-t) so you could also write it like this:

The 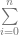
The 
The next part 
Lastly comes 
So, to sum it all up, it’s saying to make a for loop from 0 to n where you are going to add up the results of each for loop. For each loop iteration, where i is the index variation of the loop, you are going to:
- Start with the ith item from the (n+1)th row of pascals triangle
- Multiply that by s^(n-i)t^i
- Multiply that by a unique control point
There ya go, formalized math descriptions with crazy symbols can actually mean something useful. Who would have thought?!
Here is the quadratic bezier curve again for you to look at (quadratic means n = 2), in a form that will help you when thinking about the steps above:
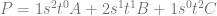
And when it’s cleaned up, it looks more familiar:
Example Code
#include <stdio.h>
#include <vector>
//=====================================================================================
void WaitForEnter ()
{
printf("nPress Enter to quit");
fflush(stdin);
getchar();
}
//=====================================================================================
std::vector<unsigned int> PascalsTriangleRow(int row)
{
std::vector<unsigned int> ret;
ret.push_back(1);
for (int i = 0; i < row; ++i)
ret.push_back(ret[i] * (row - i) / (i + 1));
return ret;
}
//=====================================================================================
void main(void)
{
printf("Expand (x+y)^N and give Bezier curve order NnnPlease enter N:n");
unsigned int N;
// keeping it limited to a sane value. also protects against -1 being huge.
// Also, so we don't run out of letters for control points!
if (scanf("%u",&N)==1 && N < 26)
{
auto row = PascalsTriangleRow(N);
// binomial expansion
printf("nBinomial Expansion:n");
if (N == 0)
{
printf("1");
}
else
{
for (unsigned int i = 0, c = row.size(); i < c; ++i)
{
if (i > 0)
printf(" + ");
if (row[i] != 1)
printf("%u", row[i]);
unsigned int xPow = N - i;
if (xPow > 0)
{
printf("x");
if (xPow > 1)
printf("^%i", xPow);
}
unsigned int yPow = i;
if (yPow > 0)
{
printf("y");
if (yPow > 1)
printf("^%i", yPow);
}
}
}
// bezier curves
printf("nnBezier Curve Order %u:nP = ", N);
if (N == 0)
{
printf("A");
}
else
{
for (unsigned int i = 0, c = row.size(); i < c; ++i)
{
if (i > 0)
printf(" + ");
// control point name
printf("%c*",'A'+i);
if (row[i] != 1)
printf("%u", row[i]);
unsigned int sPow = N - i;
if (sPow > 0)
{
printf("s");
if (sPow > 1)
printf("^%i", sPow);
}
unsigned int tPow = i;
if (tPow > 0)
{
printf("t");
if (tPow > 1)
printf("^%i", tPow);
}
}
}
// bezier curves
printf("nnOr:nP = ", N);
if (N == 0)
{
printf("A");
}
else
{
for (unsigned int i = 0, c = row.size(); i < c; ++i)
{
if (i > 0)
printf(" + ");
// control point name
printf("%c*",'A'+i);
if (row[i] != 1)
printf("%u", row[i]);
unsigned int sPow = N - i;
if (sPow > 0)
{
printf("(1-t)");
if (sPow > 1)
printf("^%i", sPow);
}
unsigned int tPow = i;
if (tPow > 0)
{
printf("t");
if (tPow > 1)
printf("^%i", tPow);
}
}
}
printf("n");
}
else
{
printf("Invalid value for Nn");
}
WaitForEnter();
}
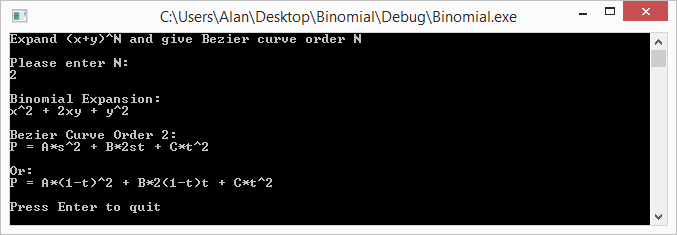
Example Output
Here are some runs of the program




Links
Note that even though we talked about binomials, and bezier curves, these techniques can be expanded to trinomials and bezier triangles – and beyond! (hint: there is such thing as Pascal’s pyramid!)
Here are some links to more info about some of the topics talked about above:
Wikipedia: Binomial Theorem
Wikipedia: Pascal’s Triangle
Wikipedia: Binomial Coefficient
StackOverflow: How to efficiently calculate a row in pascal’s triangle?
