This post is on something called Shamir’s Secret Sharing. It’s a technique where you can break a secret number up into 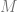
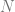
Thinking of it in video game terms, imagine there are 10 keys hidden in a level, but you can escape the level whenever you find any 7 of them. This is what Shamir’s Secret Sharing enables you to set up cryptographically.
Interestingly in this case, the term sharing in “secret sharing” doesn’t mean sharing the secret with others. It means breaking the secret up into pieces, or SHARES. Secret sharing means that you make shares out of a secret, such that if you have enough of the shares, you can recover the secret.
How Do You Share (Split) The Secret?
The basic idea of how it works is actually really simple. This is good for us trying to learn the technique, but also good to show it’s security since there are so few moving parts.
It relies on something called the Unisolvence Theorem which is a fancy label meaning these things:
- If you have a linear equation, it takes two (x,y) points to uniquely identify that line. No matter how you write a linear equation, if it passes through those same two points, it’s mathematically equivelant.
- If you have a quadratic equation, it takes three (x,y) points to uniquely identify that quadratic curve. Again, no matter how you write a quadratic equation, if it passes through those same three points, it’s mathematically equivalent.
- The pattern continues for equations of any degree. Cubic equations require four points to be uniquely identified, Quartic equations require five points, and so on.
At a high level, how this technique works is that the number of shares (keys) you want someone to collect (
You use random numbers as the coefficients of the powers of 
You then create 
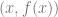
As soon as any one person has
The secret number is the constant term of the polynomial, which is also just 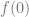
This image below from wikipedia is great for seeing how you may have two points of a cubic curve, but without a third point you can’t be sure what the quadratic equation is. In fact, there are an infinite number of quadratic curves that pass through any two points! Because of that, it takes the full number of required shares for you to be able to unlock the secret.

Example: Sharing (Splitting) The Secret
First you decide how many shares you want it to take to unlock the secret. This determines the degree of your equation.
Let’s say you wanted a person to have to have four shares to unlock the secret. This means our equation will be a cubic equation, since it takes four points to uniquely define a cubic equation.
Our equation is:

Where the 

Let’s say that our secret value is 435, and that we picked some random numbers for the equation, making the below:
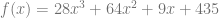
We now have a function that is uniquely identifiable by any 4 points of data on it’s curve.
Next we decide how many pieces we are going to create total. We need at least 4 so that it is in fact solvable. Let’s make 6 shares.
To do this, you just plug in 6 different values of x and pair each x value with it’s y value. Let’s do that:

When doing this part, remember that the secret number is
You could then distribute the shares (data pairs) as you saw fit. Maybe some people are more important, so you give them more than one share, requiring a smaller amount of cooperation with them to unlock the secret.
Share distribution details are totally up to you, but we now have our shares, whereby if you have any of the 4 of the 6 total shares, you can unlock the secret.
How Do You Join The Secret?
Once you have the right number of shares and you know the degree of the polynomial (pre-shared “public” information), unlocking the secret is a pretty straightforward process too. To unlock the secret, you just need to use ANY method available for creating an equation of the correct degree from a set of data points.
This can be one of several different interpolation techniques, but the most common one to use seems to be Lagrange interpolation, which is something I previously wrote up that you can read about here: Lagrange Interpolation.
Once you have the equation, you can either evaluate
Example: Joining the Secret
Let’s say that we have these four shares and are ready to get the cubic function and then unlock the secret number:

We could bust out some Lagrange interpolation and figure this out, but let’s be lazy… err efficient I mean. Wolfram alpha can do this for us!
Wolfram Alpha: cubic fit (1, 536), (2, 933), (4, 3287), (6, 8841)
That gives us this equation, saying that it is a perfect fit (which it is!)

You can see that our constant term (and
Daaaayummm Bru… that is lit AF! We just got hacked by wolfram alpha 😛
A Small Complication
Unfortunately, the above has a weakness. The weakness is that each share you get gives you a little bit more information about the secret value. You can read more about this in the links section at the end if you want to know more details.
Ideally, you wouldn’t have any information about the secret value until you had the full number of shares required to unlock the secret.
To address this problem, we are going to choose some prime number 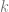
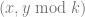
The value we choose for
If you want to use this technique in a situation which has real needs for security, please make sure and read more on this technique from more authoritative sources. I’m glossing over the details of security quite a bit, and just trying to give an intuitive understanding of this technique (:
Source Code
Below is some sample source code that implements Shamir’s Secret Sharing in C++.
I use 64 bit integers, but if you were going to be using this in a realistic situation you could very well overflow 64 bit ints and get the wrong answers. I hit this problem for instance when trying to require more than about 10 shares, using a prime of 257, and generating 50 shares. If you hit the limit of 64 bit ints you can use a multi precision math library instead to have virtually unlimited sized ints. The boost multiprecision header library is a decent choice for multi precision integers, specifically cpp_int.
#include <stdio.h>
#include <array>
#include <vector>
#include <math.h>
#include <random>
#include <assert.h>
#include <stdint.h>
#include <inttypes.h>
typedef int64_t TINT;
typedef std::array<TINT, 2> TShare;
typedef std::vector<TShare> TShares;
class CShamirSecretSharing
{
public:
CShamirSecretSharing (size_t sharesNeeded, TINT prime)
: c_sharesNeeded(sharesNeeded), c_prime(prime)
{
// There needs to be at least 1 share needed
assert(sharesNeeded > 0);
}
// Generate N shares for a secretNumber
TShares GenerateShares (TINT secretNumber, TINT numShares) const
{
// calculate our curve coefficients
std::vector<TINT> coefficients;
{
// store the secret number as the first coefficient;
coefficients.resize((size_t)c_sharesNeeded);
coefficients[0] = secretNumber;
// randomize the rest of the coefficients
std::array<int, std::mt19937::state_size> seed_data;
std::random_device r;
std::generate_n(seed_data.data(), seed_data.size(), std::ref(r));
std::seed_seq seq(std::begin(seed_data), std::end(seed_data));
std::mt19937 gen(seq);
std::uniform_int_distribution<TINT> dis(1, c_prime - 1);
for (TINT i = 1; i < c_sharesNeeded; ++i)
coefficients[(size_t)i] = dis(gen);
}
// generate the shares
TShares shares;
shares.resize((size_t)numShares);
for (size_t i = 0; i < numShares; ++i)
shares[i] = GenerateShare(i + 1, coefficients);
return shares;
}
// use lagrange polynomials to find f(0) of the curve, which is the secret number
TINT JoinShares (const TShares& shares) const
{
// make sure there is at elast the minimum number of shares
assert(shares.size() >= size_t(c_sharesNeeded));
// Sigma summation loop
TINT sum = 0;
for (TINT j = 0; j < c_sharesNeeded; ++j)
{
TINT y_j = shares[(size_t)j][1];
TINT numerator = 1;
TINT denominator = 1;
// Pi product loop
for (TINT m = 0; m < c_sharesNeeded; ++m)
{
if (m == j)
continue;
numerator = (numerator * shares[(size_t)m][0]) % c_prime;
denominator = (denominator * (shares[(size_t)m][0] - shares[(size_t)j][0])) % c_prime;
}
sum = (c_prime + sum + y_j * numerator * modInverse(denominator, c_prime)) % c_prime;
}
return sum;
}
const TINT GetPrime () const { return c_prime; }
const TINT GetSharesNeeded () const { return c_sharesNeeded; }
private:
// Generate a single share in the form of (x, f(x))
TShare GenerateShare (TINT x, const std::vector<TINT>& coefficients) const
{
TINT xpow = x;
TINT y = coefficients[0];
for (TINT i = 1; i < c_sharesNeeded; ++i) {
y += coefficients[(size_t)i] * xpow;
xpow *= x;
}
return{ x, y % c_prime };
}
// Gives the decomposition of the gcd of a and b. Returns [x,y,z] such that x = gcd(a,b) and y*a + z*b = x
static const std::array<TINT, 3> gcdD (TINT a, TINT b) {
if (b == 0)
return{ a, 1, 0 };
const TINT n = a / b;
const TINT c = a % b;
const std::array<TINT, 3> r = gcdD(b, c);
return{ r[0], r[2], r[1] - r[2] * n };
}
// Gives the multiplicative inverse of k mod prime. In other words (k * modInverse(k)) % prime = 1 for all prime > k >= 1
static TINT modInverse (TINT k, TINT prime) {
k = k % prime;
TINT r = (k < 0) ? -gcdD(prime, -k)[2] : gcdD(prime, k)[2];
return (prime + r) % prime;
}
private:
// Publically known information
const TINT c_prime;
const TINT c_sharesNeeded;
};
void WaitForEnter ()
{
printf("Press Enter to quit");
fflush(stdin);
getchar();
}
int main (int argc, char **argv)
{
// Parameters
const TINT c_secretNumber = 435;
const TINT c_sharesNeeded = 7;
const TINT c_sharesMade = 50;
const TINT c_prime = 439; // must be a prime number larger than the other three numbers above
// set up a secret sharing object with the public information
CShamirSecretSharing secretSharer(c_sharesNeeded, c_prime);
// split a secret value into multiple shares
TShares shares = secretSharer.GenerateShares(c_secretNumber, c_sharesMade);
// shuffle the shares, so it's random which ones are used to join
std::array<int, std::mt19937::state_size> seed_data;
std::random_device r;
std::generate_n(seed_data.data(), seed_data.size(), std::ref(r));
std::seed_seq seq(std::begin(seed_data), std::end(seed_data));
std::mt19937 gen(seq);
std::shuffle(shares.begin(), shares.end(), gen);
// join the shares
TINT joinedSecret = secretSharer.JoinShares(shares);
// show the public information and the secrets being joined
printf("%" PRId64 " shares needed, %i shares maden", secretSharer.GetSharesNeeded(), shares.size());
printf("Prime = %" PRId64 "nn", secretSharer.GetPrime());
for (TINT i = 0, c = secretSharer.GetSharesNeeded(); i < c; ++i)
printf("Share %" PRId64 " = (%" PRId64 ", %" PRId64 ")n", i+1, shares[i][0], shares[i][1]);
// show the result
printf("nJoined Secret = %" PRId64 "nActual Secret = %" PRId64 "nn", joinedSecret, c_secretNumber);
assert(joinedSecret == c_secretNumber);
WaitForEnter();
return 0;
}
Example Output
Here is some example output of the program:
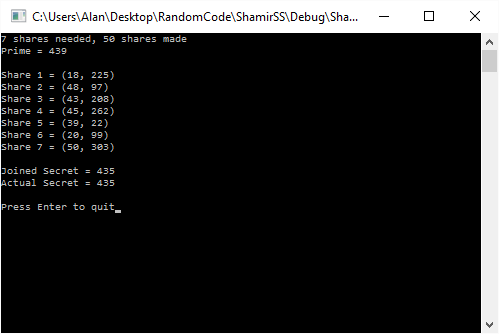
Links
Wikipedia: Shamir’s Secret Sharing (Note: for some reason the example javascript implementation here only worked for odd numbered keys required)
Wikipedia: Finite Field
Cryptography.wikia.com: Shamir’s Secret Sharing
Java Implementation of Shamir’s Secret Sharing (Note: I don’t think this implementation is correct, and neither is the one that someone posted to correct them!)
When writing this post I wondered if maybe you could use the coefficients of the other terms as secrets as well. These two links talk about the details of that:
Cryptography Stack Exchange: Why only one secret value with Shamir’s secret sharing?
Cryptography Stack Exchange: Coefficients in Shamir’s Secret Sharing Scheme
Now that you understand this, you are probably ready to start reading up on elliptic curve cryptography. Give this link below a read if you are interested in a gentle introduction on that!
A (Relatively Easy To Understand) Primer on Elliptic Curve Cryptography
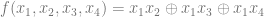




 , we just look in the truth table for function
, we just look in the truth table for function  to see if we have an odd or even number of ones in the output of the function. If there is an even number, it is 0, else it is a 1.
to see if we have an odd or even number of ones in the output of the function. If there is an even number, it is 0, else it is a 1.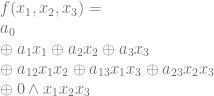
 is the symbol for AND. I’m showing it explicitly because otherwise the equation looks weird, and a multiplication symbol isn’t correct.
is the symbol for AND. I’m showing it explicitly because otherwise the equation looks weird, and a multiplication symbol isn’t correct.
 , we need to limit our truth table to
, we need to limit our truth table to 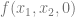 . That truth table is below, made from the original truth table, but throwing out any row where
. That truth table is below, made from the original truth table, but throwing out any row where 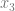 is 1.
is 1.

 , we find that it also has an even number of ones, making
, we find that it also has an even number of ones, making  become 0 and making that term disappear.
become 0 and making that term disappear. , it also has an even number of ones, making
, it also has an even number of ones, making 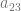 become 0 and making that term disappear as well.
become 0 and making that term disappear as well.
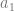 , we look at the truth table for
, we look at the truth table for 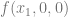 , which is below:
, which is below:
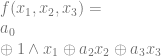

 and
and  , you’ll find that they also have odd numbers of ones in the output so also become ones. That puts our equation at:
, you’ll find that they also have odd numbers of ones in the output so also become ones. That puts our equation at: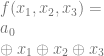
 , is just looking at whether there are an odd or even number of ones in the function
, is just looking at whether there are an odd or even number of ones in the function  which you can look up directly in the lookup table. It’s even, so
which you can look up directly in the lookup table. It’s even, so