
I was recently looking at the formula for bezier curves:
Quadratic Bezier curve:
A * (1-T)^2 + B * 2 * (1-T) * T + C * T ^2
Cubic Bezier curve:
A*(1-T)^3+3*B*(1-T)^2*T+3*C*(1-T)*T^2+D*T^3
(more info available at Bezier Curves Part 2 (and Bezier Surfaces))
And I wondered… since you can have a Bezier curve in any dimension, what would happen if you made the control points (A,B,C,D) scalar? In other words, what would happen if you made bezier curves 1 dimensional?
Well it turns out something pretty interesting happens. If you replace T with x, you end up with f(x) functions, like the below:
Quadratic Bezier curve:
y = A * (1-x)^2 + B * 2 * (1-x) * x + C * x ^2
Cubic Bezier curve:
y = A*(1-x)^3+3*B*(1-x)^2*x+3*C*(1-x)*x^2+D*x^3
What makes that so interesting is that most math operations you may want to do on a bezier curve are a lot easier using y=f(x), instead of the parameterized formula Point = F(S,T).
For instance, try to calculate where a line segment intersects with a parameterized bezier curve, and then try it again with a quadratic equation. Or, try calculating the indefinite integral of the parameterized curve so that you can find the area underneath it (like, for Analytic Fog Density). Or, try to even find the given Y location that the curve has for a specific X value. These things are pretty difficult with a parameterized function, but a lot easier with the y=f(x) style function.
This ease of use does come at a price though. Specifically, you can’t move control points freely, you can only move them up and down and cannot move them left and right. If you are ok with that trade off, these 1 dimensional curves can be pretty powerful.
Below is an image of a 1 dimensional cubic bezier curve that has control points A = 0.5 B = 0.25 C = 0.75 D = 0.5. The function of this curve is y = 0.5 * (1-x)^3 + 0.25 * 3x(1-x)^2 + 0.75 * 3x^2(1-x) + 0.5 * x^3.
You can ask google to graph that for you to see that it is in fact the same: Google: graph y = 0.5 * (1-x)^3 + 0.25 * 3x(1-x)^2 + 0.75 * 3x^2(1-x) + 0.5 * x^3
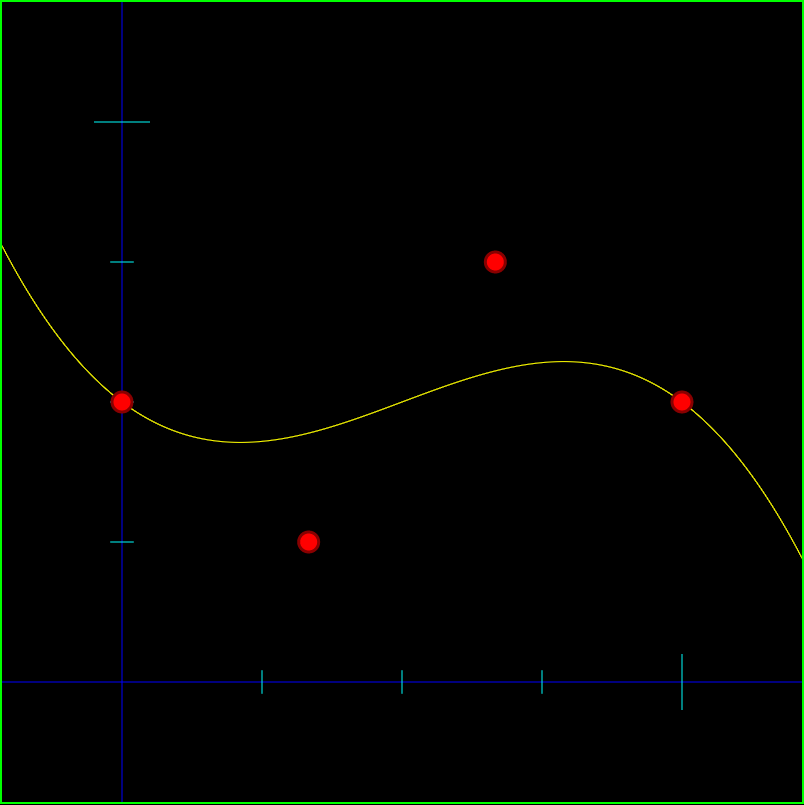
Another benefit to these one dimensional bezier curves is that you could kind of use them as a “curve fitting” method. If you have some data that you wanted to approximate with a quadratic function, you could adjust the control points of a one dimensional quadratic Bezier curve to match your data set. If you need more control points to get a better aproximation of the data, you can just increase the degree of the bezier curve (check this out for more info on how to do that: Bezier Curves Part 2 (and Bezier Surfaces)).
Smoothstep as a Cubic 1d Bezier Curve
BIG THANKS to CeeJay.dk for telling me about this, this is pretty rad.
It’s kind of out of the scope of this post to talk about why smoothstep is awesome, but to give you strong evidence that it is, it’s a GLSL built in function. You may have also seen it used in the post I made about distance fields (Distance Field Textures), because one of it’s common uses is to make the edges of things look smoother. Here’s a wikipedia page on it as well if you want more info: Wikipedia: Smoothstep
Anyhow, I had no idea, but apparently the smoothstep equation is the same as if you take a 1d cubic bezier curve and make the first two control points 0, and the last two control points 1.
The equation for smoothstep is: y = 3*x^2 – 2*x^3
The equation for the bezier curve i mentioned is: y = 0*(1-x)^3+3*0*(1-x)^2*x+3*1*(1-x)*x^2+1*x^3
otherwise known as: y = 3*1*(1-x)*x^2+1*x^3
If you work it out, those are the same equations! Wolfram alpha can verify that for us even: Wolfram Alpha: does 3*x^2 – 2*x^3 = 3*1*(1-x)*x^2+1*x^3.
Kinda neat 😛
Moving Control Points on the X Axis
There’s a way you could fake moving control points on the X axis (left and right) if you really needed to. What I’m thinking is basically that you could scale X before you plug it into the equation.
For instance, if you moved the last control point to the left so that it was at 0.9 instead of 1.0, the space between the 3rd and 4th control point is now .23 instead of .33 on the x axis. You could simulate that by having some code like this:
if (x > 0.66) x = 0.66 + (x - 0.66) / 0.33 * 0.23
Basically, we are squishing the X values that are between 0.66 and 1.0 into 0.66 to 0.9. This is the x value we want to use, but we’d still plug the raw, unscaled x value into the function to get the y value for that x.
As another example, let’s say you moved the 3rd control point left from 0.66 to 0.5. In this situation, you would squish the X values that were between 0.33 and 0.66 into 0.33 to 0.5. HOWEVER, you would also need to EXPAND the values that were between 0.66 and 1.0 to be from 0.5 and 1.0. Since you only moved the 3rd control point left, you’d have to squish the section to the left of the control point, and expand the section to the right to make up the difference to keep the 4th control point in the same place. The code for converting X values is a little more complex, but not too bad.
What happens if you move the first control point left or right? Well, basically you have to expand or squish the first section, but you also need to add or subtract an offset for the x as well.
I’ll leave the last 2 conversions as an exercise for whoever might want to give this a shot 😛
Another complication that comes up with the above is, what if you tried to move the 3rd control point to the left, past the 2nd control point? Here are a couple ways I can think of off hand to deal with it, but there are probably other ways too, and the right way to deal with it depends on your needs.
- Don’t let them do it – If a control point tries to move past another control point, just prevent it from happening
- Switch the control points – If you move control point 3 to the left past control point 2, secretly have them start controling control point 2 as they drag it left. As far as the user is concerned, it’s doing what they want, but as far as we are concerned, the control points never actually crossed
- Move both – if you move control point 3 to the left past control point 2, take control point 2 along for the ride, keeping it to the left of control point 3
When allowing this fake x axis movement, it does complicate the math a bit, which might bite you depending on what you are doing with the curve. Intersecting a line segment with it for example is going to be more complex.
An alternative to this would be letting the control points move on the X axis by letting a user control a curve that controls the X axis location of the control points – hopefully this would happen behind the scenes and they would just move points in X & Y, not directly editing the curve that controls X position of control points. This is a step towards making the math simpler again, by modifying the bezier curve function, instead of requiring if statements and loops, but as far as all the possibly functions I can think of, moving one control point on the X axis is probably going to move other control points around. Also, it will probably change the shape of the graph. It might change in a reasonable way, or it might be totally unreasonable and not be a viable alternative. I’m not really sure, but maybe someday I’ll play around with it – or if you do, please post a comment back and let us know how it went for you!
Links
Here are some links to experiment with these guys and see them in action:
HTML5 Interactive 1D Quadratic Bezier Demo
HTML5 Interactive 1D Cubic Bezier Demo
Shadertoy: Interactive 1D Quadratic Bezier Demo
Shadertoy: Interactive 1D Cubic Bezier Demo









