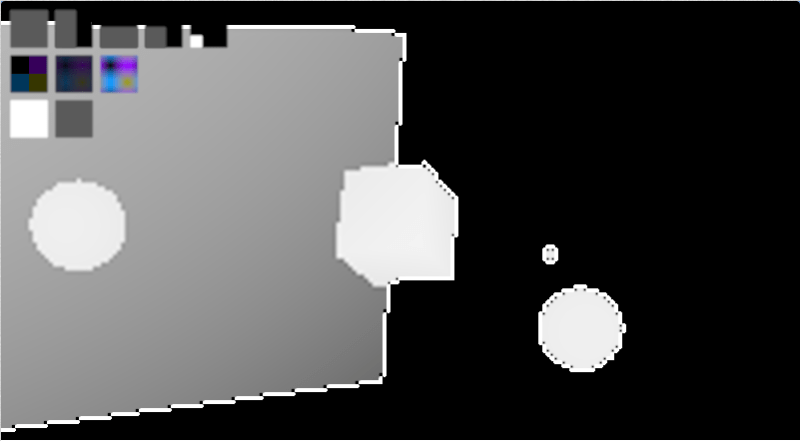
The image below is called a Voronoi diagram. The circles show you the location of the seeds and the color of each pixel represents the closest seed to that pixel. The value of this diagram is that at any point on the image, you can know which seed (point) is the closest to that pixel. It’s basically a pre-computed “closest object” map, which you can imagine some uses for I bet.

Voronoi diagrams aren’t limited to just points as seeds though, you can use any shape you want.

One way Voronoi diagrams can be useful is for path finding because they are dual to (the equivelant of) Delauny triangulation (More info at How to Use Voronoi Diagrams to Control AI).
Another way they can be useful is in generating procedural content, like in these shadertoys:
Shadertoy: Voronoi – rocks
Shadertoy: Voronoi noises
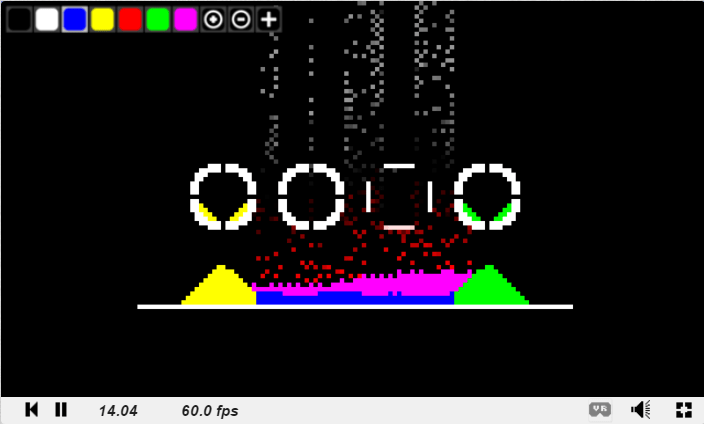
Another really cool usage case of Voronoi diagrams is in creating what is called the “Distance Transform”. The distance transform calculates and stores the distance from each pixel to the closest seed, whichever one that may be. Doing that, you may get an image like this (note that the distance is clamped at a maximum and mapped to the 0 to 1 range to make this image).

That is what is called a distance texture and can be used for a very cool technique where you have texture based images that can be zoomed into / enlarged quite a ways before breaking down and looking bad. The mustache in the image below was made with a 32×16 single channel 8bpp image for instance! (ignore the white fog, this was a screenshot from inside a project I was working on)
Distance field textures are the next best thing to vector graphics (great for scalable fonts in games, as well as decals!) and you can read about it here: blog.demofox.org: Distance Field Textures

Now that you know what Voronoi diagrams and distance transforms are used for, let’s talk about one way to generate them.
Jump Flooding Algorithm (JFA)
When you want to generate either a Voronoi diagram or a distance transform, there are algorithms which can get you the exact answer, and then there are algorithms which can get you an approximate answer and generally run a lot faster than the exact version.
The jump flooding algorithm is an algorithm to get you an approximate answer, but seems to have very little error in practice. It also runs very quickly on the GPU. It runs in constant time based on the number of seeds, because it’s execution time is based on the size of the output texture – and is based on that logarithmically.
Just a real quick note before going into JFA. If all else fails, you could use brute force to calculate both Voronoi diagrams as well as distance transforms. You would just loop through each pixel, and then for each pixel, you would loop through each seed, calculate the distance from the pixel to the seed, and just store the information for whatever seed was closest. Yes, you even do this for seed pixels. The result will be a distance of 0 to the seed 😛
Back to JFA, JFA is pretty simple to program, but understanding why it works may take a little bit of thinking.
Firstly you need to prepare the N x N texture that you want to run JFA on. It doesn’t need to be a square image but let’s make it square for the explanation. Initialize the texture with some sentinel value that means “No Data” such as (0.0, 0.0, 0.0, 0.0). You then put your seed data in. Each pixel that is a seed pixel needs to encode it’s coordinate inside of the pixel. For instance you may store the fragment coordinate bitpacked into the color channels if you have 32 bit pixels (x coordinate in r,g and y coordinate in b,a). Your texture is now initialized and ready for JFA!
JFA consists of taking log2(N) steps where each step is a full screen pixel shader pass.
In the pixel shader, you read samples from the texture in a 3×3 pattern where the middle pixel is the current fragment. The offset between each sample on each axis is 2^(log2(N) – passIndex – 1), where passIndex starts at zero.
That might be a bit hard to read so let’s work through an example.
Let’s say that you have an 8×8 texture (again, it doesn’t need to be square, or even power of 2 dimensions, but it makes it easier to explain), that has a 16 bit float per RGBA color channel. You fill the texture with (0.0, 0.0, 0.0, 0.0) meaning there is no data. Let’s say that you then fill in a few seed pixels, where the R,G channels contain the fragment coordinate of that pixel. Now it’s time to do JFA steps.
The first JFA step will be that for each pixel you read that pixel, as well as the rest of a 3×3 grid with offset 4. In total you’d read the offsets:
(-4.0, -4.0), (0.0, -4.0), (4.0, -4.0),
(-4.0, 0.0), (0.0, 0.0), (4.0, 0.0),
(-4.0, 4.0), (0.0, 4.0), (4.0, 4.0)
For each texture read you did, you calculate the distance from the seed it lists inside it (if the seed exists aka, the coordinate is not 0,0), and store the location of the closest seed int the output pixel (like, store the x,y of the seed in the r,g components of the pixel).
You then do another JFA step with offset 2, and then another JFA step with offset 1.
JFA is now done and your image will store the Voronoi diagram, that’s all! If you look at the raw texture it won’t look like anything though, so to view the Voronoi diagram, you need to make a pixel shader where it reads in the pixel value, deocdes it to get the x,y of the closest seed, and then uses that x,y somehow to generate a color (use it as a seed for a prng for instance). That color is what you would output in the pixel shader, to view the colorful Voronoi diagram.
To convert the Voronoi diagram to a distance transform, you’d do another full screen shader pass where for each pixel you’d calculate the distance from that pixel to the seed that it stores (the closest seed location) and write the distance as output. If you have a normalized texture format, you’re going to have to divide it by some constant and clamp it between 0 and 1, instead of storing the raw distance value. You now have a distance texture!
More Resources
I originally came across this algorithm on shadertoy: Shadertoy: Jump Flooding. That shadertoy was made by @paniq who is working on some pretty interesting stuff, that you can check out both on shadertoy and twitter.
The technique itself comes from this paper, which is a good read: Jump Flooding in GPU with Applications to Voronoi Diagram and Distance Transform
Extensions
While JFA as explained is a 2D algorithm, it could be used on volume textures, or higher dimensions as well. Higher dimensions mean more texture reads, but it will still work. You could render volume textures with raymarching, using the distance information as a hint for how far you could march the ray each step.
Also, I’ve played around with doing 5 reads instead of 9, doing a plus sign read instead of a 3×3 grid. In my tests it worked just as well as regular JFA, but I’m sure in more complex situations there are probably at least minor differences. Check the links section for a shadertoy implementation of this. I also tried doing a complete x axis JFA followed by a y axis JFA. That turned out to have a LOT of errors.
You can also weight the seeds of the Voronoi diagram. When you are calculating the distance from a pixel to a seed point, you use the seed weight to multiply and/or add to the distance calculated. You can imagine that perhaps not all seeds are created equal (maybe some AI should avoid something more than something else), so weighting can be used to achieve this.
Shadertoys
Here are some shadertoys I made to experiment with different aspects of this stuff. You can go check them out to see working examples of JFA in action with accompanying glsl source code.
Jump Flood Algorithm: Points – Point Seeds
Jump Flood Algorithm: Shapes – Shape Seeds
Jump Flood Algorithm: Weight Pts – Multiplicative Weighting
Jump Flood Algorithm: Add Wt Pts – Additive Weighting
Separable Axis JFA Testing – Does 5 reads instead of 9, also shows how separating axis completely fails.
Here is a really interesting shadertoy that shows a way of modifying a Vornoi diagram on the fly: Shadertoy: zoomable, stored voronoi cells