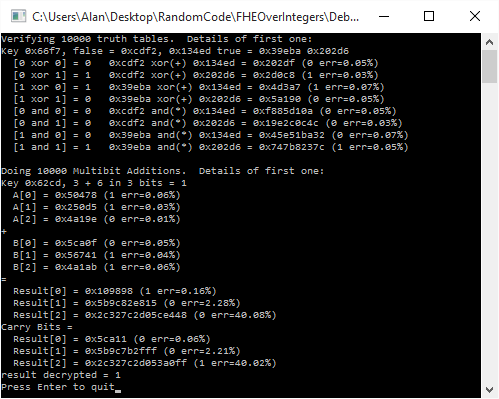
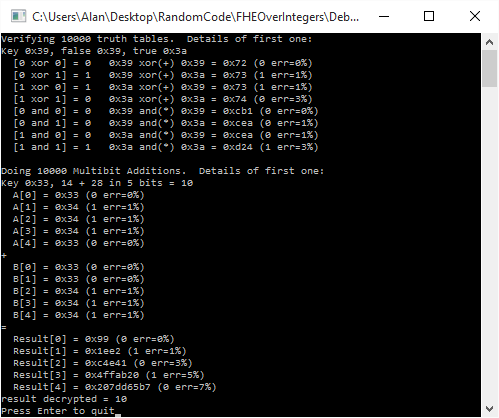
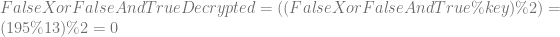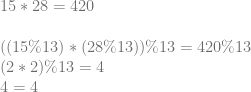Homomorphic encryption is a special type of encryption that lets you do calculations on encrypted values as if they weren’t encrypted. One reason it’s desired is that secure computing could be done in the cloud, if practical homomorphic encryption were available.
Homomorphic encryption has been a hot research topic since 2009, when Craig Gentry figured out a way to do it while working on his PhD. Since then, people have been working on making it better, faster and more efficient.
You can read more about a basic incarnation of his ideas in my blog posts:
Super Simple Symmetric Leveled Homomorphic Encryption Implementation
Improving the Security of the Super Simple Symmetric Leveled Homomorphic Encryption Implementation
This post is about a low tech type of homomorphic encryption that anyone can easily do and understand. There is also some very simple C++ that implements it.
This idea may very well be known about publically, but I’m not aware of any places that talk about it. I may just be ignorant of them though so ::shrug::
Quick Update
I’ve gotten some feedback on this article, the most often feedback being that this is obfuscation not encryption. I think that’s a fair assessment as the secret value you are trying to protect is in no way transformed, but is just hidden. This post could easily be titled Homomorphic Obfuscation, and perhaps should be.
To see other feedback and responses to this post, check out the reddit links at the bottom!
The Idea
The idea is actually super simple:
- Take the value you want to encrypt.
- Hide it in a list of a bunch of other random values, and remember where it is in the list. The position in the list is your key.
- Send this list to an untrusted party.
- They do the same calculation on every item in the list and send it back.
- Since you know which value was your secret value, you know which answer is the one you care about.
At the end of that process, you have the resulting value, and they have no idea what value was your secret value. You have done, by definition, homomorphic encryption!
There is a caveat of course… they know that your secret value was ONE of the values on the list.
Security Details
The thing here is that security is a sliding scale between resource usage (computation time, RAM, network bandwidth, etc) and security.
The list size is your security parameter in this case.
A larger list of random values means that it takes longer to transfer the data, more memory to store it, it takes longer to do the homomorphic computations, but the untrusted party is less sure about what your secret value is.
On the other hand, a shorter list is faster to transmit, easier to store, quicker to compute with, but the untrusted party has a better idea what your secret value is.
For maximal security you can just take this to the extreme – if your secret value is a 32 bit floating point number, you could make a list with all possible 2^32 floating point numbers in it, have them do the calculation and send it back. You can even do an optimization here and not even generate or send the list, but rather just have the person doing the calculations generate the full 2^32 float list, do the calculations, and send you the results.
That gets pretty big pretty fast though. That list would actually be 16 gigabytes, but the untrusted party would know almost nothing about your value, other than it can be represented by a 32 bit floating point number.
Depending on your security needs, you might be ok with shortening your list a bit to bring that number down. Making your list only be one million numbers long (999,999 random numbers and one value you actually care about), your list is only 3.8 megabytes.
Not quite as bad.
Some Interesting Abilities
Using this homomorphic encryption, like other homomorphic encryption, you can do computation involving multiple encrypted values. AKA you could multiply two encrypted values together. To do this, you are going to need to encrypt all values involved using the same key. In other words, they are going to have to be at the same index in each of their respective lists of random numbers.
Something else that is interesting is that you can also encode MULTIPLE secret values in your encrypted value list. You could have 1 secret value at index 50 and another at index 100 for instance. Doing this, you get a sort of homomorphic SIMD setup.
Homomorphic SIMD is actually a real thing in other homomorphic encryption methods as well. Check out this paper for instance:
Fully Homomorphic SIMD Operations
The only problem with homomorphic SIMD is that adding more secret values to the same encrypted list decreases the security, since there are more values in the list that you don’t want other people to know about.
You can of course also modify encrypted values by unencrypted values. You could multiply an encrypted value by 3, by multiplying every value in the list by 3.
Extending to Public Key Cryptography
If you wanted to use asymmetric key cryptography (public/private keys) instead of symmetric key cryptography, that is doable here too.
What you would do is have the public key public as per usual, and that key would be used in a public key algorithm to encrypt the index of the secret value in the random list.
Doing this, the person who has the private key would be able to receive the list and encrypted index, decrypt the index, and then get the secret value out using that index.
Sample Code Tests
The sample code only does Symmetric key encryption, and does these 3 tests:
- Encrypts two floating point numbers into a single list, SIMD style, does an operation on the encrypted values, then unencrypts and verifies the results.
- Does the same with two sets of floats (three floats in each set), to show how you can make encrypted values interact with each other. Does the operation, then unencrypts and verifies the results.
- Encrypts three values of a 3 byte structure, does an operation on the encrypted values, then unencrypts and verifies the results.
All secret data was hidden in lists of 10,000,000 random values. That made the first two tests (the ones done with 4 byte floats) have encrypted files of 38.1MB (40,000,000 bytes), and the last test (the one done with a 3 byte struct) had a file size of 28.6 MB (30,000,000 bytes).
Here are the timing of the above tests:

Sample Code
Here is the header, LTHE.h:
/* Written by Alan Wolfe http://blog.demofox.org */ #pragma once #include <vector> #include <random> // A static class with template functions in it. // A namespace would be nice, except I want to hide some things as private. class LTHE { public: //================================================================================= template <typename T> static bool Encrypt (std::vector<T> values, size_t listSize, const char* fileName, std::vector<size_t>& keys, bool generateKeys = true) { // Make sure we have a list that is at least as long as the values we want to encrypt if (values.size() > listSize) { fprintf(stderr, "ERROR in " __FUNCTION__ "(): values.size() > listSize.n"); return false; } // Generate a list of keys if we are told to // Ideally you want to take the first M items of a cryptographically secure shuffle // of N items. // This could be done with format preserving encryption or some other method // to make it not roll and check, and also more secure random. if (generateKeys) { keys.clear(); for (size_t i = 0, c = values.size(); i < c; ++i) { size_t newKey; do { newKey = RandomInt<size_t>(0, listSize - 1); } while (std::find(keys.begin(), keys.end(), newKey) != keys.end()); keys.push_back(newKey); } } // make a file of random values, size of T, count of <listSize> FILE *file = fopen(fileName, "w+b"); if (!file) { fprintf(stderr, "ERROR in " __FUNCTION__ "(): Could not open %s for writing.n", fileName); return false; } // Note: this may not be the most efficient way to generate this much random data or // write it all to the file. // In a real crypto usage case, you'd want a crypto secure random number generator. // You'd also want to make sure the random numbers had the same properties as your // input values to help anonymize them better. // Like if your numbers are not whole numbers, you don't want to generate only whole numbers. // Or if your numbers are salaries, you may not want purely random values, but more "salaryish" // looking numbers. // You could alternately just do all 2^N possible values which would definitely anonymize // the values you wanted to encrypt. This is maximum security, but also takes most // memory and most processing time. size_t numUint32s = (listSize * sizeof(T)) / sizeof(uint32_t); size_t numExtraBytes = (listSize * sizeof(T)) % sizeof(uint32_t); for (size_t i = 0; i < numUint32s; ++i) { uint32_t value = RandomInt<uint32_t>(); if (fwrite(&value, sizeof(value), 1, file) != 1) { fprintf(stderr, "ERROR in " __FUNCTION__ "(): Could not write random numbers (uint32s).n"); fclose(file); return false; } } for (size_t i = 0; i < numExtraBytes; ++i) { uint8_t value = RandomInt<uint8_t>(); if (fwrite(&value, sizeof(value), 1, file) != 1) { fprintf(stderr, "ERROR in " __FUNCTION__ "(): Could not write random numbers (extra bytes).n"); fclose(file); return false; } } // Now put the values in the file where they go, based on their key for (size_t i = 0, c = values.size(); i < c; ++i) { long pos = (long)(keys[i] * sizeof(T)); if (fseek(file, pos, SEEK_SET) != 0) { fprintf(stderr, "ERROR in " __FUNCTION__ "(): Could not fseek.n"); fclose(file); return false; } if (fwrite(&values[i], sizeof(values[i]), 1, file) != 1) { fprintf(stderr, "ERROR in " __FUNCTION__ "(): Could not write secret value.n"); fclose(file); return false; } } // close file and return success fclose(file); return true; } //================================================================================= template <typename T, typename LAMBDA> static bool TransformHomomorphically (const char* srcFileName, const char* destFileName, const LAMBDA& function) { // open the source and dest file if we can FILE *srcFile = fopen(srcFileName, "rb"); if (!srcFile) { fprintf(stderr, "ERROR in " __FUNCTION__ "(): Could not open %s for reading.n", srcFileName); return false; } FILE *destFile = fopen(destFileName, "w+b"); if (!destFile) { fprintf(stderr, "ERROR in " __FUNCTION__ "(): Could not open %s for writing.n", destFileName); fclose(srcFile); return false; } // Process the data in the file and write it back out. // This could be done much better. // We could read more from the file at once. // We could use SIMD. // We could go multithreaded. // We could do this on the GPU for large data sets and longer transformations! Assuming data transfer time isn't too prohibitive. // We could decouple the disk access from processing, so it was reading and writing while it was processing. const size_t c_bufferSize = 1024; std::vector<T> dataBuffer; dataBuffer.resize(c_bufferSize); size_t elementsRead; do { // read data from the source file elementsRead = fread(&dataBuffer[0], sizeof(T), c_bufferSize, srcFile); // transform the data for (size_t i = 0; i < elementsRead; ++i) dataBuffer[i] = function(dataBuffer[i]); // write the transformed data to the dest file if (fwrite(&dataBuffer[0], sizeof(T), elementsRead, destFile) != elementsRead) { fprintf(stderr, "ERROR in " __FUNCTION__ "(): Could not write transformed elements.n"); fclose(srcFile); fclose(destFile); return false; } } while (!feof(srcFile)); // close files and return success fclose(srcFile); fclose(destFile); return true; } //================================================================================= template <typename T, typename LAMBDA> static bool TransformHomomorphically (const char* src1FileName, const char* src2FileName, const char* destFileName, const LAMBDA& function) { // open the source and dest file if we can FILE *srcFile1 = fopen(src1FileName, "rb"); if (!srcFile1) { fprintf(stderr, "ERROR in " __FUNCTION__ "(): Could not open %s for reading.n", src1FileName); return false; } FILE *srcFile2 = fopen(src2FileName, "rb"); if (!srcFile2) { fprintf(stderr, "ERROR in " __FUNCTION__ "(): Could not open %s for reading.n", src2FileName); fclose(srcFile1); return false; } FILE *destFile = fopen(destFileName, "w+b"); if (!destFile) { fprintf(stderr, "ERROR in " __FUNCTION__ "(): Could not open %s for writing.n", destFileName); fclose(srcFile1); fclose(srcFile2); return false; } // Process the data in the file and write it back out. // This could be done much better. // We could read more from the file at once. // We could use SIMD. // We could go multithreaded. // We could do this on the GPU for large data sets and longer transformations! Assuming data transfer time isn't too prohibitive. // We could decouple the disk access from processing, so it was reading and writing while it was processing. const size_t c_bufferSize = 1024; std::vector<T> dataBuffer1, dataBuffer2; dataBuffer1.resize(c_bufferSize); dataBuffer2.resize(c_bufferSize); size_t elementsRead1; size_t elementsRead2; do { // read data from the source files elementsRead1 = fread(&dataBuffer1[0], sizeof(T), c_bufferSize, srcFile1); elementsRead2 = fread(&dataBuffer2[0], sizeof(T), c_bufferSize, srcFile2); if (elementsRead1 != elementsRead2) { fprintf(stderr, "ERROR in " __FUNCTION__ "(): Different numbers of elements in each file!n"); fclose(srcFile1); fclose(srcFile2); fclose(destFile); return false; } // transform the data for (size_t i = 0; i < elementsRead1; ++i) dataBuffer1[i] = function(dataBuffer1[i], dataBuffer2[i]); // write the transformed data to the dest file if (fwrite(&dataBuffer1[0], sizeof(T), elementsRead1, destFile) != elementsRead1) { fprintf(stderr, "ERROR in " __FUNCTION__ "(): Could not write transformed elements.n"); fclose(srcFile1); fclose(srcFile2); fclose(destFile); return false; } } while (!feof(srcFile1)); // close files and return success fclose(srcFile1); fclose(srcFile2); fclose(destFile); return true; } //================================================================================= template <typename T> static bool Decrypt (const char* fileName, std::vector<T>& values, std::vector<size_t>& keys) { // Open the file if we can FILE *file = fopen(fileName, "rb"); if (!file) { fprintf(stderr, "ERROR in " __FUNCTION__ "(): Could not open %s for reading.n", fileName); return false; } // Read the values from the file. The key is their location in the file. values.clear(); for (size_t i = 0, c = keys.size(); i < c; ++i) { long pos = (long)(keys[i] * sizeof(T)); if (fseek(file, pos, SEEK_SET) != 0) { fprintf(stderr, "ERROR in " __FUNCTION__ "(): Could not fseek.n"); fclose(file); return false; } T value; if (!fread(&value, sizeof(T), 1, file)) { fprintf(stderr, "ERROR in " __FUNCTION__ "(): Could not decrypt value for key.n"); fclose(file); return false; } values.push_back(value); } // Close file and return success fclose(file); return true; } private: template <typename T> static T RandomInt (T min = std::numeric_limits<T>::min(), T max = std::numeric_limits<T>::max()) { static std::random_device rd; static std::mt19937 mt(rd()); static std::uniform_int<T> dist(min, max); return dist(mt); } };
And here is the test program, main.cpp:
#include <stdio.h>
#include "LTHE.h"
#include <chrono>
//=================================================================================
// times a block of code
struct SBlockTimer
{
SBlockTimer()
{
m_start = std::chrono::high_resolution_clock::now();
}
~SBlockTimer()
{
std::chrono::duration<float> seconds = std::chrono::high_resolution_clock::now() - m_start;
printf(" %0.2f secondsn", seconds.count());
}
std::chrono::high_resolution_clock::time_point m_start;
};
//=================================================================================
float TransformDataUnitary (float& value)
{
return (float)sqrt(value * 2.17f + 0.132);
}
//=================================================================================
float TransformDataBinary (float& value1, float value2)
{
return (float)sqrt(value1 * value1 + value2 * value2);
}
//=================================================================================
struct SStruct
{
uint8_t x, y, z;
static SStruct Transform (const SStruct& b)
{
SStruct ret;
ret.x = b.x * 2;
ret.y = b.y * 3;
ret.z = b.z * 4;
return ret;
}
bool operator != (const SStruct& b) const
{
return b.x != x || b.y != y || b.z != z;
}
};
//=================================================================================
int Test_FloatUnitaryOperation ()
{
printf("n----- " __FUNCTION__ " -----n");
// Encrypt the data
printf("Encrypting data: ");
std::vector<float> secretValues = { 3.14159265359f, 435.0f };
std::vector<size_t> keys;
{
SBlockTimer timer;
if (!LTHE::Encrypt(secretValues, 10000000, "Encrypted.dat", keys))
{
fprintf(stderr, "Could not encrypt data.n");
return -1;
}
}
// Transform the data
printf("Transforming data:");
{
SBlockTimer timer;
if (!LTHE::TransformHomomorphically<float>("Encrypted.dat", "Transformed.dat", TransformDataUnitary))
{
fprintf(stderr, "Could not transform encrypt data.n");
return -2;
}
}
// Decrypt the data
printf("Decrypting data: ");
std::vector<float> decryptedValues;
{
SBlockTimer timer;
if (!LTHE::Decrypt("Transformed.dat", decryptedValues, keys))
{
fprintf(stderr, "Could not decrypt data.n");
return -3;
}
}
// Verify the data
printf("Verifying data: ");
{
SBlockTimer timer;
for (size_t i = 0, c = secretValues.size(); i < c; ++i)
{
if (TransformDataUnitary(secretValues[i]) != decryptedValues[i])
{
fprintf(stderr, "decrypted value mismatch!n");
return -4;
}
}
}
return 0;
}
//=================================================================================
int Test_FloatBinaryOperation ()
{
printf("n----- " __FUNCTION__ " -----n");
// Encrypt the data
printf("Encrypting data: ");
std::vector<float> secretValues1 = { 3.14159265359f, 435.0f, 1.0f };
std::vector<float> secretValues2 = { 1.0f, 5.0f, 9.0f };
std::vector<size_t> keys;
{
SBlockTimer timer;
if (!LTHE::Encrypt(secretValues1, 10000000, "Encrypted1.dat", keys))
{
fprintf(stderr, "Could not encrypt data.n");
return -1;
}
if (!LTHE::Encrypt(secretValues2, 10000000, "Encrypted2.dat", keys, false)) // reuse the keys made for secretValues1
{
fprintf(stderr, "Could not encrypt data.n");
return -1;
}
}
// Transform the data
printf("Transforming data:");
{
SBlockTimer timer;
if (!LTHE::TransformHomomorphically<float>("Encrypted1.dat", "Encrypted2.dat", "Transformed.dat", TransformDataBinary))
{
fprintf(stderr, "Could not transform encrypt data.n");
return -2;
}
}
// Decrypt the data
printf("Decrypting data: ");
std::vector<float> decryptedValues;
{
SBlockTimer timer;
if (!LTHE::Decrypt("Transformed.dat", decryptedValues, keys))
{
fprintf(stderr, "Could not decrypt data.n");
return -3;
}
}
// Verify the data
printf("Verifying data: ");
{
SBlockTimer timer;
for (size_t i = 0, c = secretValues1.size(); i < c; ++i)
{
if (TransformDataBinary(secretValues1[i], secretValues2[i]) != decryptedValues[i])
{
fprintf(stderr, "decrypted value mismatch!n");
return -4;
}
}
}
return 0;
}
//=================================================================================
int Test_StructUnitaryOperation ()
{
printf("n----- " __FUNCTION__ " -----n");
// Encrypt the data
printf("Encrypting data: ");
std::vector<SStruct> secretValues = { {0,1,2},{ 3,4,5 },{ 6,7,8 } };
std::vector<size_t> keys;
{
SBlockTimer timer;
if (!LTHE::Encrypt(secretValues, 10000000, "Encrypted.dat", keys))
{
fprintf(stderr, "Could not encrypt data.n");
return -1;
}
}
// Transform the data
printf("Transforming data:");
{
SBlockTimer timer;
if (!LTHE::TransformHomomorphically<SStruct>("Encrypted.dat", "Transformed.dat", SStruct::Transform))
{
fprintf(stderr, "Could not transform encrypt data.n");
return -2;
}
}
// Decrypt the data
printf("Decrypting data: ");
std::vector<SStruct> decryptedValues;
{
SBlockTimer timer;
if (!LTHE::Decrypt("Transformed.dat", decryptedValues, keys))
{
fprintf(stderr, "Could not decrypt data.n");
return -3;
}
}
// Verify the data
printf("Verifying data: ");
{
SBlockTimer timer;
for (size_t i = 0, c = secretValues.size(); i < c; ++i)
{
if (SStruct::Transform(secretValues[i]) != decryptedValues[i])
{
fprintf(stderr, "decrypted value mismatch!n");
return -4;
}
}
}
return 0;
}
//=================================================================================
int main (int argc, char **argv)
{
// test doing an operation on a single encrypted float
int ret = Test_FloatUnitaryOperation();
if (ret != 0)
{
system("pause");
return ret;
}
// test doing an operation on two encrypted floats
ret = Test_FloatBinaryOperation();
if (ret != 0)
{
system("pause");
return ret;
}
// test doing an operation on a single 3 byte struct
ret = Test_StructUnitaryOperation();
if (ret != 0)
{
system("pause");
return ret;
}
printf("nAll Tests Passed!nn");
system("pause");
return 0;
}
If you found this post interesting or useful, or you have anything to add or talk about, let me know!
Reddit discussion:
r/programming
r/cryptography
 different pieces, where if you have any
different pieces, where if you have any  of those
of those  in that equation, but use your secret number as the constant term.
in that equation, but use your secret number as the constant term. aka
aka  . Those are your shares. You then give individual shares to people, or go hide them in your dungeon or do whatever you are going to do with them.
. Those are your shares. You then give individual shares to people, or go hide them in your dungeon or do whatever you are going to do with them. .
.

 values are random numbers, and
values are random numbers, and  is the secret value.
is the secret value.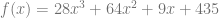



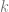 and instead of shares being
and instead of shares being 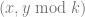 . In technical terms we are going to be using points on a finite field, or a Galois field.
. In technical terms we are going to be using points on a finite field, or a Galois field.
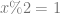


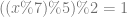



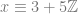

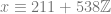
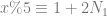 where
where  .
.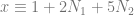 where
where  .
. which reads as “in all integers mod 2”.
which reads as “in all integers mod 2”.
 .
. where
where  and
and 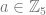
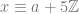 where
where 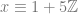


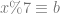
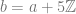


![a = [1,3]](https://s0.wp.com/latex.php?latex=a+%3D+%5B1%2C3%5D&bg=ffffff&fg=666666&s=0&c=20201002)
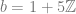 ,
,  ,
, ![b = [1,3,6]](https://s0.wp.com/latex.php?latex=b+%3D+%5B1%2C3%2C6%5D&bg=ffffff&fg=666666&s=0&c=20201002)
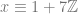


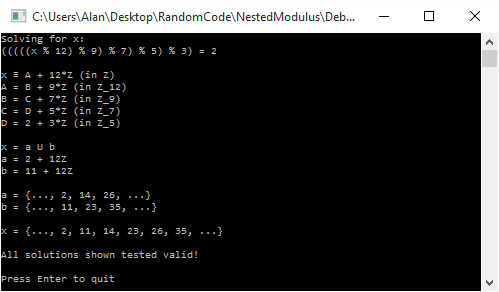
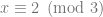
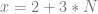 where N is any integer, aka
where N is any integer, aka  .
.





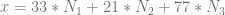
 , it will always be a perfect multiple of 3 and 11, which means that the value will be zero in the other terms / other equations, so won’t affect whatever value we come up for them.
, it will always be a perfect multiple of 3 and 11, which means that the value will be zero in the other terms / other equations, so won’t affect whatever value we come up for them. .
. where
where  , but we can stick to using 15 to make it easier to follow.
, but we can stick to using 15 to make it easier to follow.




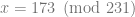
 where
where 


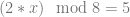
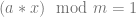
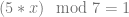
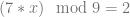 , to come up with a value of 8 for x.
, to come up with a value of 8 for x.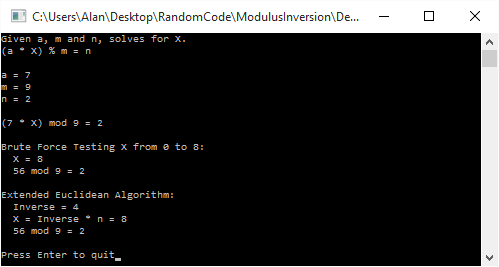
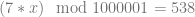 . Brute force gives a value of 571,506 for x, while using the inversion method gives us a value of 230,571,736.
. Brute force gives a value of 571,506 for x, while using the inversion method gives us a value of 230,571,736.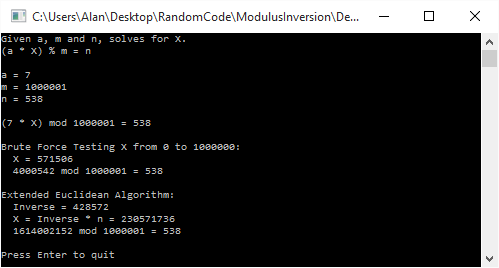
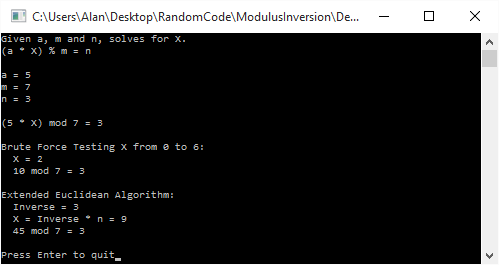
 . Brute force gives us a value of 2 for x, but interestingly, it isn’t invertible, so the inversion based solution can’t even find us an answer!
. Brute force gives us a value of 2 for x, but interestingly, it isn’t invertible, so the inversion based solution can’t even find us an answer!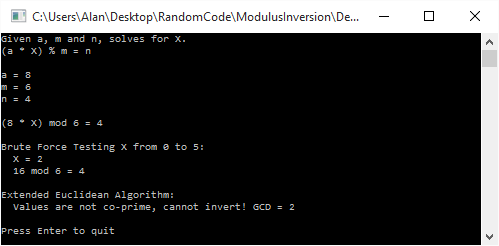
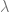 ) that everything else is based on.
) that everything else is based on.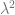 ) bits, randomNumber1 should be around
) bits, randomNumber1 should be around  (
( bits) and that randomNumber2 should be around
bits) and that randomNumber2 should be around  (
( bits).
bits). operations and that you can assume an attacker is going to be able to do a billion operations per second (per this info
operations and that you can assume an attacker is going to be able to do a billion operations per second (per this info