An irrational number is a number that can’t be represented as a fraction using integers for the numerator and denominator.
I’m a big fan of irrational numbers, and one of the biggest reasons for that is that they are great at making low discrepancy sequences, which give amazing results when used in stochastic (randomized) algorithms, compared to regular random numbers. Low discrepancy sequences are cousins to blue noise because they both aim to keep samples well spread out, but the usage case is different, so it’s situational whether to use blue noise or an LDS. That means that luckily there is room enough in the world for both LDS and blue noise.
This post is a random grab bag of things relating to irrational numbers.
Pythagorian cultists supposedly murdered someone to keep irrational numbers a secret, so this is technically forbidden knowledge, I guess.
Making Continued Fractions – Pi and Milü
Continued fractions are a way of writing numbers that can be useful for helping analyze irrational numbers, and rational approximations to specific numbers – whether they are rational or irrational.
If a continued fraction is infinitely long, that means it represents an irrational number, and all irrational numbers have continued fractions that are infinitely long. If a continued fraction is not infinitely long, that means it’s a rational number.
Here is the beginning of the continued fraction for pi.

Another way of writing continued fractions is to get rid of all the redundant “1 divided by…” and just write the integers you see on the left. The continued fraction for pi above would look like this, which is a lot more compact:
[3;7,15,1,292,1,1,1,2,1,3,1]
Let’s talk about how you make a continued fraction by walking through how to make it for pi, or at least 3.14159265359 anyways, since pi goes forever.
First up you take the integer part and use that as the first digit. Subtracting that integer part out leaves you with a remainder:
[3]
remainder: 0.14159265359
We take 1/remainder to get 7.06251330592. The integer part of this number is going to be our next number. Subtracting the integer part out gives us our next remainder:
[3;7]
remainder: 0.06251330592
1/remainder is 15.9965944095, which makes our next integer and remainder into:
[3;7,15]
remainder: 0.9965944095
1/remainder is 1.00341722818, so now we are at…
[3;7,15,1]
remainder: 0.00341722818
1/remainder is 292.63483365 so now we are at:
[3;7,15,1,292]
remainder: 0.63483365
1/remainder is 1.57521580653 and we’ll stop at the next step:
[3;7,15,1,292, 1]
remainder: 0.57521580653
Wherever you have a large number in the continued fraction, it’s because you just did one divided by a small number. The larger the integer means the smaller the remainder there was to make that integer.
The smaller a remainder is, the better approximated the number is at that step of the continued fraction.
This means that when you see a large number in a continued fraction, that if you truncated the continued fraction right before that large number, you’d have a pretty good approximation of the actual number that the continued fraction represents.
The larger the number, the better the approximation.
Because of this, looking at the continued fraction for pi, below, you can see that it has a pretty large number (292) pretty early in the sequence.
[3;7,15,1,292,1,1,1,2,1,3,1]
This means that the following continued fraction approximates pi “pretty well”.
[3;7,15,1]
We’ll cover how to figure this out further down in the post, but that fraction is actually 355/113 and has a special name “Milü”, found by Chinese mathematician and astronomer, Zǔ Chōngzhī, born 429 AD. It is within 0.000009% of the value of pi.
More info from wikipedia: https://en.wikipedia.org/wiki/Mil%C3%BC
So, while pi is probably the most famous irrational number, it certain isn’t the most irrational number that there is, as it is so easily approximated by smallish integers in a division.
Quick note if you write a program to convert a floating point number to a continued fraction: If you try to make a continued fraction for a number that a floating point can’t represent exactly – such as 4.1 – you will get a very tiny remainder which then makes a very large integer when you flip it over. In my case, when using doubles, it made such a large number that converting it to an integer overflowed the integer. One way to address this is to just consider any remainder smaller than some threshold as zero. Like maybe any remainder less than 0.00001 can be considered zero.
The Continued Fraction of Phi aka The Golden Ratio
So even though pi is not the most irrational number, phi is (pronounced “fee”, and is aka the golden ratio). Yes, it is the most irrational number!
We’ll use the value 1.61803398875 and make a continued fraction.
[1]
remainder: 0.61803398875
1/remainder: 1.61803398875
[1;1]
remainder: 0.61803398875
1/remainder: 1.61803398875
[1;1,1]
remainder: 0.61803398875
1/remainder: 1.61803398875
Wait a second… do you see a pattern? the remainder is always the same value, and then when we do 1/remainder we always get the golden ratio again. That means this continued fraction is 1’s all the way into infinity.
In the last section we saw how having a large number in the continued fraction meant that a number was well approximated at that point in the continued fraction.
The golden ratio has a 1 for every number in the continued fraction, which is the smallest value you can have. That means it’s as least well approximated as you can be, at every stage in the continued fraction.
This is what is meant by the golden ratio being the most irrational number. It’s the least well approximated by rational numbers (dividing one integer by another).
When I said I liked irrational numbers I was mainly talking about the golden ratio, but other highly irrational numbers, like the square root of 2, are also nice. Highly irrational numbers have the properties that I like – the properties that make them useful to use as low discrepancy sequences.
An interesting thing you may have noticed above is that when you divide 1 by the golden ratio, you get the golden ratio minus 1. That is:
1 / 1.61803398875 = 0.61803398875
If you replace the golden ratio with “x” you get this equation:
1/x = x-1
If you solve that equation, you will get the golden ratio out. It is the only number that has this property! Well actually, -0.61803398875 does too, and relates to the fact that there is a + and – root solution to that quadratic equation, but maybe that’s not that surprising. 1/-0.61803398875 is -1.61803398875. The behavior is the same, it’s just happening on the other side of zero.
Something else interesting about the golden ratio is that if you square it, it’s the same as adding 1.
1.61803398875*1.61803398875=2.61803398875
That gives you a formula:
x*x = x+1
If you solve that, you get the golden ratio again as the only solution (well, and the negative golden ratio minus 1 just like before). Probably not too surprising if you look at the formulas though, as you can use simple algebra to change one formula into the other.
From Continued Fractions To Regular Fractions
If you had a continued fraction and wanted to turn it into a regular fraction (or real number), you could run the process in reverse.
However, doing that means you start at the right most digit of the continued fraction and work left til you get to the beginning. How do you do this with an infinitely long continued fraction, like an irrational number would have?
Luckily there is a way to start at the left and work right, so that you can get approximations to infinitely long continued fractions (irrational numbers).
Let’s do this with pi, with this much of the continued fraction:
[3;7,15,1,292,1,1]
What you do is make a table which has a row for the numerator and denominator. The first numerator is 1, and the first denominator is 0. The second numerator is the first number in the continued fraction sequence, and the second denominator is 1.

The formula for the rest of the numerators and denominators is…
- numerator[index] = CF[index] * numerator[index-1] + numerator[index-2]
- denominator[index] = CF[index] * denominator[index-1] + denominator[index-2]
Doing that from left to right, you get this:

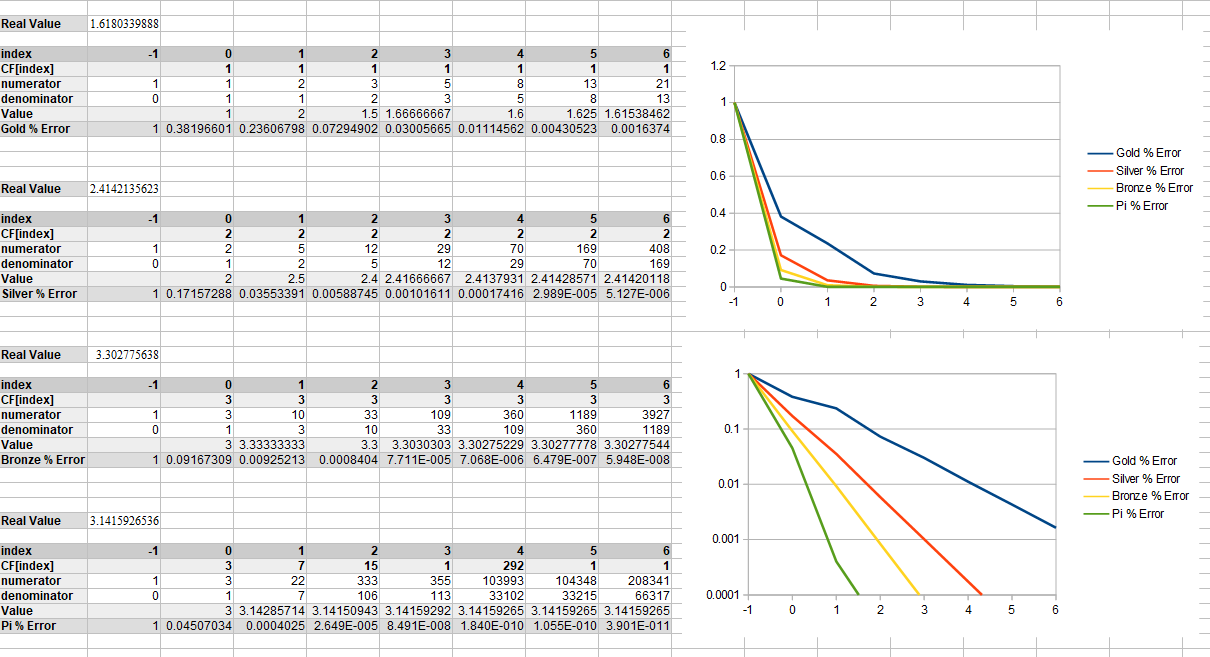
Below we do that with pi, golden ratio, sqrt(2) and an irrational number i came up with that is not very irrational, and is well approximated by 1.01.

A quick fun tangent is that you might notice that for golden ratio, both the numerators and denominators are the Fibonacci numbers. This is the link between the golden ratio and Fibonacci numbers.
Below shows the percentage error of each number, as more terms in the continued fraction are added.
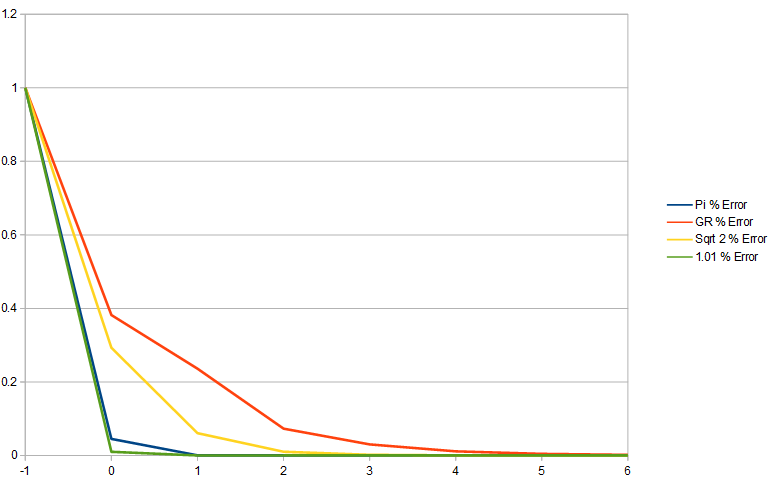
Golden ratio error decreases the slowest which shows that the golden ratio is least well approximated by fractions. The made up irrational number that is approximately 1.01 has error decreasing the fastest because it is the least irrational of these numbers. Pi shows itself as having fairly low irrationality, and the square root of 2 is fairly irrational.
Here is the error on a log y axis to better show the difference in error.
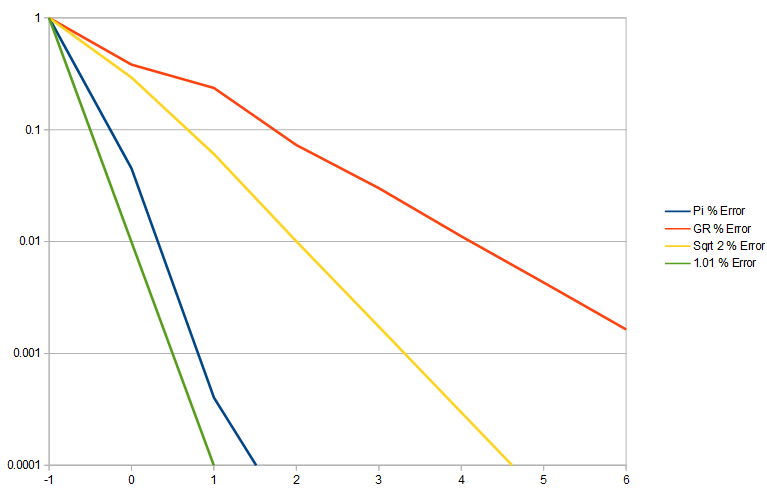
It’s worth noting that 1/goldenRatio aka 0.61803398875 is every bit as irrational as the golden ratio itself is. The reason for this is that we are flipping the numerator and denominator over for this fraction that doesn’t exist. Flipping it over doesn’t make it more representable as a fraction.
When I’m using the golden ratio for low discrepancy sequences, i usually use that 1/goldenRatio value, also known as “the golden ratio conjugate” because the smaller value means it’s going to have fewer numerical issues and more precision, when working with small values (like between 0 and 1).
Also, there are an infinite amount of numbers just as irrational as the golden ratio. You can calculate them by calculating:
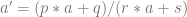
where p,q,r,s are integers and the absolute value of p*s-q*r is 1.
That is the Moebius transform.
If you are wondering what the least irrational number is, it looks like there are multiple (infinite) and they are just numbers that are very, very, very well approximated by rationals. They are called Liouville numbers and are transcendental, meaning they can’t be calculated with polynomials basically. Proving the existence of these numbers also probed the existence of transcendental numbers themselves. (https://en.wikipedia.org/wiki/Liouville_number)
There is also something called an irrationality measurement, but I haven’t found it that useful. It doesn’t seem to be something you can calculate with a program and compare two numbers to see which is more irrational. https://mathworld.wolfram.com/IrrationalityMeasure.html
Metallic Means
If all 1’s in a continued fraction make the golden ratio, what would all 2s or all 3s make? That makes the silver and bronze ratio respectively and all three of these are the first three of the “Metallic Means”. You can see the details of them below, along with pi. Wikipedia talks more about them too at https://en.wikipedia.org/wiki/Metallic_mean
You might also be interested in reading about the “Plastic Number” which is a different way of trying to approach the goodness of the golden ratio to get another decently irrational number. https://en.wikipedia.org/wiki/Plastic_number
Where the golden ratio has a formula x^2 = x+1, the plastic number has a formula x^3 = x+1.
Coprime Numbers (Setup For Irrational LDS)
Coprime numbers are 2 or more integers that share only 1 as a factor.
For instance, 7 and 11 are coprime numbers. They also happen to be prime numbers, but coprime numbers don’t have to be prime. 8 and 15 are also coprime numbers although neither number is prime. You can even lump all four together and say that 7, 8, 11, 15 are coprime numbers. Combining lists of coprime numbers doesn’t usually result in a list of numbers that are still coprime. This just worked out because we added only prime numbers to the other list of coprimes, and adding primes will always keep the list of numbers coprime.
You might wonder why you should care about coprimes.
My favorite use of coprimes is when i need cheap shuffles of numbers.
For instance, let’s say you had 8 numbers and you wanted them to be shuffled into a somewhat randomized order, but it didn’t need to be a very high quality shuffle.
What you do is first pick any number that is coprime to 8… we’ll say 5. You then count an index from 1 to 8 and do this…
Out = (index * 5) % 8
Taking index from 1 to 8 gives you the following output:
5, 2, 7, 4, 1, 6, 3, 0
If you look at it a bit, you can probably find some patterns, but all the numbers are there and it is fairly mixed up wouldn’t you say? A casual observer probably isn’t going to notice any patterns if you used this in a game setting for dropping treasure or something.
Not all coprime choices give the same quality results though. Here is what happens if we use 7 as the coprime number instead of 5:
Out = (index * 7) % 8
7, 6, 5, 4, 3, 2, 1, 0
It just reversed the list! That isn’t very mixed up.
Also, let’s look at what happens if you don’t use coprimes. We’ll use 2 instead of 7.
Out = (index * 2) % 8
2, 4, 6, 0, 2, 4, 6, 0
If the numbers aren’t coprime, it won’t generate all the numbers in the list. Another way of looking at this is that the cycle length of the number sequence is maximally long when the numbers are coprime, but are not going to be as long (and will repeat) if the numbers are not coprime.
Note that you don’t have to use index values 1 through 8. You could use 0 through 7 instead or any other contiguous 8 values – like 127 through 134. The numbers in this case are all mod 8, so 127 through 134 is equivalent to 7 through 14.
Irrational LDS
An additive recurrence sequence is basically the same concept as the last section, but taken to the continuous world instead of sticking to discrete integers. You use the formula below, where A is any real number:
Out = (index * A) % 1
Just like before with coprime numbers, the value you multiply index by can make you have better or worse results.
If you pick 1/2 (0.5) for A, the sequence you’ll get out is this:
0.5, 0.0, 0.5, 0.0, 0.5, …
If you pick 1/4 (0.25) for A, you’ll get this:
0.25, 0.5, 0.75, 0.0, 0.25, 0.5, 0.75, 0.0, …
1/3 will get you this:
0.333, 0.666, 0.0, 0.333, 0.666, 0.0, …
2/3 will get you this:
0.666, 0.333, 0.0, 0.666, 0.333, 0.0, …
You can also do something more complex, like 5/8:
0.625, 0.25, 0.875, 0.5, 0.125, 0.75, 0.375, 0.0, …
(it then repeats)
If we picked 2/4, we’d end up with 0.5, just like we did when we used 1/2. When thinking about fractions to use in this setup, you should reduce the fraction, because unreduced fractions give the same value as reduced fractions. Ready for the kicker? The numerator and denominator in a reduced fraction will always be coprime integers – by definition of being a reduced fraction! Also, the denominator of the reduced fraction will tell you the length of the sequence it generates.
I snuck a little trick in the examples, did you catch it?
Let’s look at that sequence using 5/8 again, but let’s write the results as fractions.
5/8, 2/8, 7/8, 4/8, 1/8, 6/8, 3/8, 0/8, …
Now let’s look back at the sequence we made last section where we did (index*5)%8
5, 2, 7, 4, 1, 6, 3, 0
The numerator in the fraction results is the same as the integer one using coprimes. You could multiply the fractional results by 8 and get the exact same numbers. In fact take the formula we are using in this section:
Out = (index * 5/8) % 1
And multiply it by 8 to get the formula used in the last section!
Out = (index * 5) % 8
So, while we seemed to have moved away from integers into a continuous domain, we haven’t really… we are still in the land of coprime number sequences. We will always be in the land of coprime number sequences as long as we are using rational numbers, because there will always be a coprime numerator and denominator pair in the simplified fraction that defines the length of the sequence that comes out when we feed index numbers in.
So what if we ditch rational numbers and go with an irrational number? Well, using an irrational number means that the sequence will never repeat. While that in itself sounds awesome, let’s imagine we are using an irrational number that is well approximated by 1/4. That means that the sequence would never repeat, but it would NEARLY repeat every 4 values.
Let’s show the sequence using the golden ratio, where index goes from 1 to 8.
0.618034, 0.236068, 0.854102, 0.472136, 0.090170, 0.708204, 0.326238, 0.944272
Here is the same for a not very irrational number that we are going to approximate with 0.2490001.
0.249000, 0.498000, 0.747000, 0.996000, 0.245000, 0.494001, 0.743001, 0.992001
You can see that the sequence with the ~0.25 irrational isn’t EXACTLY repeating, but it sure is close to repeating. The golden ratio is making very unique numbers in comparison
So basically, if you use an irrational number that can be closely approximated by a rational number, it’ll behave a lot like that rational number and not be real great.
This is what is great about the golden ratio and other highly irrational numbers. There is no rational number that well approximates them, so not only do they not have any actual repeats, they also don’t have any NEAR repeats.
Using highly irrational numbers in this additive recurrence formula, you get a low discrepancy sequence.
Irrational LDS Offset
Every time you use an irrational LDS, you are going to get the same sequence, which can sometimes be a problem.
You can get around this by starting at a different index every time, or by adding a different starting value to the sequence.
Option #1: Randomized Start Index:
Out = ((index+StartIndex) * Irrational) % 1
Option #2: Randomized Starting Value:
Out = (Index * Irrational + StartValue) % 1
How you get this starting index or starting value is up to you. Honestly, I use white noise random numbers and it works fine, so I’ll keep doing that until I analyze it and find out how much better using an LDS is.
Anyways, if you recall from earlier in the post, this LDS won’t repeat so long as you use an irrational number. That means that the infinite number of integer index values going in means you get an infinite number of unique real numbers coming out. That means that the LDS can output any number possible just by changing the index you are at. So, offsetting by index is equivalent to offsetting by a start value, since there is some index that should give the same output as any specific starting value.
I thought that was true, but it turns out it isn’t, because integers are countably infinite while irrational numbers are a larger infinity.
It turns out that this is nearly true though, and that there always exists an index that will give you a value arbitrarily close to any specific starting value.
Although, this is only mathematically true. Computers have finite storage for integers and floats.
Anyways, it’s complicated, but either offsetting index or starting value should work just fine for getting a different sequence. I go the starting value way myself.
More info here regarding that mathematical topic: https://twitter.com/Atrix256/status/1285646721561899010?s=20
BTW even though i show the formula for irrational LDS as index multiplying by the irrational number, that will have numerical precision problems as the index gets larger. You are way better off just adding the irrational and doing modulus when you want the value for the next index. The difference is huge, surprisingly!
Irrational LDS & Arbitrary Start Progressive Sequences
There is the concept of a progressive low discrepancy sequence, which means that any subset of the sequence, starting at index 0, will have the same properties as the entire sequence.
For instance, if you had a progressive blue noise sequence with 100 samples in it, using only the first 10 samples would be blue noise, or using the first 47 samples, or the first 73, or all 100.
If you had a non progressive blue noise sequence, the sample sequence wouldn’t be blue noise until all 100 samples have been used (or as you got close to that number).
Irrational low discrepancy sequences have a nice property that they are progressive, and they are progressive starting at ANY index, not just from index 0. This is because offsets in index are roughly equivalent to offsets in starting value, so starting in the middle of the sequence is the same as if you just started with that sample’s value as the starting value.
The golden ratio in particular is great for this. Each new sample from the golden ratio LDS falls in the biggest hole left by samples so far, which is why it’s so great for numerical integration (and similar). It has great coverage over the sampling domain. The crazy thing though, is that you can start at any index in the LDS and this is still true from that starting index, while it’s still also true if starting from index 0.
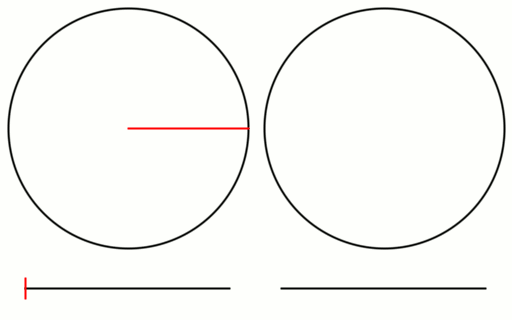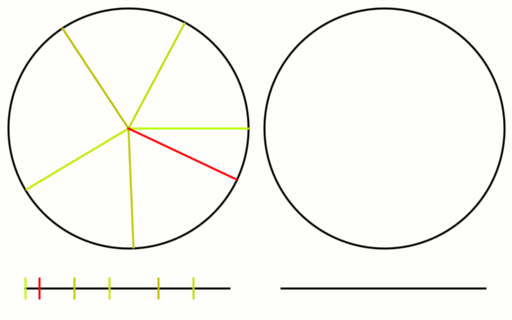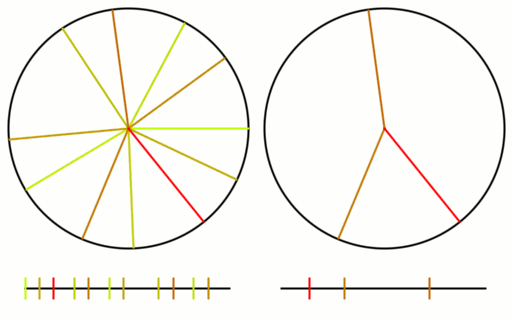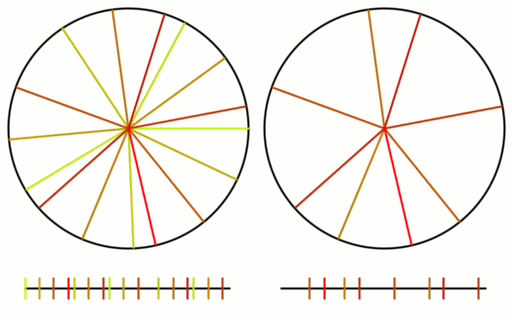
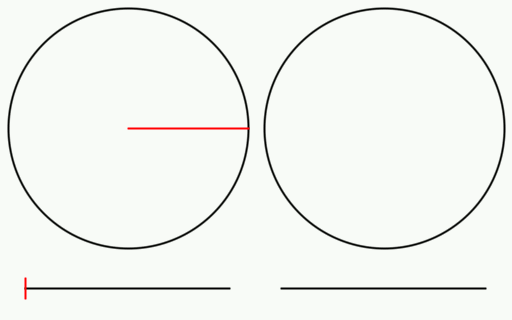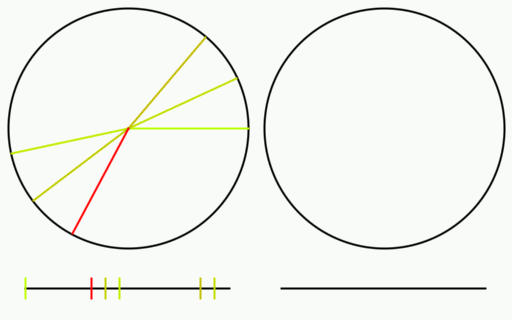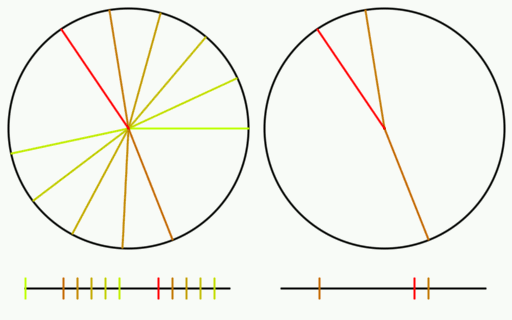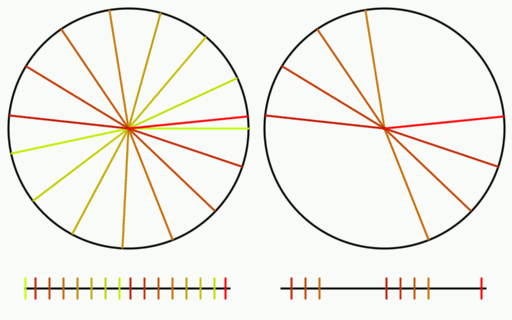
Check out the gif below to see what i’m talking about. There are 16 samples total. All 16 are shown on the left, but only the last 8 are shown on the right. I show the samples on a numberline since they are scalar values between 0 and 1, but I also show them on a circle to see that what i said about falling in the largest gap is true even with wrap around.
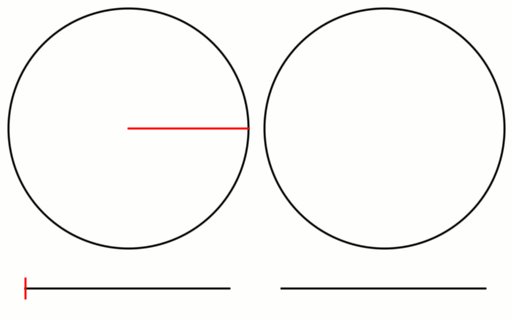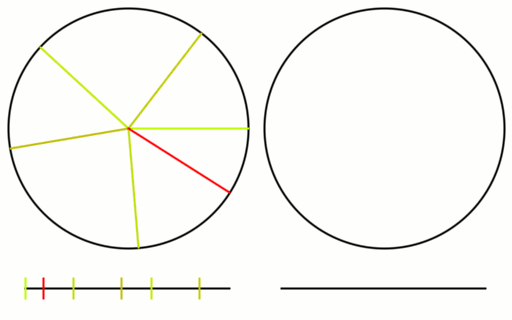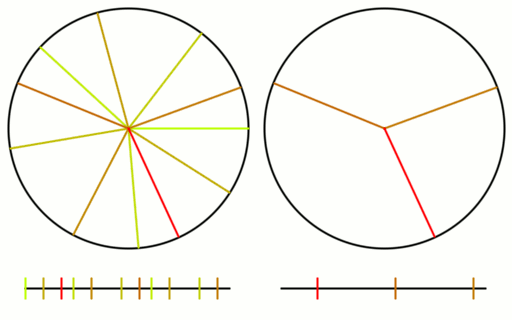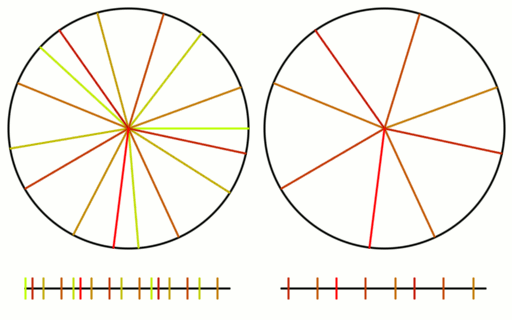
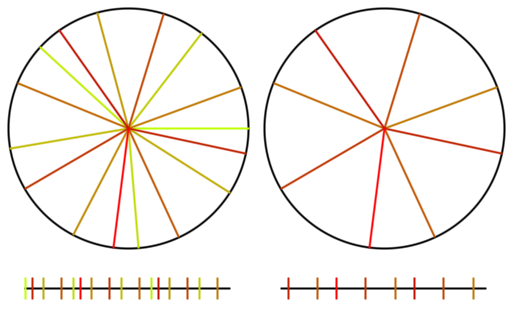
Here is the same setup for an animation using the square root of 2 instead.
Lastly, here is the same with pi. Pi is well approximated by 22/7 and since we are walking around a circle, the integer parts are irrelevant. Since 22/7 is 3 1/7, that makes pi act nearly like 1/7 and you can verify that it is indeed nearly repeating every 7 samples, and acting very much like 1/7. You can see how pi has samples that clump and it doesn’t give very good coverage over the sample domain for the number of samples it uses (compare the coverage to golden ratio!). This shows how a less irrational number isn’t as good at being a low discrepancy sequence.
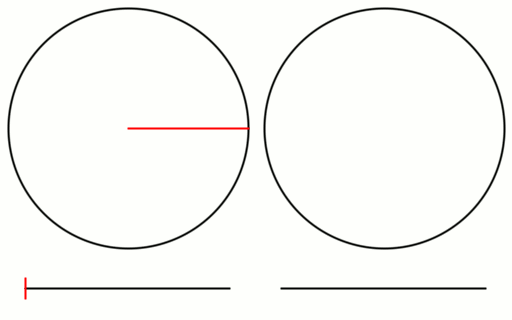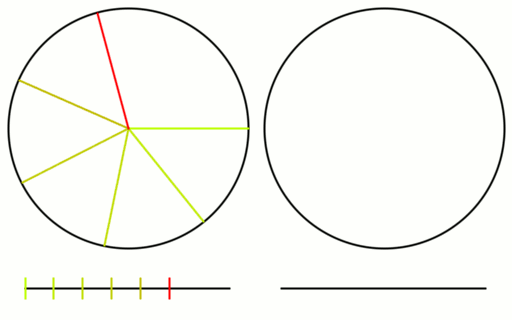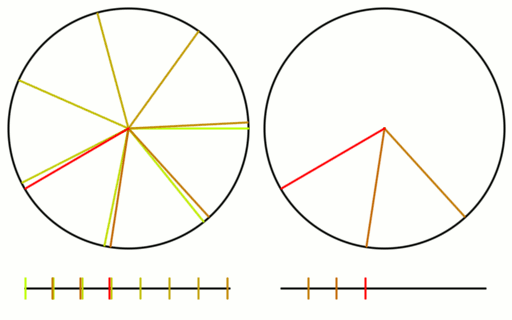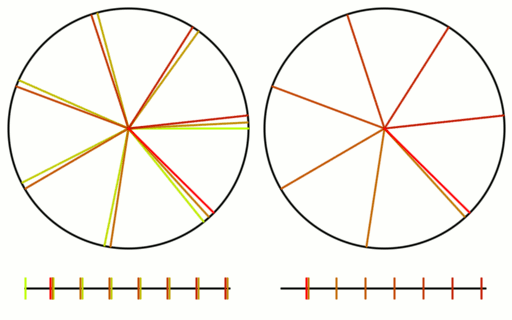
If you have heard that plants grow leaves in a golden ratio pattern, now is probably a good time to explain why. Here is the last frame of the golden ratio gif, when there are 16 samples.
One of a plant’s goals in life is to get as much sun as it possibly can. Imagine that the sun is directly overhead and you are looking down at the plant from above. Toward this goal of maximizing sunlight, whenever light is allowed to hit the ground in the radius of the circle of the plant’s shadow, that is a lost opportunity. Sunlight is being wasted by hitting the dirt.
There may also be temporary or semi-permanent shadows that exist or come into existence at any point in the plants life, and if it put all it’s leaves such that they clump in one direction, all those leaves may become in shadow and the plant could go hungry.
A solution to these problems is to grow leaves equally distributed around the plant. This way there are no overlaps when viewing from above, and the risk of shadowing is minimized by being well spread out over all directions.
This would be the end of it if a plant was born with all of it’s leaves and it knew how many leaves it was going to need to grow – and that no leaves were going to get eaten.
Plants are dynamic life forms though, in a dynamic environment, so the leaves need to be as evenly spaced radially as possible when it’s a seedling with just a couple leaves, but also when it is much older with many leaves, possibly with some of them eaten by animals, and all that jazz.
A good way to do this would be to use the golden ratio to figure out where the grow the next leaf.
Doing this, it will have good coverage over the entire circle of possible growth, it’s ok if old leaves die off and go away since it will still be well distributed, leaves can grow larger because overlap will be minimized.
Check out the gif again and think of each line as a leaf growing around a central stem, as the plant gets taller. The circle on the right shows what happens as the first 8 leaves get old, die and fall off, being replaced by 8 new leaves.
If this talk about plants was interesting, give a read here about “Phyllotaxis”
https://en.wikipedia.org/wiki/Phyllotaxis
A Connection Between Primes and Irrationals
So when we have this function where Out, A, B and index are integers:
Out = (index * A) % B
We will get a non repeating sequence of numbers B long from 0 to B-1, if A and B are coprime. Since prime numbers are coprime with all other numbers, we could also say that if A is prime, the sequence will have those properties. It isn’t required to be prime (just coprime) but let’s make the statement for primes right now.
If we move that to the real number world, where index is an integer, but A and out are real numbers:
Out = (index * A) % 1
If A is irrational, we will get a non repeating sequence of numbers infinitely long. In that way, irrational numbers are like primes in that when used, they make a non repeating sequence that is as long as possible.
More so, as A is more highly irrational, you get fewer “near repeats” as well, until getting to the golden ratio where you get a provably minimum amount of near repeats.
So, primes and irrationals (especially the golden ratio), are linked in that they make maximal length non repeating sequences when used over a field.
Co-Irrational Numbers
We talked about coprime numbers and how they would make a sequence that “went the full length”, that is, they made a sequence that didn’t repeat over the whole sequence. If you multiplied index by 5 and did a modulus by 8, you would get a sequence that was 8 items long and then would repeat.
We also talked about irrational numbers and how they would make sequences that NEVER repeated, and talked about how highly irrational numbers could make sequences that also didn’t have NEAR repeats.
This is great if you want one dimensional sequences, but what if you want two dimensional sequences or higher?
One way to do higher dimensional low discrepancy sequences is to just use a different irrational number per axis.
That is great but now you find yourself having to come up with a bunch of high quality irrational numbers since you need one for each axis. Sadly, there is only a single “golden ratio” really (Moebius transform and conjugate don’t give different behavior). If you used the golden ratio on each axis, you’d have correlation between the axes and it wouldn’t be great. Basically, each axis would have the same pattern, even if you start at a different index, or starting value.
There’s a concept I’m sure someone has thought of before, maybe going by a different name, that I call “co-irrationality”.
Coprime numbers have no shared factors other than 1, and thus “no shared cycle lengths” which make their output sequences be maximal lengths.
Similarly, co-irrational numbers should minimize how close they get to each other with their rational approximations. Where non coprime numbers used to make a sequence will repeat, two numbers that aren’t very co-irrational will make a sequence that will nearly repeat, which is nearly just as bad.
Just like how a coprime number doesn’t have to be prime, a co-irrational number doesn’t have to be very good as an irrational number in itself, and in fact, a rational number and irrational number could together be “co-irrational” to each other (like the golden ratio and 2). Also, you could have more than 2 numbers in a set that are co-irrational to each other.
The question of whether two or more numbers are coprime results in a black and white answer: a yes or a no.
The question of whether two or more numbers are co-irrational results in a grey answer. Numbers can range from not being co-irrational at all (if one is a multiple of the other), to being various levels of co-irrational, up to maximally co-irrational (again, the example of the golden ratio and 2).
So how can you tell if two numbers are co-irrational, or rather, how co-irrational they are?
Basically, divide one number by the other (doesn’t matter which is the numerator and which is the denominator) and then look at the irrationality of the resulting number. If the result is a rational number, the numbers are not co-irrational. If the result is an irrational number that is well approximated by dividing relatively small integers, the numbers are not very irrational. If the result is the golden ratio, the numbers are maximally irrational.
If you wanted to see how co-irrational 3 or more numbers were, one way could be to look at them pair-wise. You’d have to figure out how to combine the results of the multiple tests since you are testing each possible pair, but it should give you an idea of how co-irrational they were.
This might also give some thoughts on how you could come up with a set of N co-irrational numbers. Maybe gradient descent could be used to find N numbers that when looked at pairwise, gave the results closest to the golden ratio, and made the error be evenly split up between the pairs.
This section is light on evidence / experimentation / etc, but the post is already getting pretty long. It could be fun to look more deeply at co-irrationals in a separate post.
Super Golden Ratio
Apparently there is a super golden ratio. Image below taken from this video: https://www.youtube.com/watch?v=X9DpdomPRvg
There is a short video here talking about some of it’s properties: https://www.youtube.com/watch?v=A4cN_44VOfQ

Analyzing the super golden ratio, it isn’t as irrational as the golden ratio, but it makes me curious what it might be useful for. If you find or can think of anything, I’d love to hear about it!
Here is the C++ code to calculate it that you can copy & paste
static const double c_superGoldenRatio = ( std::pow((29.0 + 3.0 * std::sqrt(93.0)) / 2.0, 1.0 / 3.0) + std::pow((29.0 - 3.0 * std::sqrt(93.0)) / 2.0, 1.0 / 3.0) + 1.0 ) / 3.0;
Here is the continued fraction:
1.465571 = [1, 2, 6, 1, 3, 5, 4, 22, 1, 1, 4, 1, 2, 83, 1, 1, 1, 25, 11, 1]
Here is the same test done as before on the circle and number line.
Links
This is a really great read by Martin Roberts (https://twitter.com/TechSparx) talking about generalizing the golden ratio and using that generalization for multi dimensional low discrepancy sequences, that is competitive with Sobol.
http://extremelearning.com.au/unreasonable-effectiveness-of-quasirandom-sequences/
This talks about whether adding irrational numbers together or multiplying them together results in an irrational number:
https://mathbitsnotebook.com/Algebra1/RatIrratNumbers/RNRationalSumProduct.html?s=09
This talks about how we know that e+pi is irrational or e*pi is irrational, or both, but that’s all we can say about it:
http://mathforum.org/library/drmath/view/51617.html
This shows a link between primes, Pascal’s triangle, and constructable polygons:
https://en.wikipedia.org/wiki/Constructible_polygon
Here is an alternate take on how to measure co-irrationality:
https://twitter.com/R4_Unit/status/1284588140473155585?s=20
Legend has it that a man named Hippasus was killed by Pythagorean cultists for proving the existence of irrational numbers, which destroyed their world view that all numbers were rational.
Here’s a video about that:
https://www.youtube.com/watch?v=sbGjr_awePE
Here’s an article:
https://nrich.maths.org/2671
Here’s another article:
http://kiwihellenist.blogspot.com/2015/11/were-greeks-scared-of-irrational-numbers.html
And another:
https://io9.gizmodo.com/did-pythagoras-really-murder-a-guy-1460668208
Numberphile has a nice video on the irrationality of phi too: https://www.youtube.com/watch?v=sj8Sg8qnjOg
Code that goes with this page (made the gifs) is at: https://github.com/Atrix256/IrrationalNumbers
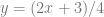 for random numbers x being between 0 and 1. Being a PDF, that function integrates to 1 over that domain of x being from 0 to 1. For the purposes of rejection sampling, we want this function to be at most 1, instead of integrating to 1, so we are going to use the probability function
for random numbers x being between 0 and 1. Being a PDF, that function integrates to 1 over that domain of x being from 0 to 1. For the purposes of rejection sampling, we want this function to be at most 1, instead of integrating to 1, so we are going to use the probability function 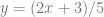
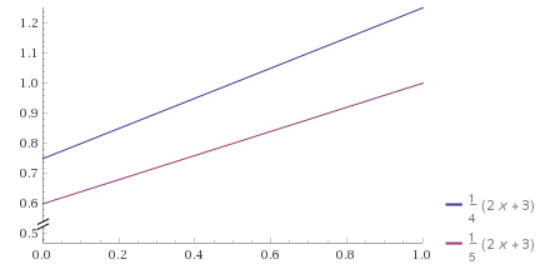

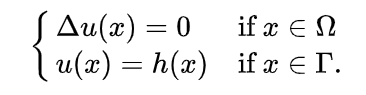
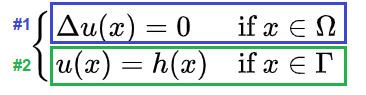
 which has a Laplacian of 0.
which has a Laplacian of 0.
 which has a Laplacian of 0.
which has a Laplacian of 0.