Never put off til run time what can be done at compile time.
C++11 gave us constexpr which lets us make C++ code that the compiler can run during compilation, instead of at runtime.
This is great because now we can use C++ to do some things that we previously had to use macros or templates for.
As with many of the newish C++ features, it feels like there are some rough edges to work out with constexpr, but it adds a lot of new exciting capabilities.
In this post we will explore some new possibilities, and get a better feel for this new world of compile time code execution. There are going to be some unexpected surprises along the way 😛
Testing Details
The code in this post will be using some compile time crc code I found at Github Gist: oktal/compile-time-crc32.cc. I haven’t tested it for correctness or speed, but it serves the purpose of being a compile time hash implementation that allows us to explore things a bit.
I’ve compiled and analyzed the code in this post in visual studio 2015, in both debug/release and x86/x64. There are differences in behavior between debug and release of course, but x86 and x64 behaved the same. If you have different results with different compilers or different code, please share!
With that out of the way, onto the fun!
We are going to be looking at:
- Simple Compile Time Hashing Behavior
- Compile Time Hash Switching
- Leveraging Jump Tables
- Perfect Hashing
- Minimally Perfect Hashing
- Compile Time Assisted String To Enum
Simple Compile Time Hashing Behavior
Let’s analyze some basic cases of trying to do some compile time hashing
const char *hello1String = "Hello1";
unsigned int hashHello1 = crc32(hello1String); // 1) Always Run Time.
unsigned int hashHello2 = crc32("Hello2"); // 2) Always Run Time.
// 3) error C2131: expression did not evaluate to a constant
//const char *hello3String = "Hello3";
//constexpr unsigned int hashHello3 = crc32(hello3String);
constexpr unsigned int hashHello4 = crc32("Hello4"); // 4) Debug: Run Time. Release: Compile Time
printf("%X %X %X %Xn", hashHello1, hashHello2, hashHello4, crc32("hello5")); // 5) Always Run Time. (!!!)
Let’s take a look at the assembly for the above code when compiled in debug. The assembly line calls to crc32 are highlighted for clarity.
const char *hello1String = "Hello1";
00007FF717B71C3E lea rax,[string "Hello1" (07FF717B7B124h)]
00007FF717B71C45 mov qword ptr [hello1String],rax
unsigned int hashHello1 = crc32(hello1String); // 1) Always Run Time.
00007FF717B71C49 xor edx,edx
00007FF717B71C4B mov rcx,qword ptr [hello1String]
00007FF717B71C4F call crc32 (07FF717B710C3h)
00007FF717B71C54 mov dword ptr [hashHello1],eax
unsigned int hashHello2 = crc32("Hello2"); // 2) Always Run Time.
00007FF717B71C57 xor edx,edx
00007FF717B71C59 lea rcx,[string "Hello2" (07FF717B7B12Ch)]
00007FF717B71C60 call crc32 (07FF717B710C3h)
00007FF717B71C65 mov dword ptr [hashHello2],eax
// 3) error C2131: expression did not evaluate to a constant
//const char *hello3String = "Hello3";
//constexpr unsigned int hashHello3 = crc32(hello3String);
constexpr unsigned int hashHello4 = crc32("Hello4"); // 4) Debug: Run Time. Release: Compile Time
00007FF717B71C68 xor edx,edx
00007FF717B71C6A lea rcx,[string "Hello4" (07FF717B7B134h)]
00007FF717B71C71 call crc32 (07FF717B710C3h)
00007FF717B71C76 mov dword ptr [hashHello4],eax
printf("%X %X %X %Xn", hashHello1, hashHello2, hashHello4, crc32("hello5")); // 5) Always Run Time. (!!!)
00007FF717B71C79 xor edx,edx
00007FF717B71C7B lea rcx,[string "hello5" (07FF717B7B13Ch)]
00007FF717B71C82 call crc32 (07FF717B710C3h)
00007FF717B71C87 mov dword ptr [rsp+20h],eax
00007FF717B71C8B mov r9d,0BECA76E1h
00007FF717B71C91 mov r8d,dword ptr [hashHello2]
00007FF717B71C95 mov edx,dword ptr [hashHello1]
00007FF717B71C98 lea rcx,[string "%X %X %X %Xn" (07FF717B7B150h)]
00007FF717B71C9F call printf (07FF717B711FEh)
As you can see, there is a “call crc32” in the assembly for every place that we call crc32 in the c++ code – 4 crc32 calls in the c++, and 4 crc32 calls in the asm. That means that all of these crc32 calls happen at run time while in debug mode.
I can sort of see the reasoning for always doing constexpr at runtime in debug mode, since you probably want to be able to step through constexpr functions to see how they operate. I’d bet that is the reasoning here.
Let’s see what it compiles to in release. Release is a little bit harder to understand since the optimizations make it difficult/impossible to pair the c++ lines with the asm.
00007FF68DC010BA lea rdx,[string "Hello1"+1h (07FF68DC02211h)]
00007FF68DC010C1 mov ecx,7807C9A2h
00007FF68DC010C6 call crc32_rec (07FF68DC01070h)
00007FF68DC010CB lea rdx,[string "Hello2"+1h (07FF68DC02219h)]
00007FF68DC010D2 mov ecx,7807C9A2h
00007FF68DC010D7 mov edi,eax
00007FF68DC010D9 call crc32_rec (07FF68DC01070h)
00007FF68DC010DE lea rdx,[string "hello5"+1h (07FF68DC02221h)]
00007FF68DC010E5 mov ecx,4369E96Ah
00007FF68DC010EA mov ebx,eax
00007FF68DC010EC call crc32_rec (07FF68DC01070h)
00007FF68DC010F1 mov r9d,0BECA76E1h
00007FF68DC010F7 mov dword ptr [rsp+20h],eax
00007FF68DC010FB mov r8d,ebx
00007FF68DC010FE lea rcx,[string "%X %X %X %Xn" (07FF68DC02228h)]
00007FF68DC01105 mov edx,edi
00007FF68DC01107 call printf (07FF68DC01010h)
We can see that in release, there are still 3 calls to crc32 which means that only one hash actually happens at compile time.
From the assembly we can easily see that “Hello1”, “Hello2” and “Hello5” are hashed at runtime. The assembly shows those strings as parameters to the function.
That leaves only “Hello4” remaining, which means that is the one that got hashed at compile time. You can actually see that on line 12, the value 0x0BECA76E1 is being moved into register r9d. If you step through the code in debug mode, you can see that the value of hashHello4 is actually 0x0BECA76E1, so that “move constant into register” on line 12 is the result of our hash happening at compile time. Pretty neat right?
I was actually surprised to see how many hashes remained happening at run time though, especially the one that is a parameter to printf. There really is no reason I can think of why they would need to remain happening at run time, versus happening at compile time, other than (this?) compiler not aggressively moving whatever it can to compile time. I really wish it worked more like that though, and IMO I think it should. Maybe in the future we’ll see compilers move more that direction.
Compile Time Hash Switching
Something neat about being able to do hashing at compile time, is that you can use the result of a compile time hash as a case value in a switch statement!
Let’s explore that a bit:
unsigned int hash = crc32("Hello1"); // 1) Run Time.
constexpr unsigned int hashTestHello2 = crc32("Hello2"); // 2) Debug: Run Time. Release: Not calculated at all.
switch (hash) { // 3) Uses variable on stack
case hashTestHello2: { // 4) Compile Time Constant.
printf("An");
break;
}
case crc32("Hello3"): { // 5) Compile Time Constant.
printf("Bn");
break;
}
// 6) error C2196: case value '1470747604' already used
/*
case crc32("Hello2"): {
printf("Cn");
break;
}
*/
default: {
printf("Cn");
break;
}
}
Something interesting to note is that if you have duplicate cases in your switch statement, due to things hashing to the same value (either duplicates, or actual hash collisions) that you will get a compile time error. This might come in handy, let’s come back to that later.
Let’s look at the assembly code in debug:
unsigned int hash = crc32("Hello1"); // 1) Run Time.
00007FF77B4119FE xor edx,edx
00007FF77B411A00 lea rcx,[string "Hello1" (07FF77B41B124h)]
00007FF77B411A07 call crc32 (07FF77B4110C3h)
00007FF77B411A0C mov dword ptr [hash],eax
constexpr unsigned int hashTestHello2 = crc32("Hello2"); // 2) Debug: Run Time. Release: Not calculated at all.
00007FF77B411A0F xor edx,edx
00007FF77B411A11 lea rcx,[string "Hello2" (07FF77B41B12Ch)]
00007FF77B411A18 call crc32 (07FF77B4110C3h)
00007FF77B411A1D mov dword ptr [hashTestHello2],eax
switch (hash) { // 3) Uses variable on stack
00007FF77B411A20 mov eax,dword ptr [hash]
00007FF77B411A23 mov dword ptr [rbp+0F4h],eax
00007FF77B411A29 cmp dword ptr [rbp+0F4h],20AEE342h
00007FF77B411A33 je Snippet_CompileTimeHashSwitching1+71h (07FF77B411A51h)
00007FF77B411A35 cmp dword ptr [rbp+0F4h],57A9D3D4h
00007FF77B411A3F je Snippet_CompileTimeHashSwitching1+63h (07FF77B411A43h)
00007FF77B411A41 jmp Snippet_CompileTimeHashSwitching1+7Fh (07FF77B411A5Fh)
case hashTestHello2: { // 4) Compile Time Constant.
printf("An");
00007FF77B411A43 lea rcx,[string "An" (07FF77B41B144h)]
00007FF77B411A4A call printf (07FF77B4111FEh)
break;
00007FF77B411A4F jmp Snippet_CompileTimeHashSwitching1+8Bh (07FF77B411A6Bh)
}
case crc32("Hello3"): { // 5) Compile Time Constant.
printf("Bn");
00007FF77B411A51 lea rcx,[string "Bn" (07FF77B41B160h)]
00007FF77B411A58 call printf (07FF77B4111FEh)
break;
00007FF77B411A5D jmp Snippet_CompileTimeHashSwitching1+8Bh (07FF77B411A6Bh)
}
// 6) error C2196: case value '1470747604' already used
/*
case crc32("Hello2"): {
printf("Cn");
break;
}
*/
default: {
printf("Cn");
00007FF77B411A5F lea rcx,[string "Cn" (07FF77B41B164h)]
00007FF77B411A66 call printf (07FF77B4111FEh)
break;
}
}
We can see that the hash for “Hello1” and “Hello2” are both calculated at run time, and that the switch statement uses the stack variable [hash] to move the value into a register to do the switch statement.
Interestingly though, on lines 14 and 16 we can see it moving a constant value into registers to use in a cmp (compare) operation. 0x20AEE342 is the hash value of “Hello3” and 0x57A9D3D4 is the hash value of “Hello2” so it ended up doing those hashes at compile time, even though we are in debug mode. This is because case values must be known at compile time.
It’s interesting to see though that the compiler calculates hashTestHello2 at runtime, even though the only place we use it (in the case statement), it puts a compile time constant from a compile time hash. Odd.
Let’s see what happens in release:
00007FF7FA9B10B4 lea rdx,[string "Hello1"+1h (07FF7FA9B2211h)]
00007FF7FA9B10BB mov ecx,7807C9A2h
00007FF7FA9B10C0 call crc32_rec (07FF7FA9B1070h)
00007FF7FA9B10C5 cmp eax,20AEE342h
00007FF7FA9B10CA je main+49h (07FF7FA9B10F9h)
00007FF7FA9B10CC cmp eax,57A9D3D4h
00007FF7FA9B10D1 je main+36h (07FF7FA9B10E6h)
00007FF7FA9B10D3 lea rcx,[string "Cn" (07FF7FA9B2220h)]
00007FF7FA9B10DA call printf (07FF7FA9B1010h)
// ... More asm code below, but not relevant
Release is a little more lean which is nice. On line 3 we calculate the hash of “Hello1” at runtime, then on lines 4 and 6, we compare it against the constant values of our compile time hashes for “Hello2” and “Hello3”. That is all that is done at runtime, which is more in line with what we’d like to see the compiler do. It’s still a little bit lame that it didn’t see that “Hello1” was a compile time constant that was being hashed, and did it at runtime, but at least it got most of the hashing to happen at compile time.
What if we change the “hash” variable to be constexpr?
// Release: this function just prints "Cn" and exits. All code melted away at compile time!
constexpr unsigned int hash = crc32("Hello1"); // 1) Debug: Run Time
constexpr unsigned int hashTestHello2 = crc32("Hello2"); // 2) Debug: Run Time
switch (hash) { // 3) Debug: Compile Time Constant.
case hashTestHello2: { // 4) Debug: Compile Time Constant.
printf("An");
break;
}
case crc32("Hello3"): { // 5) Debug: Compile Time Constant.
printf("Bn");
break;
}
default: {
printf("Cn");
break;
}
}
Let’s check it out in debug first:
constexpr unsigned int hash = crc32("Hello1"); // 1) Debug: Run Time
00007FF71F7A1ABE xor edx,edx
00007FF71F7A1AC0 lea rcx,[string "Hello1" (07FF71F7AB124h)]
00007FF71F7A1AC7 call crc32 (07FF71F7A10C3h)
00007FF71F7A1ACC mov dword ptr [hash],eax
constexpr unsigned int hashTestHello2 = crc32("Hello2"); // 2) Debug: Run Time
00007FF71F7A1ACF xor edx,edx
00007FF71F7A1AD1 lea rcx,[string "Hello2" (07FF71F7AB12Ch)]
00007FF71F7A1AD8 call crc32 (07FF71F7A10C3h)
00007FF71F7A1ADD mov dword ptr [hashTestHello2],eax
switch (hash) { // 3) Debug: Compile Time Constant.
00007FF71F7A1AE0 mov dword ptr [rbp+0F4h],0CEA0826Eh
00007FF71F7A1AEA cmp dword ptr [rbp+0F4h],20AEE342h
00007FF71F7A1AF4 je Snippet_CompileTimeHashSwitching2+72h (07FF71F7A1B12h)
00007FF71F7A1AF6 cmp dword ptr [rbp+0F4h],57A9D3D4h
00007FF71F7A1B00 je Snippet_CompileTimeHashSwitching2+64h (07FF71F7A1B04h)
00007FF71F7A1B02 jmp Snippet_CompileTimeHashSwitching2+80h (07FF71F7A1B20h)
case hashTestHello2: { // 4) Debug: Compile Time Constant.
printf("An");
00007FF71F7A1B04 lea rcx,[string "An" (07FF71F7AB144h)]
case hashTestHello2: { // 4) Debug: Compile Time Constant.
printf("An");
00007FF71F7A1B0B call printf (07FF71F7A11FEh)
break;
00007FF71F7A1B10 jmp Snippet_CompileTimeHashSwitching2+8Ch (07FF71F7A1B2Ch)
}
case crc32("Hello3"): { // 5) Debug: Compile Time Constant.
printf("Bn");
00007FF71F7A1B12 lea rcx,[string "Bn" (07FF71F7AB160h)]
00007FF71F7A1B19 call printf (07FF71F7A11FEh)
break;
00007FF71F7A1B1E jmp Snippet_CompileTimeHashSwitching2+8Ch (07FF71F7A1B2Ch)
}
default: {
printf("Cn");
00007FF71F7A1B20 lea rcx,[string "Cn" (07FF71F7AB164h)]
00007FF71F7A1B27 call printf (07FF71F7A11FEh)
break;
}
}
The code does a runtime hash of “Hello1” and “Hello2” on lines 4 and 9. Then, on line 12, it moves the compile time hash value of “Hello1” into memory. On line 13 it compares that against the compile time hash value of “Hello3”. On line 15 it compares it against the compile time hash value of “Hello2”.
Now let’s check release:
00007FF7B7B91074 lea rcx,[string "Cn" (07FF7B7B92210h)]
00007FF7B7B9107B call printf (07FF7B7B91010h)
Awesome! It was able to do ALL calculation at compile time, and only do the printf at run time. Neat!
As one final test, let’s see what happens when we put a crc32 call straight into the switch statement.
constexpr unsigned int hashTestHello2 = crc32("Hello2"); // 1) Debug: Run Time. Release: Not calculated at all.
switch (crc32("Hello1")) { // 2) Always Run Time (!!!)
case hashTestHello2: { // 3) Compile Time Constant.
printf("An");
break;
}
case crc32("Hello3"): { // 4) Compile Time Constant.
printf("Bn");
break;
}
default: {
printf("Cn");
break;
}
}
Here’s the debug assembly:
constexpr unsigned int hashTestHello2 = crc32("Hello2"); // 1) Debug: Run Time. Release: Not calculated at all.
00007FF72ED51B7E xor edx,edx
00007FF72ED51B80 lea rcx,[string "Hello2" (07FF72ED5B12Ch)]
00007FF72ED51B87 call crc32 (07FF72ED510C3h)
00007FF72ED51B8C mov dword ptr [hashTestHello2],eax
switch (crc32("Hello1")) { // 2) Always Run Time (!!!)
00007FF72ED51B8F xor edx,edx
00007FF72ED51B91 lea rcx,[string "Hello1" (07FF72ED5B124h)]
00007FF72ED51B98 call crc32 (07FF72ED510C3h)
00007FF72ED51B9D mov dword ptr [rbp+0D4h],eax
00007FF72ED51BA3 cmp dword ptr [rbp+0D4h],20AEE342h
00007FF72ED51BAD je Snippet_CompileTimeHashSwitching3+6Bh (07FF72ED51BCBh)
00007FF72ED51BAF cmp dword ptr [rbp+0D4h],57A9D3D4h
00007FF72ED51BB9 je Snippet_CompileTimeHashSwitching3+5Dh (07FF72ED51BBDh)
00007FF72ED51BBB jmp Snippet_CompileTimeHashSwitching3+79h (07FF72ED51BD9h)
case hashTestHello2: { // 3) Compile Time Constant.
printf("An");
00007FF72ED51BBD lea rcx,[string "An" (07FF72ED5B144h)]
00007FF72ED51BC4 call printf (07FF72ED511FEh)
break;
00007FF72ED51BC9 jmp Snippet_CompileTimeHashSwitching3+85h (07FF72ED51BE5h)
}
case crc32("Hello3"): { // 4) Compile Time Constant.
printf("Bn");
00007FF72ED51BCB lea rcx,[string "Bn" (07FF72ED5B160h)]
00007FF72ED51BD2 call printf (07FF72ED511FEh)
break;
00007FF72ED51BD7 jmp Snippet_CompileTimeHashSwitching3+85h (07FF72ED51BE5h)
}
default: {
printf("Cn");
00007FF72ED51BD9 lea rcx,[string "Cn" (07FF72ED5B164h)]
00007FF72ED51BE0 call printf (07FF72ED511FEh)
break;
}
}
It was able to do the case value crc’s at compile time, but the other two it did at runtime. Not surprising for debug. Let’s check release:
00007FF6A46D10B4 lea rdx,[string "Hello1"+1h (07FF6A46D2211h)]
00007FF6A46D10BB mov ecx,7807C9A2h
00007FF6A46D10C0 call crc32_rec (07FF6A46D1070h)
00007FF6A46D10C5 cmp eax,20AEE342h
00007FF6A46D10CA je main+49h (07FF6A46D10F9h)
00007FF6A46D10CC cmp eax,57A9D3D4h
00007FF6A46D10D1 je main+36h (07FF6A46D10E6h)
00007FF6A46D10D3 lea rcx,[string "Cn" (07FF6A46D2220h)]
00007FF6A46D10DA call printf (07FF6A46D1010h)
// ... More asm code below, but not relevant
It did the hash for “Hello1” at run time (why??), but it did the others at release. A bit disappointing that it couldn’t make the “Hello1” hash be compile time, but we saw this behavior before so nothing new there.
Leveraging Jump Tables
In the above switch statements, the tests for hashes were very much “If hash is a, do this, else if hash is b, do that”. It was an if/else if/else if style chain.
Switch statements actually have the ability to become jump tables though, which let them get to the right case value with fewer comparisons.
Check out this code:
// Debug: Jump Table
// Release: Just does the constant case, everything else goes away
unsigned int i = 3;
switch (i) {
case 0: printf("An"); break;
case 1: printf("Bn"); break;
case 2: printf("Cn"); break;
case 3: printf("Dn"); break;
case 4: printf("En"); break;
case 5: printf("Fn"); break;
case 6: printf("Gn"); break;
case 7: printf("Hn"); break;
default: printf("Nonen"); break;
}
Here’s the debug assembly:
// Debug: Jump Table
// Release: Just does the constant case, everything else goes away
unsigned int i = 3;
00007FF69CF9238E mov dword ptr [i],3
switch (i) {
00007FF69CF92395 mov eax,dword ptr [i]
00007FF69CF92398 mov dword ptr [rbp+0D4h],eax
00007FF69CF9239E cmp dword ptr [rbp+0D4h],7
00007FF69CF923A5 ja $LN11+0Eh (07FF69CF92434h)
00007FF69CF923AB mov eax,dword ptr [rbp+0D4h]
00007FF69CF923B1 lea rcx,[__ImageBase (07FF69CF80000h)]
00007FF69CF923B8 mov eax,dword ptr [rcx+rax*4+1244Ch]
00007FF69CF923BF add rax,rcx
00007FF69CF923C2 jmp rax
case 0: printf("An"); break;
00007FF69CF923C4 lea rcx,[string "An" (07FF69CF9B144h)]
00007FF69CF923CB call printf (07FF69CF911FEh)
00007FF69CF923D0 jmp $LN11+1Ah (07FF69CF92440h)
case 1: printf("Bn"); break;
00007FF69CF923D2 lea rcx,[string "Bn" (07FF69CF9B160h)]
00007FF69CF923D9 call printf (07FF69CF911FEh)
00007FF69CF923DE jmp $LN11+1Ah (07FF69CF92440h)
case 2: printf("Cn"); break;
00007FF69CF923E0 lea rcx,[string "Cn" (07FF69CF9B164h)]
00007FF69CF923E7 call printf (07FF69CF911FEh)
00007FF69CF923EC jmp $LN11+1Ah (07FF69CF92440h)
case 3: printf("Dn"); break;
00007FF69CF923EE lea rcx,[string "Dn" (07FF69CF9B168h)]
00007FF69CF923F5 call printf (07FF69CF911FEh)
00007FF69CF923FA jmp $LN11+1Ah (07FF69CF92440h)
case 4: printf("En"); break;
00007FF69CF923FC lea rcx,[string "En" (07FF69CF9B16Ch)]
00007FF69CF92403 call printf (07FF69CF911FEh)
00007FF69CF92408 jmp $LN11+1Ah (07FF69CF92440h)
case 5: printf("Fn"); break;
00007FF69CF9240A lea rcx,[string "Fn" (07FF69CF9B170h)]
00007FF69CF92411 call printf (07FF69CF911FEh)
00007FF69CF92416 jmp $LN11+1Ah (07FF69CF92440h)
case 6: printf("Gn"); break;
00007FF69CF92418 lea rcx,[string "Gn" (07FF69CF9B174h)]
00007FF69CF9241F call printf (07FF69CF911FEh)
00007FF69CF92424 jmp $LN11+1Ah (07FF69CF92440h)
case 7: printf("Hn"); break;
00007FF69CF92426 lea rcx,[string "Hn" (07FF69CF9B178h)]
00007FF69CF9242D call printf (07FF69CF911FEh)
00007FF69CF92432 jmp $LN11+1Ah (07FF69CF92440h)
default: printf("Nonen"); break;
00007FF69CF92434 lea rcx,[string "Nonen" (07FF69CF9AFDCh)]
00007FF69CF9243B call printf (07FF69CF911FEh)
}
On line 8 and 9 it checks to see if the value we are switching on is greater than 7, and if so, jumps to 07FF69CF92434h, which is the “default” case where it prints “None”.
If the number is not greater than 7, it calculates an address based on the value we are switching on, and then jumps to it, on line 14.
Instead of testing for every possible value in an if/else if/else if/else if type setup, it can go IMMEDIATELY to the code associated with the particular case statement.
This is a jump table and can be a big speed improvement if you have a lot of cases, or if the code is called a lot.
I’ll spare you the release assembly. The compiler can tell that this is a compile time known result and only has the printf for the “D” without any of the other logic.
Let’s go back to our crc32 code and try and leverage a jump table:
// Debug / Release: Does hash and jump table.
// Note: It AND's against 7 and then tests to see if i is greater than 7 (!!!)
unsigned int i = crc32("Hello") & 7;
switch (i) {
case 0: printf("An"); break;
case 1: printf("Bn"); break;
case 2: printf("Cn"); break;
case 3: printf("Dn"); break;
case 4: printf("En"); break;
case 5: printf("Fn"); break;
case 6: printf("Gn"); break;
case 7: printf("Hn"); break;
default: printf("Nonen"); break;
}
I’ll show you just the debug assembly for brevity. It does the hash and jump table at runtime for both debug and release. Interestingly, even though we do &7 on the hash value, the switch statement STILL makes sure that the value being switched on is not greater than 7. It can never be greater than 7, and that can be known at compile time, but it still checks. This is true even of the release assembly!
// Debug / Release: Does hash and jump table.
// Note: It AND's against 7 and then tests to see if i is greater than 7 (!!!)
unsigned int i = crc32("Hello") & 7;
00007FF7439C24CE xor edx,edx
00007FF7439C24D0 lea rcx,[string "Hello" (07FF7439CB180h)]
00007FF7439C24D7 call crc32 (07FF7439C10C3h)
00007FF7439C24DC and eax,7
00007FF7439C24DF mov dword ptr [i],eax
switch (i) {
00007FF7439C24E2 mov eax,dword ptr [i]
00007FF7439C24E5 mov dword ptr [rbp+0D4h],eax
00007FF7439C24EB cmp dword ptr [rbp+0D4h],7
00007FF7439C24F2 ja $LN11+0Eh (07FF7439C2581h)
00007FF7439C24F8 mov eax,dword ptr [rbp+0D4h]
00007FF7439C24FE lea rcx,[__ImageBase (07FF7439B0000h)]
00007FF7439C2505 mov eax,dword ptr [rcx+rax*4+12598h]
00007FF7439C250C add rax,rcx
00007FF7439C250F jmp rax
case 0: printf("An"); break;
00007FF7439C2511 lea rcx,[string "An" (07FF7439CB144h)]
case 0: printf("An"); break;
00007FF7439C2518 call printf (07FF7439C11FEh)
00007FF7439C251D jmp $LN11+1Ah (07FF7439C258Dh)
case 1: printf("Bn"); break;
00007FF7439C251F lea rcx,[string "Bn" (07FF7439CB160h)]
00007FF7439C2526 call printf (07FF7439C11FEh)
00007FF7439C252B jmp $LN11+1Ah (07FF7439C258Dh)
case 2: printf("Cn"); break;
00007FF7439C252D lea rcx,[string "Cn" (07FF7439CB164h)]
00007FF7439C2534 call printf (07FF7439C11FEh)
00007FF7439C2539 jmp $LN11+1Ah (07FF7439C258Dh)
case 3: printf("Dn"); break;
00007FF7439C253B lea rcx,[string "Dn" (07FF7439CB168h)]
00007FF7439C2542 call printf (07FF7439C11FEh)
00007FF7439C2547 jmp $LN11+1Ah (07FF7439C258Dh)
case 4: printf("En"); break;
00007FF7439C2549 lea rcx,[string "En" (07FF7439CB16Ch)]
00007FF7439C2550 call printf (07FF7439C11FEh)
00007FF7439C2555 jmp $LN11+1Ah (07FF7439C258Dh)
case 5: printf("Fn"); break;
00007FF7439C2557 lea rcx,[string "Fn" (07FF7439CB170h)]
00007FF7439C255E call printf (07FF7439C11FEh)
00007FF7439C2563 jmp $LN11+1Ah (07FF7439C258Dh)
case 6: printf("Gn"); break;
00007FF7439C2565 lea rcx,[string "Gn" (07FF7439CB174h)]
00007FF7439C256C call printf (07FF7439C11FEh)
00007FF7439C2571 jmp $LN11+1Ah (07FF7439C258Dh)
case 7: printf("Hn"); break;
00007FF7439C2573 lea rcx,[string "Hn" (07FF7439CB178h)]
00007FF7439C257A call printf (07FF7439C11FEh)
00007FF7439C257F jmp $LN11+1Ah (07FF7439C258Dh)
default: printf("Nonen"); break;
00007FF7439C2581 lea rcx,[string "Nonen" (07FF7439CAFDCh)]
00007FF7439C2588 call printf (07FF7439C11FEh)
}
If we make “i” be a constexpr variable, it doesn’t affect debug, but in release, it is able to melt away all the code and just prints the correct case.
00007FF6093F1074 lea rcx,[string "An" (07FF6093F2210h)]
00007FF6093F107B call printf (07FF6093F1010h)
Perfect Hashing
Perfect hashing is when you have a known set of inputs, and a hash function such that there is no collision between any of the inputs.
Perfect hashing can be great for being able to turn complex objects into IDs for faster lookup times, but the IDs are not usually going to be contiguous. One ID might be 3, and another might be 45361. Perfect hashing can still be useful though.
The code below shows show some compile time perfect hashing could be achieved.
// Debug: Does have some sort of jump table setup, despite the cases not being continuous.
// Release: prints "An". All other code melts away at compile time.
static const unsigned int c_numBuckets = 16;
static const unsigned int c_salt = 1337;
constexpr unsigned int i = crc32("Identifier_A", c_salt) % c_numBuckets;
switch (i) {
case (crc32("Identifier_A", c_salt) % c_numBuckets): printf("An"); break;
case (crc32("Identifier_B", c_salt) % c_numBuckets): printf("Bn"); break;
case (crc32("Identifier_C", c_salt) % c_numBuckets): printf("Cn"); break;
case (crc32("Identifier_D", c_salt) % c_numBuckets): printf("Dn"); break;
case (crc32("Identifier_E", c_salt) % c_numBuckets): printf("En"); break;
case (crc32("Identifier_F", c_salt) % c_numBuckets): printf("Fn"); break;
case (crc32("Identifier_G", c_salt) % c_numBuckets): printf("Gn"); break;
case (crc32("Identifier_H", c_salt) % c_numBuckets): printf("Hn"); break;
default: printf("Nonen"); break;
}
One nice thing about doing perfect hashing at compile time like this is that if you ever have a hash collision, you’ll have a duplicate case in your switch statement, and will get a compile error. This means that you are guaranteed that your perfect hash is valid at runtime. With non compile time perfect hashes, you could easily get into a situation where you added some more valid inputs and may now have a hash collision, which would make hard to track subtle bugs as two input values would be sharing the same index for whatever read and/or write data they wanted to interact with.
You might notice that i am doing %16 on the hash instead of %8, even though there are only 8 items I want to test against.
The reason for that is hash collisions.
When you hash a string you are effectively getting a pseudo random number back that will always be the same for when that string is given as input.
For the above to work correctly and let me modulus against 8, i would have to roll an 8 sided dice 8 times and get no repeats.
There are 8! (8 factorial) different ways to roll that 8 sided dice 8 times and not get any collisions.
There are 8^8 different ways to roll the 8 sided dice 8 times total.
To get the chance that we roll an 8 sided dice 8 times and get no repeats (no hash collisions), the probability is 8! / 8^8 or 0.24%.
The salt in the crc32 function allows us to effectively re-roll our dice. Each salt value is a different roll of the dice.
How that fits in is that 0.24% of all salt values should let us be able to do %8 on our hashes and not have a hash collision.
Those odds are pretty bad, but they aren’t SUPER bad. We could just brute force search to find a good salt value to use and then hard code the salt in, like i did in the example above.
Unfortunately, the probability I calculated above only works if the hash function gives uniformly distributed output and is “truly random”.
In practice no hash function or pseudo random number generator is, and in fact this crc32 function has NO salt values which make for no collisions! I brute force tested all 2^32 (4.2 billion) possible salt values and came up with no salt that worked!
To get around that problem, instead of trying to get a perfect fit of 8 hashes with values 0-7 without collisions, i opted to go for 8 hashes with values 0-15 with no collisions. That changes my odds for the better, and there are in fact many salts that satisfy that.
It’s the equivalent of rolling a 16 sided dice 8 times without repeats.
Thinking about things a bit differently than before, the first roll has a 100% chance of not being a duplicate. The next roll has a 15/16 chance of not being duplicate. The next has a 14/16 chance and so on until the 8th roll which has a 9/16 chance.
Multiplying those all together, we end up with a 12.08% chance of rolling a 16 sided dice 8 times and not getting a duplicate. That means 12% of the salts (about 1 in 9) won’t produce collisions when we use 16 buckets, which makes it much easier for us to find a salt to use.
Looking at the disassembly in debug, we can see the jump table is miraculously in tact! This is great because now we can get compile time assured perfect hashing of objects, and can use a jump table to convert a runtime object into a perfect hash result.
Note that in release, the code melts away and just does the “correct printf”.
// Debug: Does have some sort of jump table setup, despite the cases not being continuous.
// Release: prints "An". All other code melts away at compile time.
static const unsigned int c_numBuckets = 16;
static const unsigned int c_salt = 1337;
constexpr unsigned int i = crc32("Identifier_A", c_salt) % c_numBuckets;
00007FF7CE651E5E mov edx,539h
00007FF7CE651E63 lea rcx,[string "Identifier_A" (07FF7CE65B190h)]
00007FF7CE651E6A call crc32 (07FF7CE6510C3h)
00007FF7CE651E6F xor edx,edx
00007FF7CE651E71 mov ecx,10h
00007FF7CE651E76 div eax,ecx
00007FF7CE651E78 mov eax,edx
00007FF7CE651E7A mov dword ptr [i],eax
switch (i) {
00007FF7CE651E7D mov dword ptr [rbp+0D4h],4
00007FF7CE651E87 cmp dword ptr [rbp+0D4h],0Eh
00007FF7CE651E8E ja $LN11+0Eh (07FF7CE651F1Dh)
00007FF7CE651E94 mov eax,dword ptr [rbp+0D4h]
00007FF7CE651E9A lea rcx,[__ImageBase (07FF7CE640000h)]
00007FF7CE651EA1 mov eax,dword ptr [rcx+rax*4+11F34h]
00007FF7CE651EA8 add rax,rcx
00007FF7CE651EAB jmp rax
case (crc32("Identifier_A", c_salt) % c_numBuckets): printf("An"); break;
00007FF7CE651EAD lea rcx,[string "An" (07FF7CE65B144h)]
00007FF7CE651EB4 call printf (07FF7CE6511FEh)
00007FF7CE651EB9 jmp $LN11+1Ah (07FF7CE651F29h)
case (crc32("Identifier_B", c_salt) % c_numBuckets): printf("Bn"); break;
00007FF7CE651EBB lea rcx,[string "Bn" (07FF7CE65B160h)]
00007FF7CE651EC2 call printf (07FF7CE6511FEh)
00007FF7CE651EC7 jmp $LN11+1Ah (07FF7CE651F29h)
case (crc32("Identifier_C", c_salt) % c_numBuckets): printf("Cn"); break;
00007FF7CE651EC9 lea rcx,[string "Cn" (07FF7CE65B164h)]
00007FF7CE651ED0 call printf (07FF7CE6511FEh)
00007FF7CE651ED5 jmp $LN11+1Ah (07FF7CE651F29h)
case (crc32("Identifier_D", c_salt) % c_numBuckets): printf("Dn"); break;
00007FF7CE651ED7 lea rcx,[string "Dn" (07FF7CE65B168h)]
00007FF7CE651EDE call printf (07FF7CE6511FEh)
00007FF7CE651EE3 jmp $LN11+1Ah (07FF7CE651F29h)
case (crc32("Identifier_E", c_salt) % c_numBuckets): printf("En"); break;
00007FF7CE651EE5 lea rcx,[string "En" (07FF7CE65B16Ch)]
00007FF7CE651EEC call printf (07FF7CE6511FEh)
00007FF7CE651EF1 jmp $LN11+1Ah (07FF7CE651F29h)
case (crc32("Identifier_F", c_salt) % c_numBuckets): printf("Fn"); break;
00007FF7CE651EF3 lea rcx,[string "Fn" (07FF7CE65B170h)]
00007FF7CE651EFA call printf (07FF7CE6511FEh)
00007FF7CE651EFF jmp $LN11+1Ah (07FF7CE651F29h)
case (crc32("Identifier_G", c_salt) % c_numBuckets): printf("Gn"); break;
00007FF7CE651F01 lea rcx,[string "Gn" (07FF7CE65B174h)]
00007FF7CE651F08 call printf (07FF7CE6511FEh)
00007FF7CE651F0D jmp $LN11+1Ah (07FF7CE651F29h)
case (crc32("Identifier_H", c_salt) % c_numBuckets): printf("Hn"); break;
00007FF7CE651F0F lea rcx,[string "Hn" (07FF7CE65B178h)]
00007FF7CE651F16 call printf (07FF7CE6511FEh)
00007FF7CE651F1B jmp $LN11+1Ah (07FF7CE651F29h)
default: printf("Nonen"); break;
00007FF7CE651F1D lea rcx,[string "Nonen" (07FF7CE65AFDCh)]
00007FF7CE651F24 call printf (07FF7CE6511FEh)
}
Minimally Perfect Hashing
Minimally perfect hashing is like perfect hashing, except the results are contiguous values.
If you have 8 possible inputs to your minimally perfect hash function, you are going to get as output 0-7. The order of what inputs map to which outputs isn’t strictly defined unless you want to go through a lot of extra effort to make it be that way though.
This is even more useful than perfect hashing, as you can hash a (known good) input and use the result as an index into an array, or similar!
For more info on MPH, check out my post on it: O(1) Data Lookups With Minimal Perfect Hashing
The code below is a way of doing compile time assisted minimally perfect hashing:
// Debug / Release:
// Runs crc32 at runtime only for "i". The cases are compile time constants as per usual.
// Does a jumptable type setup for the switch and does fallthrough to do multiple increments to get the right ID.
//
// Release with constexpr on i:
// does the printf with a value of 2. The rest of the code melts away.
static const unsigned int c_numBuckets = 16;
static const unsigned int c_salt = 1337;
static const unsigned int c_invalidID = -1;
unsigned int i = crc32("Identifier_F", c_salt) % c_numBuckets;
unsigned int id = c_invalidID;
switch (i) {
case (crc32("Identifier_A", c_salt) % c_numBuckets): ++id;
case (crc32("Identifier_B", c_salt) % c_numBuckets): ++id;
case (crc32("Identifier_C", c_salt) % c_numBuckets): ++id;
case (crc32("Identifier_D", c_salt) % c_numBuckets): ++id;
case (crc32("Identifier_E", c_salt) % c_numBuckets): ++id;
case (crc32("Identifier_F", c_salt) % c_numBuckets): ++id;
case (crc32("Identifier_G", c_salt) % c_numBuckets): ++id;
case (crc32("Identifier_H", c_salt) % c_numBuckets): ++id;
// the two lines below are implicit behavior of how this code works
// break;
// default: id = c_invalidID; break;
}
printf("id = %in", id);
Here’s the debug assembly for the above. The release does similar, so i’m not showing it.
// Debug / Release:
// Runs crc32 at runtime only for "i". The cases are compile time constants as per usual.
// Does a jumptable type setup for the switch and does fallthrough to do multiple increments to get the right ID.
//
// Release with constexpr on i:
// does the printf with a value of 2. The rest of the code melts away.
static const unsigned int c_numBuckets = 16;
static const unsigned int c_salt = 1337;
static const unsigned int c_invalidID = -1;
unsigned int i = crc32("Identifier_F", c_salt) % c_numBuckets;
00007FF79E481D0E mov edx,539h
00007FF79E481D13 lea rcx,[string "Identifier_F" (07FF79E48B1E0h)]
00007FF79E481D1A call crc32 (07FF79E4810C3h)
00007FF79E481D1F xor edx,edx
00007FF79E481D21 mov ecx,10h
00007FF79E481D26 div eax,ecx
00007FF79E481D28 mov eax,edx
00007FF79E481D2A mov dword ptr [i],eax
unsigned int id = c_invalidID;
00007FF79E481D2D mov dword ptr [id],0FFFFFFFFh
switch (i) {
00007FF79E481D34 mov eax,dword ptr [i]
00007FF79E481D37 mov dword ptr [rbp+0F4h],eax
00007FF79E481D3D cmp dword ptr [rbp+0F4h],0Eh
00007FF79E481D44 ja $LN11+8h (07FF79E481D9Fh)
00007FF79E481D46 mov eax,dword ptr [rbp+0F4h]
00007FF79E481D4C lea rcx,[__ImageBase (07FF79E470000h)]
00007FF79E481D53 mov eax,dword ptr [rcx+rax*4+11DB8h]
00007FF79E481D5A add rax,rcx
00007FF79E481D5D jmp rax
case (crc32("Identifier_A", c_salt) % c_numBuckets): ++id;
00007FF79E481D5F mov eax,dword ptr [id]
00007FF79E481D62 inc eax
00007FF79E481D64 mov dword ptr [id],eax
case (crc32("Identifier_B", c_salt) % c_numBuckets): ++id;
00007FF79E481D67 mov eax,dword ptr [id]
00007FF79E481D6A inc eax
00007FF79E481D6C mov dword ptr [id],eax
case (crc32("Identifier_C", c_salt) % c_numBuckets): ++id;
00007FF79E481D6F mov eax,dword ptr [id]
00007FF79E481D72 inc eax
00007FF79E481D74 mov dword ptr [id],eax
case (crc32("Identifier_D", c_salt) % c_numBuckets): ++id;
00007FF79E481D77 mov eax,dword ptr [id]
00007FF79E481D7A inc eax
00007FF79E481D7C mov dword ptr [id],eax
case (crc32("Identifier_E", c_salt) % c_numBuckets): ++id;
00007FF79E481D7F mov eax,dword ptr [id]
00007FF79E481D82 inc eax
00007FF79E481D84 mov dword ptr [id],eax
case (crc32("Identifier_F", c_salt) % c_numBuckets): ++id;
00007FF79E481D87 mov eax,dword ptr [id]
00007FF79E481D8A inc eax
00007FF79E481D8C mov dword ptr [id],eax
case (crc32("Identifier_G", c_salt) % c_numBuckets): ++id;
00007FF79E481D8F mov eax,dword ptr [id]
00007FF79E481D92 inc eax
00007FF79E481D94 mov dword ptr [id],eax
case (crc32("Identifier_H", c_salt) % c_numBuckets): ++id;
00007FF79E481D97 mov eax,dword ptr [id]
00007FF79E481D9A inc eax
00007FF79E481D9C mov dword ptr [id],eax
// the two lines below are implicit behavior of how this code works
// break;
// default: id = c_invalidID; break;
}
printf("id = %in", id);
00007FF79E481D9F mov edx,dword ptr [id]
00007FF79E481DA2 lea rcx,[string "id = %in" (07FF79E48B238h)]
// the two lines below are implicit behavior of how this code works
// break;
// default: id = c_invalidID; break;
}
printf("id = %in", id);
00007FF79E481DA9 call printf (07FF79E4811FEh)
As you can see, the jump table is still in tact, which is good, but it does a lot of repeated increments to get the right ID values. I wish the compiler were smart enough to “flatten” this and just give each case it’s proper ID value.
As is, this could be a performance issue if you had a very large number of inputs.
You could always just hard code a number there instead of relying on the fallthrough and increment, but then there is a lot of copy pasting. Maybe you could do something clever with macros or templates to help that though.
Compile Time Assisted String To Enum
Another interesting thing to think about is that we could actually use compile time hashing to convert a string to an enum.
In this case, let’s say that we don’t know if our input is valid or not. Since we don’t know that, we have to switch on the hash of our input string, but then do a string compare against whatever string has that hash, to make sure it matches. If it does match, it should take that enum value, else it should be invalid.
Since that would be a lot of error prone copy/pasting, I simplified things a bit by using a macro list:
// Debug / Release:
// Runs crc32 at runtime only for "i". The cases are compile time constants as per usual.
// Does a jumptable type setup for the switch and does a string comparison against the correct string.
// If strings are equal, sets the enum value.
static const unsigned int c_numBuckets = 16;
static const unsigned int c_salt = 1337;
const char* testString = "Identifier_F";
unsigned int i = crc32(testString, c_salt) % c_numBuckets;
// This macro list is used for:
// * making the enum
// * making the cases in the switch statement
// D.R.Y. - Don't Repeat Yourself.
// Fewer moving parts = fewer errors, but admittedly is harder to understand vs redundant code.
#define ENUM_VALUE_LIST
VALUE(Identifier_A)
VALUE(Identifier_B)
VALUE(Identifier_C)
VALUE(Identifier_D)
VALUE(Identifier_E)
VALUE(Identifier_F)
VALUE(Identifier_G)
VALUE(Identifier_H)
// Make the enum values.
// Note these enum values are also usable as a contiguous ID if you needed one for an array index or similar.
// You could define an array with size EIdentifier::count for instance and use these IDs to index into it.
enum class EIdentifier : unsigned char {
#define VALUE(x) x,
ENUM_VALUE_LIST
#undef VALUE
count,
invalid = (unsigned char)-1
};
// do a compile time hash assisted string comparison to convert string to enum
EIdentifier identifier = EIdentifier::invalid;
switch (i) {
#define VALUE(x) case (crc32(#x, c_salt) % c_numBuckets) : if(!strcmp(testString, #x)) identifier = EIdentifier::x; else identifier = EIdentifier::invalid; break;
ENUM_VALUE_LIST
#undef VALUE
default: identifier = EIdentifier::invalid;
}
// undefine the enum value list
#undef ENUM_VALUE_LIST
printf("string translated to enum value %i", identifier);
Here’s the debug assembly showing it working like it’s supposed to:
// Debug / Release:
// Runs crc32 at runtime only for "i". The cases are compile time constants as per usual.
// Does a jumptable type setup for the switch and does a string comparison against the correct string.
// If strings are equal, sets the enum value.
static const unsigned int c_numBuckets = 16;
static const unsigned int c_salt = 1337;
const char* testString = "Identifier_F";
00007FF6B188179E lea rax,[string "Identifier_F" (07FF6B188B1E0h)]
00007FF6B18817A5 mov qword ptr [testString],rax
unsigned int i = crc32(testString, c_salt) % c_numBuckets;
00007FF6B18817A9 mov edx,539h
00007FF6B18817AE mov rcx,qword ptr [testString]
00007FF6B18817B2 call crc32 (07FF6B18810C3h)
00007FF6B18817B7 xor edx,edx
00007FF6B18817B9 mov ecx,10h
00007FF6B18817BE div eax,ecx
00007FF6B18817C0 mov eax,edx
00007FF6B18817C2 mov dword ptr [i],eax
// This macro list is used for:
// * making the enum
// * making the cases in the switch statement
// D.R.Y. - Don't Repeat Yourself.
// Fewer moving parts = fewer errors, but admittedly is harder to understand vs redundant code.
#define ENUM_VALUE_LIST
VALUE(Identifier_A)
VALUE(Identifier_B)
VALUE(Identifier_C)
VALUE(Identifier_D)
VALUE(Identifier_E)
VALUE(Identifier_F)
VALUE(Identifier_G)
VALUE(Identifier_H)
// Make the enum values.
// Note these enum values are also usable as a contiguous ID if you needed one for an array index or similar.
// You could define an array with size EIdentifier::count for instance and use these IDs to index into it.
enum class EIdentifier : unsigned char {
#define VALUE(x) x,
ENUM_VALUE_LIST
#undef VALUE
count,
invalid = (unsigned char)-1
};
// do a compile time hash assisted string comparison to convert string to enum
EIdentifier identifier = EIdentifier::invalid;
00007FF6B18817C5 mov byte ptr [identifier],0FFh
switch (i) {
00007FF6B18817C9 mov eax,dword ptr [i]
00007FF6B18817CC mov dword ptr [rbp+114h],eax
00007FF6B18817D2 cmp dword ptr [rbp+114h],0Eh
switch (i) {
00007FF6B18817D9 ja $LN25+20h (07FF6B1881904h)
00007FF6B18817DF mov eax,dword ptr [rbp+114h]
00007FF6B18817E5 lea rcx,[__ImageBase (07FF6B1870000h)]
00007FF6B18817EC mov eax,dword ptr [rcx+rax*4+11924h]
00007FF6B18817F3 add rax,rcx
00007FF6B18817F6 jmp rax
#define VALUE(x) case (crc32(#x, c_salt) % c_numBuckets) : if(!strcmp(testString, #x)) identifier = EIdentifier::x; else identifier = EIdentifier::invalid; break;
ENUM_VALUE_LIST
00007FF6B18817F8 lea rdx,[string "Identifier_A" (07FF6B188B190h)]
00007FF6B18817FF mov rcx,qword ptr [testString]
00007FF6B1881803 call strcmp (07FF6B18811CCh)
00007FF6B1881808 test eax,eax
00007FF6B188180A jne Snippet_CompileTimeHashAssistedStringToEnum+92h (07FF6B1881812h)
00007FF6B188180C mov byte ptr [identifier],0
00007FF6B1881810 jmp Snippet_CompileTimeHashAssistedStringToEnum+96h (07FF6B1881816h)
00007FF6B1881812 mov byte ptr [identifier],0FFh
00007FF6B1881816 jmp $LN25+24h (07FF6B1881908h)
$LN7:
00007FF6B188181B lea rdx,[string "Identifier_B" (07FF6B188B1A0h)]
00007FF6B1881822 mov rcx,qword ptr [testString]
00007FF6B1881826 call strcmp (07FF6B18811CCh)
00007FF6B188182B test eax,eax
00007FF6B188182D jne Snippet_CompileTimeHashAssistedStringToEnum+0B5h (07FF6B1881835h)
00007FF6B188182F mov byte ptr [identifier],1
00007FF6B1881833 jmp Snippet_CompileTimeHashAssistedStringToEnum+0B9h (07FF6B1881839h)
00007FF6B1881835 mov byte ptr [identifier],0FFh
00007FF6B1881839 jmp $LN25+24h (07FF6B1881908h)
$LN10:
00007FF6B188183E lea rdx,[string "Identifier_C" (07FF6B188B1B0h)]
00007FF6B1881845 mov rcx,qword ptr [testString]
00007FF6B1881849 call strcmp (07FF6B18811CCh)
00007FF6B188184E test eax,eax
00007FF6B1881850 jne Snippet_CompileTimeHashAssistedStringToEnum+0D8h (07FF6B1881858h)
00007FF6B1881852 mov byte ptr [identifier],2
00007FF6B1881856 jmp Snippet_CompileTimeHashAssistedStringToEnum+0DCh (07FF6B188185Ch)
00007FF6B1881858 mov byte ptr [identifier],0FFh
00007FF6B188185C jmp $LN25+24h (07FF6B1881908h)
$LN13:
00007FF6B1881861 lea rdx,[string "Identifier_D" (07FF6B188B1C0h)]
00007FF6B1881868 mov rcx,qword ptr [testString]
00007FF6B188186C call strcmp (07FF6B18811CCh)
00007FF6B1881871 test eax,eax
00007FF6B1881873 jne Snippet_CompileTimeHashAssistedStringToEnum+0FBh (07FF6B188187Bh)
00007FF6B1881875 mov byte ptr [identifier],3
00007FF6B1881879 jmp Snippet_CompileTimeHashAssistedStringToEnum+0FFh (07FF6B188187Fh)
00007FF6B188187B mov byte ptr [identifier],0FFh
00007FF6B188187F jmp $LN25+24h (07FF6B1881908h)
$LN16:
00007FF6B1881884 lea rdx,[string "Identifier_E" (07FF6B188B1D0h)]
00007FF6B188188B mov rcx,qword ptr [testString]
00007FF6B188188F call strcmp (07FF6B18811CCh)
00007FF6B1881894 test eax,eax
00007FF6B1881896 jne Snippet_CompileTimeHashAssistedStringToEnum+11Eh (07FF6B188189Eh)
00007FF6B1881898 mov byte ptr [identifier],4
00007FF6B188189C jmp Snippet_CompileTimeHashAssistedStringToEnum+122h (07FF6B18818A2h)
00007FF6B188189E mov byte ptr [identifier],0FFh
00007FF6B18818A2 jmp $LN25+24h (07FF6B1881908h)
$LN19:
00007FF6B18818A4 lea rdx,[string "Identifier_F" (07FF6B188B1E0h)]
00007FF6B18818AB mov rcx,qword ptr [testString]
00007FF6B18818AF call strcmp (07FF6B18811CCh)
00007FF6B18818B4 test eax,eax
00007FF6B18818B6 jne Snippet_CompileTimeHashAssistedStringToEnum+13Eh (07FF6B18818BEh)
00007FF6B18818B8 mov byte ptr [identifier],5
00007FF6B18818BC jmp Snippet_CompileTimeHashAssistedStringToEnum+142h (07FF6B18818C2h)
00007FF6B18818BE mov byte ptr [identifier],0FFh
00007FF6B18818C2 jmp $LN25+24h (07FF6B1881908h)
$LN22:
00007FF6B18818C4 lea rdx,[string "Identifier_G" (07FF6B188B1F0h)]
00007FF6B18818CB mov rcx,qword ptr [testString]
00007FF6B18818CF call strcmp (07FF6B18811CCh)
00007FF6B18818D4 test eax,eax
00007FF6B18818D6 jne Snippet_CompileTimeHashAssistedStringToEnum+15Eh (07FF6B18818DEh)
00007FF6B18818D8 mov byte ptr [identifier],6
00007FF6B18818DC jmp Snippet_CompileTimeHashAssistedStringToEnum+162h (07FF6B18818E2h)
00007FF6B18818DE mov byte ptr [identifier],0FFh
00007FF6B18818E2 jmp $LN25+24h (07FF6B1881908h)
$LN25:
00007FF6B18818E4 lea rdx,[string "Identifier_H" (07FF6B188B200h)]
00007FF6B18818EB mov rcx,qword ptr [testString]
00007FF6B18818EF call strcmp (07FF6B18811CCh)
00007FF6B18818F4 test eax,eax
00007FF6B18818F6 jne $LN25+1Ah (07FF6B18818FEh)
00007FF6B18818F8 mov byte ptr [identifier],7
00007FF6B18818FC jmp $LN25+1Eh (07FF6B1881902h)
00007FF6B18818FE mov byte ptr [identifier],0FFh
00007FF6B1881902 jmp $LN25+24h (07FF6B1881908h)
#undef VALUE
default: identifier = EIdentifier::invalid;
00007FF6B1881904 mov byte ptr [identifier],0FFh
}
// undefine the enum value list
#undef ENUM_VALUE_LIST
printf("string translated to enum value %i", identifier);
00007FF6B1881908 movzx eax,byte ptr [identifier]
00007FF6B188190C mov edx,eax
00007FF6B188190E lea rcx,[string "string translated to enum value "... (07FF6B188B248h)]
00007FF6B1881915 call printf (07FF6B18811FEh)
Other Possibilities
Besides the above, I think there is a lot of other really great uses for constexpr functions.
For instance, i’d like to see how it’d work to have compile time data structures to do faster read access of constant data.
I want to see compile time trees, hash tables, sparse arrays, bloom filters, and more.
I believe they have the potential to be a lot more performant than even static data structures, since empty or unaccessed sections of the data structure could possibly melt away when the optimizer does it’s pass.
It may not turn out like that, but I think it’d be interesting to investigate it deeper and see how it goes.
I’d also like to see compilers get more aggressive about doing whatever it can at compile time. If there’s no reason for it to happen at runtime, why make it happen then? It is only going to make things slower.
Thanks for reading!
Links
You can find the source code for the code snippets in this post here: Github Atrix256/RandomCode/CompileTimeCRC/
Here’s a couple interesting discussions on constexpr on stack overflow:
detecting execution time of a constexpr function
How to ensure constexpr function never called at runtime?




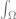 at the front and the
at the front and the 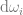 at the back) just means that we are going to take the result of everything between those two symbols, and add them up for every point in a hemisphere, multiplying each value by the fractional size of the point’s area for the hemisphere. The hemisphere we are talking about is the positive hemisphere surrounding the normal of the surface we are looking at.
at the back) just means that we are going to take the result of everything between those two symbols, and add them up for every point in a hemisphere, multiplying each value by the fractional size of the point’s area for the hemisphere. The hemisphere we are talking about is the positive hemisphere surrounding the normal of the surface we are looking at. – This is the “Bidirectional reflectance distribution function”, otherwise known as the BRDF. It describes how much light is reflected towards the view direction, of the light coming in from the point on the hemisphere we are considering.
– This is the “Bidirectional reflectance distribution function”, otherwise known as the BRDF. It describes how much light is reflected towards the view direction, of the light coming in from the point on the hemisphere we are considering. – This is how much light is coming in from the point on the hemisphere we are considering.
– This is how much light is coming in from the point on the hemisphere we are considering. – This is the cosine of the angle between the point on the hemisphere we are considering and the surface normal, gotten via a dot product. What this term means is that as the light direction gets more perpendicular to the normal, light is reflected less and less. This is based on the actual behavior of light and you can read more about it here if you want to:
– This is the cosine of the angle between the point on the hemisphere we are considering and the surface normal, gotten via a dot product. What this term means is that as the light direction gets more perpendicular to the normal, light is reflected less and less. This is based on the actual behavior of light and you can read more about it here if you want to: