
Lookup tables are a tool found in every programmer’s tool belt.
Lookup tables let you pre-calculate a complex calculation in advance, store the results in a table (an array), and then during performance critical parts of your program, you access that table to get quick answers to the calculations, without having to do the complex calculation on the fly.
In this post I’ll show a way to embed a lookup table inside of a single (large) number, where you extract values from that lookup table by taking a modulus of that number with different, specific values.
This technique is slower and takes more memory than an actual lookup table, but it’s conceptually interesting, so I wanted to share.
Also, I stumbled on this known technique while working on my current paper. The paper will make this technique a bit more practical, and I’ll share more info as soon as I am able, but for now you can regard this as a curiosity 😛
Onto the details!
1 Bit Input, 1 Bit Output: Pass Through
Let’s learn by example and start with a calculation that takes in an input bit, and gives that same value for an output bit. It’s just a 1 bit pass through lookup table.

To be able to convert that to something we can decode with modulus we have to solve the following equations:


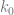
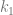
It looks as if we have two equations and three unknowns – which would be unsolvable – but in reality, x is the only unknown. The k values can be whatever values it takes to make the equations true.
I wrote a blog post on how to solve equations like these in a previous post: Solving Simultaneous Congruences (Chinese Remainder Theorem).
You can also use this chinese remainder theorem calculator, which is handy: Chinese Remainder Theorem Calculator
The short answer here is that the k values can be ANY numbers, so long as they are pairwise co-prime to each other – AKA they have a greatest common divisor of 1.
If we pick 3 and 4 for k0 and k1, then using the chinese remainder theorem we find that x can equal 9 and the equations are true. Technically the answer is 9 mod 12, so 21, 33, 45 and many other numbers are also valid values of x, but we are going to use the smallest answer to keep things smaller, and more manageable.
So, in this case, the value representing the lookup table would be 9. If you wanted to know what value it gave as output when you plugged in the value 0, you would modulus the lookup table (9) against k0 (3) to get the output. If you wanted to know what value it gave as output when you plugged in the value 1, you would modulus the lookup table (9) against k1 (4) to get the output. The table below shows that it passes through the value in both cases like it should:
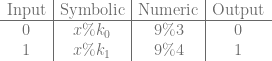
1 Bit Input, 1 Bit Output: Not Gate
Let’s do something a little more interesting. Let’s make the output bit be the reverse of the input bit. The equations we’ll want to solve are this:

We can use 3 and 4 for k0 and k1 again if we want to. Using the Chinese remainder theorem to solve the equations gives us a value of 4 for x. Check the truth table below to see how this works:

1 Bit Input, 1 Bit Output: Output Always 1
What if we wanted the output bit to always be 1 regardless of input bit?

Using 3 and 4 for our k values again, we solve and get a value of 1 for x. Check the truth table to see it working below:

Hopefully one bit input to one bit output makes sense now. Let’s move on (:
2 Bit Input, 1 Bit Output: XOR Gate
Things get a little more interesting when we bump the number of input bits up to 2. If we want to make a number which represents XOR, we now have 4 equations to solve.

In general we will have 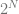
You might have noticed that I use subscripts for k corresponding to the input bits that the key represents. This is a convention I’ve found useful when working with this stuff. Makes it much easier to see what’s going on.
Now with four equations, we need 4 pairwise coprime numbers – no number has a common factor with another number besides 1.
Let’s pull them out of the air. Umm… 3, 4, 5, 7
Not too hard with only two bits of input, but you can see how adding input bits makes things a bit more complex. If you wanted to make something that took in two 16 bit numbers as input for example, you would need 2^32 co-prime numbers, since there was a total of 32 bits of input!
When we solve those four equations, we get a value of 21 for x.
Notice how x is larger now that we have more input bits? That is another added complexity as you add more input bits. The number representing your program can get very, very large, and require you to use “multi precision integer” math libraries to store and decode the programs, when the numbers get larger than what can be held in a 64 bit int.
Boost has a decent library for this, check out boost::multiprecision::cpp_int, it’s what I use. You can download boost from here: http://www.boost.org/doc/libs/1_59_0/more/getting_started/windows.html
Anyhow, let’s check the truth table to see if our values work:

Woot, it worked.
2 Bit Input, 2 Bit Output: OR, AND
What happens when we add another bit of output? Basically we just treat each output bit as it’s own lookup table. This means that if we have two output bits, we will have two numbers representing our program (one for each bit), and that this is true regardless of how many input bits we have.
Let’s make the left output bit (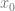

That give us these two sets of equations to solve:
We can use the same coprime numbers for our k values as we used in the last section (3,4,5,7). Note that we use the same k values in each set of equations. This is intentional and required for things to work out!
If we solve each set of equations we get 141 for x0, and 120 for x1.
Let’s see if that worked:

Hey, it worked again. Neat!
Example Code
Now that we have the basics worked out, here is some sample code.
The lookup table takes in 8 bits as input, mapping 0..255 to 0…2pi and gives the sine of that value as output in a float. So it has 8 bits of input and 32 bits of output.
#include <vector>
#include <boost/multiprecision/cpp_int.hpp>
#include <stdint.h>
#include <string.h>
#include <memory>
typedef boost::multiprecision::cpp_int TINT;
typedef std::vector<TINT> TINTVec;
const float c_pi = 3.14159265359f;
//=================================================================================
void WaitForEnter ()
{
printf("nPress Enter to quit");
fflush(stdin);
getchar();
}
//=================================================================================
static TINT ExtendedEuclidianAlgorithm (TINT smaller, TINT larger, TINT &s, TINT &t)
{
// make sure A <= B before starting
bool swapped = false;
if (larger < smaller)
{
swapped = true;
std::swap(smaller, larger);
}
// set up our storage for the loop. We only need the last two values so will
// just use a 2 entry circular buffer for each data item
std::array<TINT, 2> remainders = { larger, smaller };
std::array<TINT, 2> ss = { 1, 0 };
std::array<TINT, 2> ts = { 0, 1 };
size_t indexNeg2 = 0;
size_t indexNeg1 = 1;
// loop
while (1)
{
// calculate our new quotient and remainder
TINT newQuotient = remainders[indexNeg2] / remainders[indexNeg1];
TINT newRemainder = remainders[indexNeg2] - newQuotient * remainders[indexNeg1];
// if our remainder is zero we are done.
if (newRemainder == 0)
{
// return our s and t values as well as the quotient as the GCD
s = ss[indexNeg1];
t = ts[indexNeg1];
if (swapped)
std::swap(s, t);
// if t < 0, add the modulus divisor to it, to make it positive
if (t < 0)
t += smaller;
return remainders[indexNeg1];
}
// calculate this round's s and t
TINT newS = ss[indexNeg2] - newQuotient * ss[indexNeg1];
TINT newT = ts[indexNeg2] - newQuotient * ts[indexNeg1];
// store our values for the next iteration
remainders[indexNeg2] = newRemainder;
ss[indexNeg2] = newS;
ts[indexNeg2] = newT;
// move to the next iteration
std::swap(indexNeg1, indexNeg2);
}
}
//=================================================================================
void MakeKey (TINTVec &keys, TINT &keysLCM, size_t index)
{
// if this is the first key, use 3
if (index == 0)
{
keys[index] = 3;
keysLCM = keys[index];
return;
}
// Else start at the last number and keep checking odd numbers beyond that
// until you find one that is co-prime.
TINT nextNumber = keys[index - 1];
while (1)
{
nextNumber += 2;
if (std::all_of(
keys.begin(),
keys.begin() + index,
[&nextNumber] (const TINT& v) -> bool
{
TINT s, t;
return ExtendedEuclidianAlgorithm(v, nextNumber, s, t) == 1;
}))
{
keys[index] = nextNumber;
keysLCM *= nextNumber;
return;
}
}
}
//=================================================================================
void CalculateLookupTable (
TINT &lut,
const std::vector<uint64_t> &output,
const TINTVec &keys,
const TINT &keysLCM,
const TINTVec &coefficients,
size_t bitMask
)
{
// figure out how much to multiply each coefficient by to make it have the specified modulus residue (remainder)
lut = 0;
for (size_t i = 0, c = keys.size(); i < c; ++i)
{
// we either want this term to be 0 or 1 mod the key. if zero, we can multiply by zero, and
// not add anything into the bit value!
if ((output[i] & bitMask) == 0)
continue;
// if 1, use chinese remainder theorem
TINT s, t;
ExtendedEuclidianAlgorithm(coefficients[i], keys[i], s, t);
lut = (lut + ((coefficients[i] * t) % keysLCM)) % keysLCM;
}
}
//=================================================================================
template <typename TINPUT, typename TOUTPUT, typename LAMBDA>
void MakeModulus (TINTVec &luts, TINTVec &keys, LAMBDA &lambda)
{
// to keep things simple, input sizes are being constrained.
// Do this in x64 instead of win32 to make size_t 8 bytes instead of 4
static_assert(sizeof(TINPUT) < sizeof(size_t), "Input too large");
static_assert(sizeof(TOUTPUT) < sizeof(uint64_t), "Output too large");
// calculate some constants
const size_t c_numInputBits = sizeof(TINPUT) * 8;
const size_t c_numInputValues = 1 << c_numInputBits;
const size_t c_numOutputBits = sizeof(TOUTPUT) * 8;
// Generate the keys (coprimes)
TINT keysLCM;
keys.resize(c_numInputValues);
for (size_t index = 0; index < c_numInputValues; ++index)
MakeKey(keys, keysLCM, index);
// calculate co-efficients for use in the chinese remainder theorem
TINTVec coefficients;
coefficients.resize(c_numInputValues);
fill(coefficients.begin(), coefficients.end(), 1);
for (size_t i = 0; i < c_numInputValues; ++i)
{
for (size_t j = 0; j < c_numInputValues; ++j)
{
if (i != j)
coefficients[i] *= keys[j];
}
}
// gather all the input to output mappings by permuting the input space
// and storing the output for each input index
std::vector<uint64_t> output;
output.resize(c_numInputValues);
union
{
TINPUT value;
size_t index;
} input;
union
{
TOUTPUT value;
size_t index;
} outputConverter;
for (input.index = 0; input.index < c_numInputValues; ++input.index)
{
outputConverter.value = lambda(input.value);
output[input.index] = outputConverter.index;
}
// iterate through each possible output bit, since each bit is it's own lut
luts.resize(c_numOutputBits);
for (size_t i = 0; i < c_numOutputBits; ++i)
{
const size_t bitMask = 1 << i;
CalculateLookupTable(
luts[i],
output,
keys,
keysLCM,
coefficients,
bitMask
);
}
}
//=================================================================================
int main (int argc, char **argv)
{
// Look up tables encodes each bit, keys is used to decode each bit for specific
// input values.
TINTVec luts;
TINTVec keys;
// this is the function that it turns into modulus work
typedef uint8_t TINPUT;
typedef float TOUTPUT;
auto lambda = [] (TINPUT input) -> TOUTPUT
{
return sin(((TOUTPUT)input) / 255.0f * 2.0f * c_pi);
};
MakeModulus<TINPUT, TOUTPUT>(luts, keys, lambda);
// show last lut and key to show what kind of numbers they are
std::cout << "Last Lut: " << *luts.rbegin() << "n";
std::cout << "Last Key: " << *keys.rbegin() << "n";
// Decode all input values
std::cout << "n" << sizeof(TINPUT) << " bytes input, " << sizeof(TOUTPUT) << " bytes outputn";
for (size_t keyIndex = 0, keyCount = keys.size(); keyIndex < keyCount; ++keyIndex)
{
union
{
TOUTPUT value;
size_t index;
} result;
result.index = 0;
for (size_t lutIndex = 0, lutCount = luts.size(); lutIndex < lutCount; ++lutIndex)
{
TINT remainder = luts[lutIndex] % keys[keyIndex];
size_t remainderSizeT = size_t(remainder);
result.index += (remainderSizeT << lutIndex);
}
TINT remainder = luts[0] % keys[keyIndex];
std::cout << "i:" << keyIndex << " o:" << result.value << "n";
}
WaitForEnter();
return 0;
}
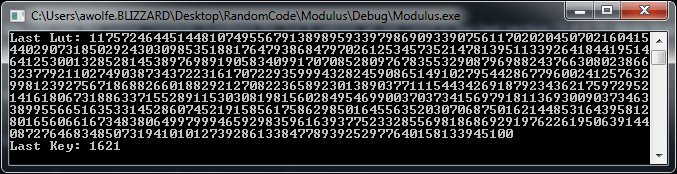
Here is some output from the program. The first is to show what the last (largest) look up table and key look like. Notice how large the look up table number is!
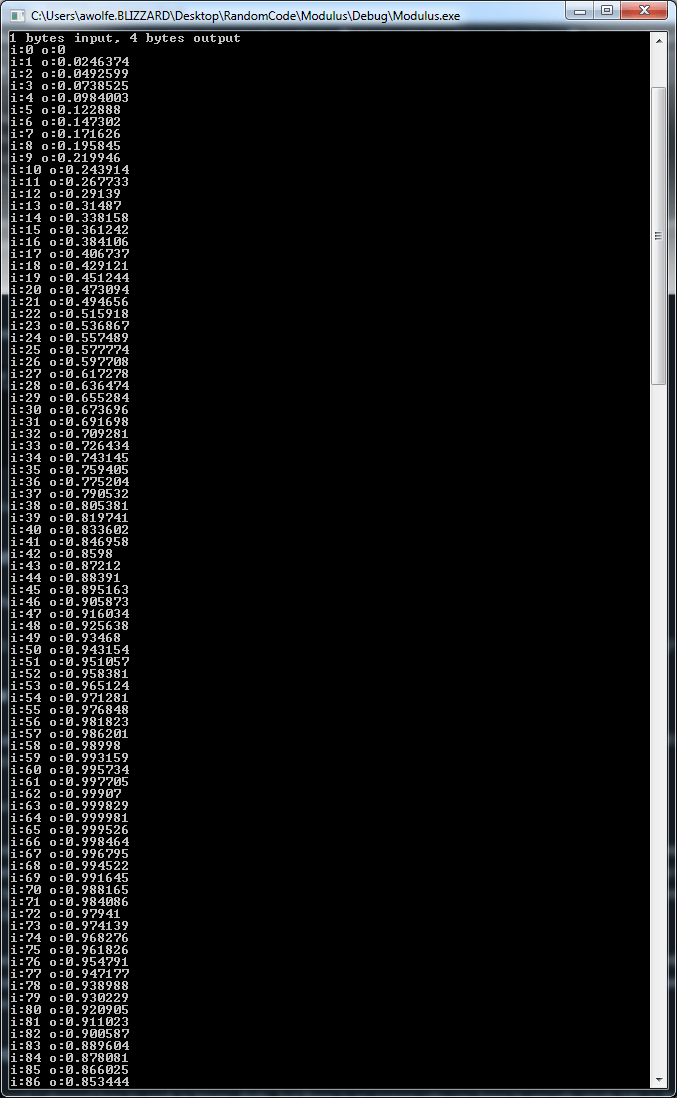
Here it shows some sine values output from the program, using modulus against the large numbers calculated, to get the bits of the result out:
How to Get Lots of Pairwise Co-Prime Numbers?
You can generate a list of pairwise coprimes using brute force. Have an integer that you increment, and check if it’s pairwise co-prime to the existing items in the list. If it is, add it to the list! Rinse and repeat until you have as many as you want.
That is the most practical way to do it, but there are two other interesting ways I wanted to mention.
The first way is using Fermat numbers. The Fermat numbers are an infinite list of pairwise co-prime numbers and are calculated as 
The second way is using something called Sylvester’s sequence. It too is an infinite list of pairwise co-prime numbers, and it too grows very large very quickly unfortunately. I also don’t believe there is a way to calculate the Nth item in the list directly. Every number is based on previous numbers, so you have to calculate them all from the beginning. No random access!
Beyond Binary
In this post I showed how to work in binary digits, but there is no reason why you have to encode single bits in the lookup tables.
Instead of encoding 0 or 1 in each modulus “lookup table”, you could also perhaps store base 10 numbers in the tables and have 0-9. Or, maybe you encode a byte per lookup table.
Encoding more than one bit effectively makes both your input and your output smaller, which helps the algorithm do more with less.
Your keys will need to be larger though, since the keys have to be larger than the value you plan to store, and your resulting lookup table will be a larger number as well. It might make the technique more worth while though.
I’ll leave that as an exercise for you. If try it and find neat stuff, post a comment and let us know, or drop me an email or something. It’d be neat to hear if people find any practical usage cases of this technique 😛
The End, For Now!
I want to point out that increasing the number of input bits in this technique is a pretty expensive thing to do, but increasing the number of output bits is a lot cheaper. It kind of makes sense in a way if you think about it. Input bits add information from the outside world that must be dealt with, while output bits are just fluff that can easily be diluted or concentrated by adding or removing bits that are associated with, and calculated from, the input bits.
Another problem you may have noticed with this technique is that if you have a really expensive calculation that you are trying to “flatten” into modulus math like this, that you have to run that calculation many, many times to know what values a lookup table would give you. You have to run it once per possible input to get every possible output. That is expected when making a lookup table, since you are paying a cost up front to make things faster later.
The paper I’m working on changes things a bit though. One of the things it does is it makes it so doing this technique only requires that you evaluate the function once, and it calculates all values simultaneously to give the end result that you can then do modulus against. It’s pretty cool IMO and I will share more details here as soon as I am able – and yes, i have actual working code that does that, believe it or not! I’m looking forward to being able to share it later on. Maybe someone will find some really cool usage case for it.
