
Hey all, I’m currently on vacation in Aruba, having a blast snorkeling, hanging out with the family, and working on some stuff on a kindle scribe I got for Xmas. The scribe is an excellent paper replacement, and I’m digging it. I used it a lot while working through things in this post, but I am also using it for a C++ game dev without graphics book I’m working on. I’ll have to figure out how to export pages to make better diagrams for blog posts in the future (;

By the way, I’ve ditched twitter and moved to mastodon. I’m here now if you want to follow me: https://mastodon.gamedev.place/@demofox.
I was recently playing battleship with my son and thinking about how choosing where to shoot is a lot like sampling a binary 2d function that either returns 1 for a hit or 0 for a miss. There is some more subtlety to it because there are boats of different lengths, so you can get more information to go on as time goes on, but it made me think about what the ideal firing pattern might be when searching for enemy boats.
I got some neat info from mastodon and found an interesting link.
https://mastodon.gamedev.place/@lesley/109628772065292620
https://www.wikihow.com/Win-at-Battleship
But then I had a different thought: could binary search generalize from 1D arrays to 2D or higher arrays? If so, they would need to be sorted. What does it even mean to sort a 2D array? Unsurprisingly, I’m not the first to think about this, and I’ll link to some resources. Still, the journey was interesting, and I have some code that implements higher dimensional binary searching:
https://github.com/Atrix256/BinarySearchND/blob/main/main.cpp
The code is written for readability/understandability, so it uses recursion when in reality, you wouldn’t do that, especially for the 1D binary search case.
Sorting
Tackling the sorting problem first, you could flatten a 2D array (or higher) into a 1D array like it was laid out in memory and sort that. You would then do a 1D binary search, but that doesn’t give you any higher dimensional benefits.
Taking an idea from heaps, you could partially sort it so that the values to the right and below were greater than or equal to the current value at every position, and that’s what I ended up going for.
I played around trying to devise a sorting algorithm for this for a while before finding out that you can sort all the X-axis rows, then all the Y-axis columns, and you’d end up with this. For 3D and above, you continue to sort each new axis.
So, that’s pretty cool. Sorting is seemingly solved but is this helpful at all? Does this help you search?
Trying a Tree / Graph Point of View
I first tried looking at this as a tree, where a value had two children; the value to the right and the value below. Doing this, I noticed that the tree was not a tree, but a graph, as almost all the values had two parents. A nice thing is that since the N-dimensional array could be stored in memory as a 1D array (since that is how memory works), this graph could exploit that and not need any pointers, with the links between parents and children being implicit (add 1 to x to get to 1 child, add 1 to y to get the other child).
Not sure if useful yet, but it sounds promising so far!
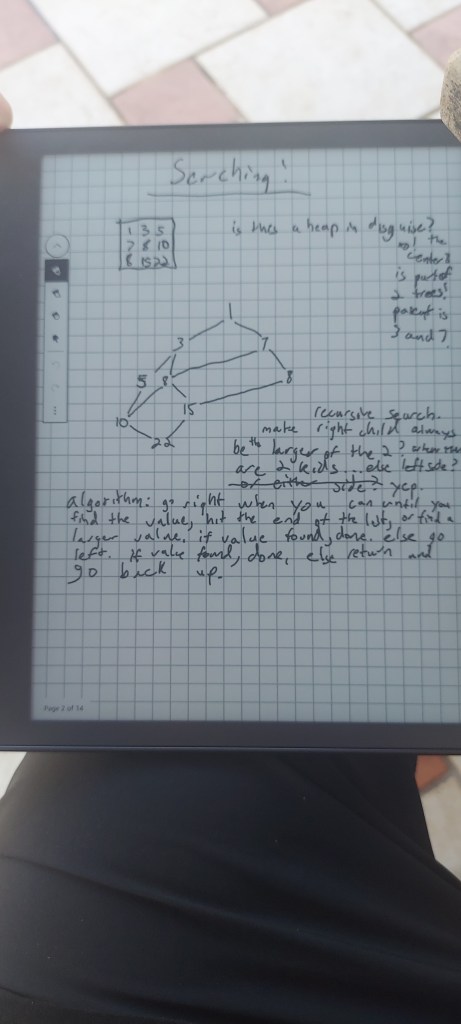
To search this structure, I tried a depth-first search and found that it took many reads during the search. It was nearly as bad as a linear search. A big part of this was that since children had multiple parents, you would search the same sub-graphs redundantly. I was planning on adding a “search version index” to each value, writing this index when testing a graph node, and only reading/recursing through graph nodes with smaller version numbers, where this version number incremented every time a search was done.
Before I implemented that, I had a more promising-sounding idea, however.
Back to a Flat Array Point of View
Could you binary search the first column to see where the value was larger than what you were searching for and cut off a large part of the array? If you could also cut off a starting point, you would have a min and max region to search for. Unfortunately, the number of rows would be variable, which isn’t great for getting consistently great perf results, but at least you could then binary search each row to look for your value. Maybe you could also do a binary search across columns and make an axis-aligned bounding box to search in.
Despite having some nice properties, that solution wasn’t quite good enough. It was too variable in how much would need to be searched the old-fashioned way, which means variable execution time and not a consistent benefit.
A nicer way of looking at things comes from realizing that at any element in one of these 2d arrays, anything with a higher or equal x and y coordinate value will be greater than or equal to that element in value. Also, anything with a lower or equal x and y coordinate value will be less than or equal to that element. This allows a binary search style divide and conquer algorithm to be crafted.
Comparing the center element of a 2D array with the search value, if they are equal, your search is done.
If the center element is less than the search value, you know that the search value can’t be in the quadrant where the x and y indices are equal or smaller since those all have the same or smaller values.
If the center element is greater than the search value, you know that the search value can’t be in the quadrant where the x and y indices are equal or greater since those all have the same or greater values.

When you remove a quadrant, you are left with two rectangles to recurse into.
You continue this process until you’ve found the search value and return true, or the area of a search region is zero, meaning it wasn’t found and return false.
3D Arrays and Higher
These ideas generalize to 3D, where you do the three-axis sorting of the 3D array to start.
Just like the 2D array case, you then test the center element against the search key and are either done, remove the low-valued octant that touches (0,0,0) or remove the high-valued octant that touches (width, height, depth).
In the 2D case, removing a quadrant left us with two rectangles to recurse into. In the 3d case, removing an octant leaves us with three cuboids to recurse into.
This generalizes to 4D and above just fine, following the patterns of the lower dimensions.
Performance Properties
In 1D, this algorithm is a binary search where you throw out either the left or right half of an array after comparing the center element vs. the search key. Each step removes 1/2 of the values from consideration.
In 2D, this algorithm throws out either the lower-valued quadrant or the higher-valued quadrant at each step. Each step removes 1/4 of the values from consideration.
3D throws out an octant or 1/8 of the values from consideration at each step.
We are hitting a curse of dimensionality and getting diminishing returns, throwing out 1 / (2^D) with each step for a D-dimensional binary search.
This also shows that the algorithm is most powerful in 1D as the binary search, where half of the values are removed from consideration at each step.
Is there any way to help this? Can we sort the arrays to throw out more values at each step? Not sure.
Other Thoughts
This journey started with me wondering if higher dimensional binary search was possible, but I don’t have a specific usage case. Is this even useful? I’m trying to think of a usage case but haven’t been able to so far. Can you think of one? If so, I’d love to hear it.
In 1D, an interpolation search can beat binary search under certain conditions (https://blog.demofox.org/2019/03/22/linear-fit-search/). Can that be generalized to 2D, 3D, or ND? A challenge here is that in 1D, a sorted list is a monotonic function, so there is only one place where the search value could be. In 2D, with one of these “sorted” arrays, you have a 2D surface that is sort of monotonic (stepping down or to the right won’t find a smaller value), but there are multiple places a search key could be found. So is there a way to take that algorithm to higher dimensions? I’m not sure, but I would love to hear your thoughts. https://math.stackexchange.com/questions/321812/generalizing-monotonicity-to-2d
In 1D, there is also a “golden section search” (https://en.wikipedia.org/wiki/Golden-section_search), which is good for finding minimum and maximum values in a function or unsorted array. Does this scale up to 2D or higher? It does seem so: https://www.researchgate.net/figure/Two-dimensional-golden-section-algorithm_fig13_3424118.
That’s all for now; thanks for reading!

I don’t quite understand how you are going to exploit dimensionality. If your problem is “find a number in a collection of numbers”, then it’s just a collection of numbers, no matter whether it’s a 1D array, 2D array, or a Mandelbrot-shaped array (only the indexing differs). If you restrict yourself to yes/no-type queries only (aka comparisons), you can’t do better than O(log N) in the worst case, which is achieved by binary search on a flattened and sorted array. If you allow for more general operations than plain comparisons, you can make an associative array “array element -> its index” and implement it as a hash table.
LikeLike
It is a solution looking for a problem for sure.
I forget the term, but you can do a “running integral” on 2d arrays to get something that lets you get sums of rectangular regions in constant time. If I’m remembering correctly, the numbers are in the order required to do this search. You’d still need a reason to do the search (maybe to find an isoline??) but that is starting to get more practical.
LikeLike