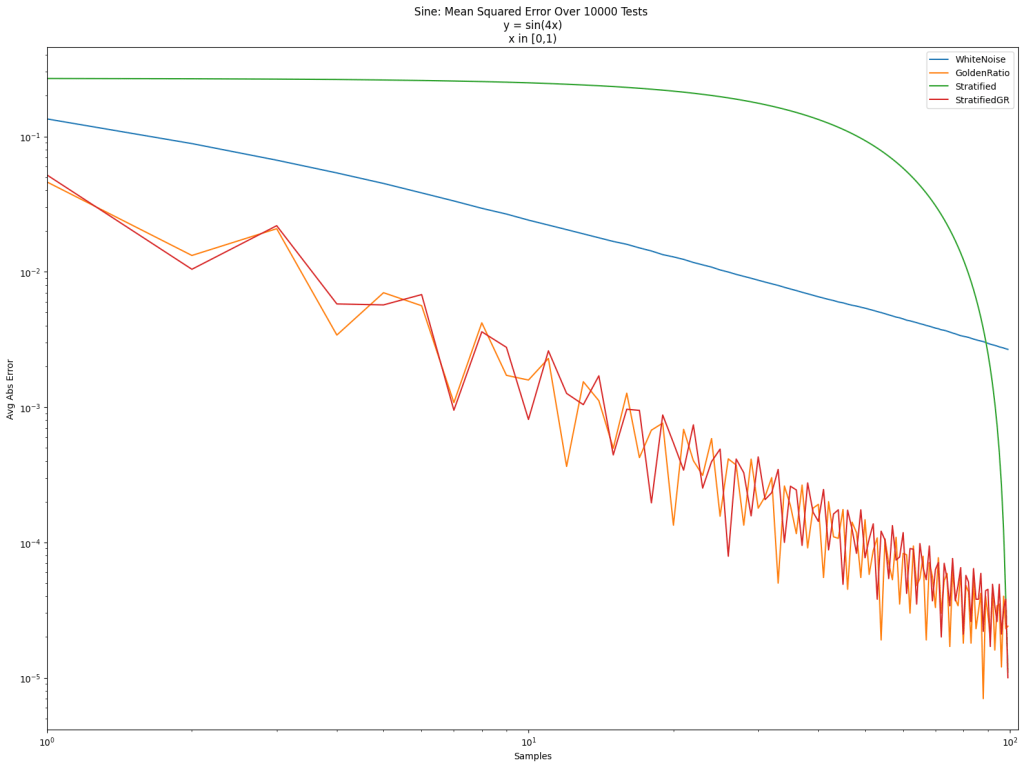
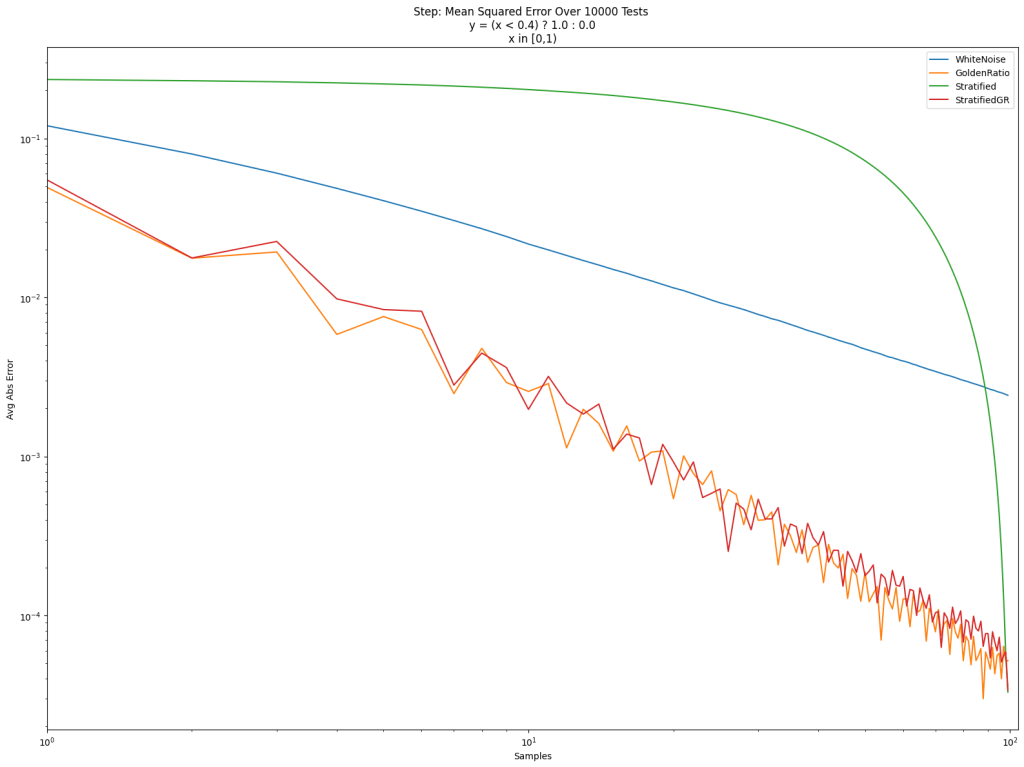
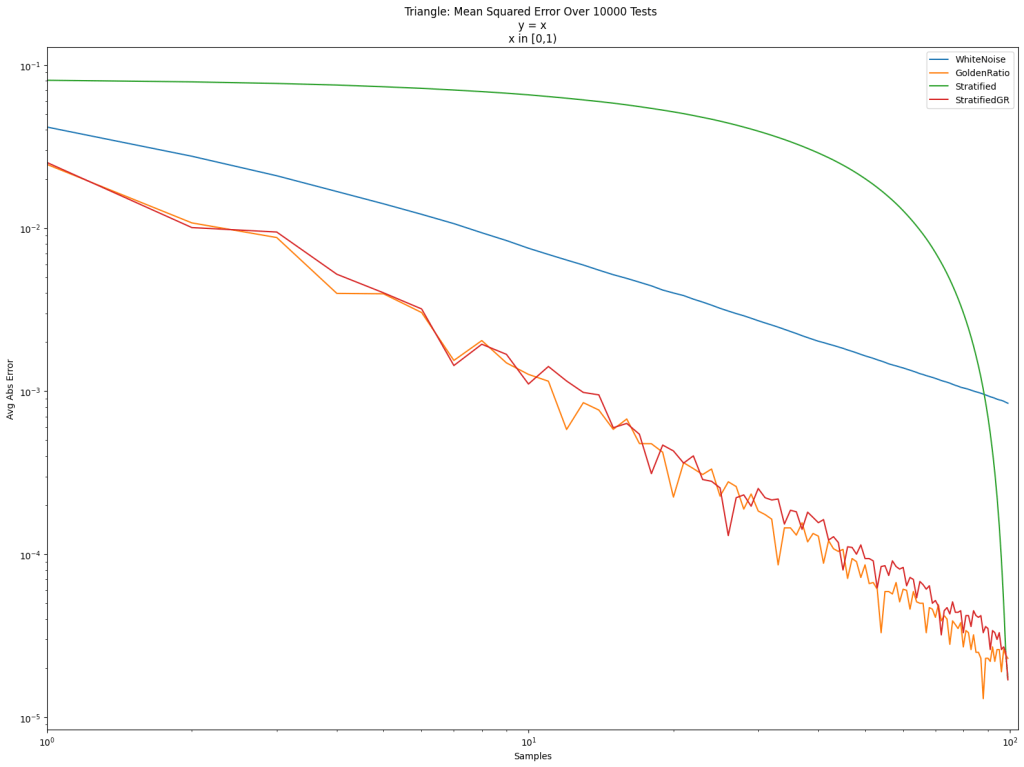
This article explains how these four things fit together and shows some examples of what they are used for.
Derivatives
Derivatives are the most fundamental concept in calculus. If you have a function, a derivative tells you how much that function changes at each point.
If we start with the function 



One use of derivatives is for optimization – also known as finding the lowest part on a graph.
If you were at 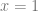

What I just described is an iterative optimization method that is similar to gradient descent. Gradient descent simulates a ball rolling down hill to find the lowest point that we can, adjusting step size, and even adding momentum to try and not get stuck in places that are not the true minimum.
We can make an observation though: The minimum of a function is flat, and has a derivative of 0. If not, that would mean it was on a hill, which means that going either left or right is lower, so it wouldn’t be the minimum.
Armed with this knowledge, another way to use derivatives to find the minimum is to find where the derivative is 0. We can do that by solving the equation 

Things get more complicated when the functions are higher order than quadratic. Higher order functions have both minimums and maximums, and both of those have 0 derivatives. Also, if the 
Higher dimensional functions also get more complex, where for instance you could have a point on a two dimensional function 

Gradients
Speaking of higher dimensional functions, that is where gradients come in.
If you have a function 

Looking at a single entry in the vector, 
Let’s work through calculating the gradient of the function 
To calculate the derivative of w with regard to x (
Calculating the derivative of w with regard to y, we treat y as a variable and all others as constants to get: 
Lastly, to calculate the derivative of w with regard to z, we treat z as a variable and all others as constants. That gives us 
The full gradient of the function is: 
An interesting thing about gradients is that when you calculate them for a specific point, they give a vector that points in the direction of the biggest increase in the function, or equivalently, in the steepest uphill direction. The opposite direction of the gradient is the biggest decrease of the function, or the steepest downhill direction. This is why gradients are used in the optimization method “Gradient Descent”. The gradient (multiplied by a step size) is subtracted from a point to move it down hill.
Besides optimization, gradients can also be used in rendering. For instance, here it’s used for rendering anti aliased signed distance fields: https://iquilezles.org/articles/distance/
Jacobian Matrix
Let’s say you had a function that took in multiple values and gave out multiple values: 
We could calculate the gradient of this function for v, and we could calculate it for w. If we put those two gradient vectors together to make a matrix, we would get the Jacobian matrix! You can also think of a gradient vector as being the Jacobian matrix of a function that outputs a single scalar value, instead of a vector.
Here is the Jacobian for

If that’s hard to read, the top row is the gradient for v, and the bottom row is the gradient for w.
When you evaluate the Jacobian matrix at a specific point in space (of whatever space the input parameters are in), it tells you how the space is warped in that location – like how much it is rotated and squished. You can also take the determinant of the Jacobian to see if things in that area get bigger (determinant greater than 1), smaller (determinant less than 1 but greater than 0), or if they get flipped inside out (determinant is negative). If the determinant is zero, it means it squishes everything into a single point (or line, etc. at least one dimension is scaled to 0), and also means that the operation can’t be reversed (the matrix can’t be inverted).
Here’s a great 10 minute video that goes into Jacobian Matrices a little more deeply and shows how they can be useful in machine learning: https://www.youtube.com/watch?v=AdV5w8CY3pw
Since Jacobians describe warping of space, they are also useful in computer graphics, where for instance, you might want to use alpha transparency to fade an object out over a specific number of pixels to perform anti aliasing, but the object may be described in polar coordinates, or be warped in way that makes it hard to know how many units to fade out over in that modified space. This has come up for me when doing 2D SDF rendering in shadertoy.
Hessian Matrix
If you take all partial derivatives (aka make a gradient) of a function
What if we wanted to get the 2nd derivatives? In other words, what if we wanted to take the derivative of the derivatives?
You could just take the derivative with respect to the same variables again, but to really understand the second derivatives of the function, we should take all three partial derivatives (one for x, one for y, one for z) of EACH of those three derivatives in the gradient.
That would give us 9 derivatives total, and that is exactly what the Hessian Matrix is.

If that is hard to read, each row is the gradient, but then the top row is differentiated with respect to x, the middle row is differentiated with respect to y, and the bottom row is differentiated with respect to z.
Another way to think about the Hessian is that it’s the transpose of the Jacobian matrix of the gradient. That’s a mouthful, but it hopefully helps you better see how these things fit together.
Taking the 2nd derivative of a function tells you how the function curves, which can be useful (again!) for optimization.
This 11 minute video talks about how the Hessian is used in optimization to get the answer faster, by knowing the curvature of the functions: https://www.youtube.com/watch?v=W7S94pq5Xuo
Where a derivative approximates a function locally with a line, a second order derivative approximates a function locally with a quadratic. So, a Hessian can let you model a function at a point as a quadratic type of function, and then do the neat trick from the derivative section of going straight to the minimum instead of having to iterate. That takes you to the minimum of the quadratic, not the minimum of the function you are trying to optimize, but that can be a great speed up for certain types of functions. You can also use the eigenvalues of the Hessian to know if it’s positive definite – aka if it’s a parabola pointing upwards and so actually has a minimum – vs if it’s pointing downwards, or is a saddle point. The eigenvectors can tell you the orientation of the paraboloid as well. Here is more information on analyzing a Hessian matrix: https://web.stanford.edu/group/sisl/k12/optimization/MO-unit4-pdfs/4.10applicationsofhessians.pdf
Calculating the Hessian can be quite costly both computationally and in regards to how much memory it uses, for machine learning problems that have millions of parameters or more. In those cases, there are quasi newton methods, which you can watch an 11 minute video about here: https://www.youtube.com/watch?v=UvGQRAA8Yms
Thanks for reading and hopefully this helps clear up some scary sounding words!