
You can use noise textures (like the ones from the last post) to do dithering.
For instance, you can do the process below to make a 1 bit (black and white) dithered image using a gray scale source image and a gray scale noise texture. This would be useful if you had a 1 bit display that you were trying to display an image on.
- For each pixel in the source image…
- If the source image pixel is brighter than the noise texture, put a white pixel.
- Else put a black pixel.
(info on converting images to grey scale here: Converting RGB to Grayscale)
The quality of the result depends on the type of noise you use.
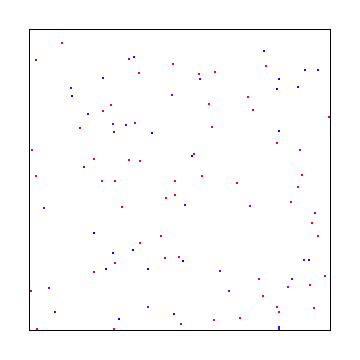
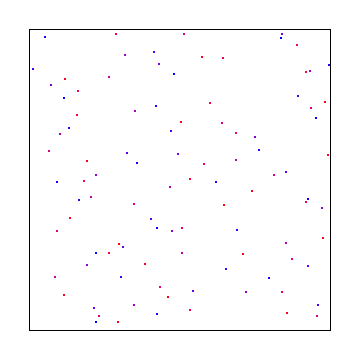
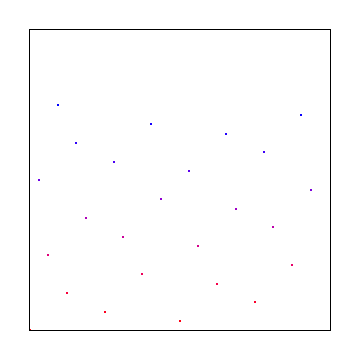
If you use pure random numbers (white noise) it looks like this:

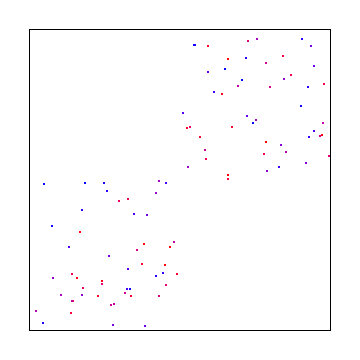
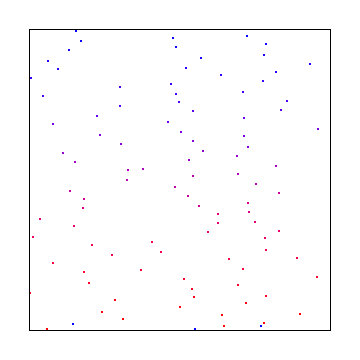
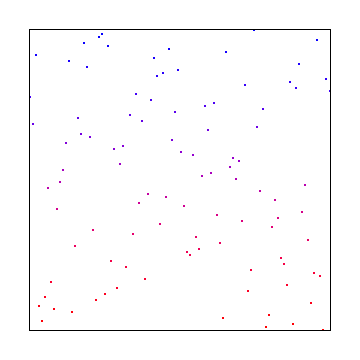
You could also use something called “Interleaved Gradient Noise” which would look like this:

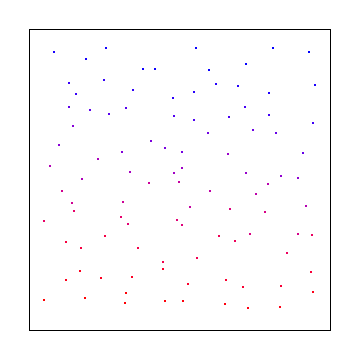
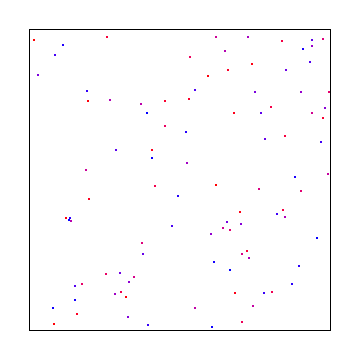
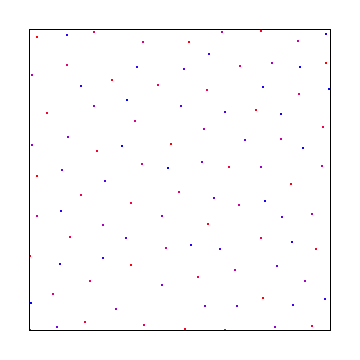
Or you could use blue noise which would look like this:

As you can see, white noise was the worst looking, interleaved gradient noise is is the middle, and blue noise looked the best.
White noise is very cheap to generate and can be done in real time on either the CPU or GPU – you just use random numbers.
Blue noise is more expensive to generate and usually must be done in advance, but gives high quality results.
Interleaved gradient noise, which gives middle results, is actually very similar in generation costs as white noise believe it or not, and so can also be done in real time on either the CPU or GPU.
If you have X and Y pixel coordinates (not uv coordinates), you can generate the noise value for the pixel by using this formula:
float noise = std::fmodf(52.9829189f * std::fmodf(0.06711056f*float(x) + 0.00583715f*float(y), 1.0f), 1.0f);
Interleaved gradient noise was made by Jorge Jimenez (@iryoku1) and you can read more about it at these links:
Next Generation Post Processing in Call Of Duty: Advanced Warfare
Dithering part three – real world 2D quantization dithering (Bart Wronksi)
Dithering still images is fun, but in the context of video games, we are more interested in animated images, so let’s look at things in motion.
Animated Noise
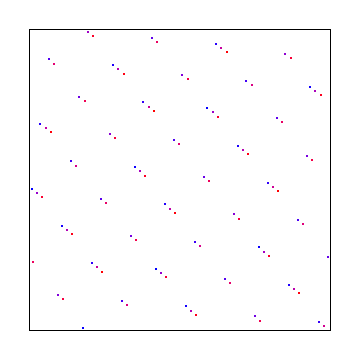
Let’s start by just animating those three noise types over 8 frames.
For white noise, we’ll generate a new white noise texture every frame.
For interleaved gradient noise, we’ll add a random offset (0 to 1000) to the pixel each frame, so we get 8 different interleaved gradient noise textures.
For blue noise, we’ll just have 8 different blue noise textures that we generate in advance.
These are playing at 8 fps, so loop every second.
White Noise:

IG Noise:

Blue Noise:

Once again we can see that white noise is worst, blue noise is best, and interleaved gradient noise is in the middle.
When you think about it though, despite these animations all using different types of noise over SPACE, they all use white noise over time. What i mean by that is if you isolate any individual pixel in any of the images and look at it over the 8 frames, that single pixel will look like white noise.
Let’s see if we can improve that.
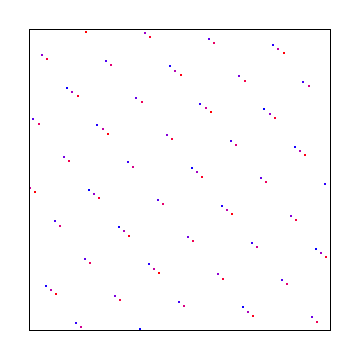
Golden Ratio Animated Noise
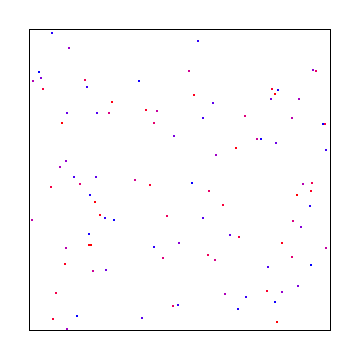
In a conversation on twitter, @R4_Unit told me that in the past he had good success by adding the golden ratio to blue noise textures to make the noise more blue over time.
The background here is that repeatedly adding the golden ratio to any number will make a low discrepancy sequence (details: When Random Numbers Are Too Random: Low Discrepancy Sequences)
The golden ratio is 
For each of the noise types, we’ll generate a single texture for frame 0, and each subsequent frame we will add the golden ratio to each pixel. The pixel values are in the 0 to 1 space when adding the golden ratio (not 0 to 255) and we use modulus to wrap it around.
The DFT magnitude is shown on the left to show how adding the golden ratio affects frequency components.
White Noise:

IG Noise:

Blue Noise:

When I look at these side by side with the previous animations, it’s hard for me to see much of a difference. That is interesting for the case of blue noise, where it’s difficult to generate multiple blue noise textures. It means that you can get a fairly decent “blue noise” texture by adding multiples of the golden ratio to an existing blue noise texture (aka recycling!).
It’s interesting that the white noise and interleaved gradient noise don’t change their frequency spectrum much over time. On the other hand, it’s a bit sad to see that the blue noise texture gains some low frequency content so the blue noise becomes lower quality. You aren’t just getting more blue noise textures for free by adding the golden ratio, even though they are blue-ish.
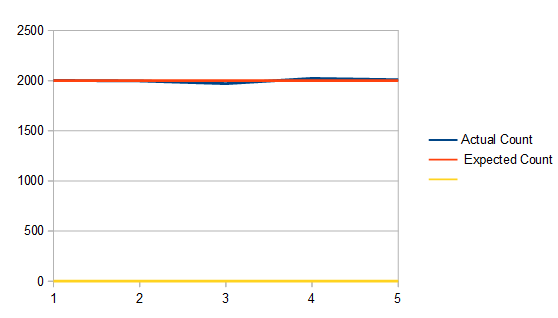
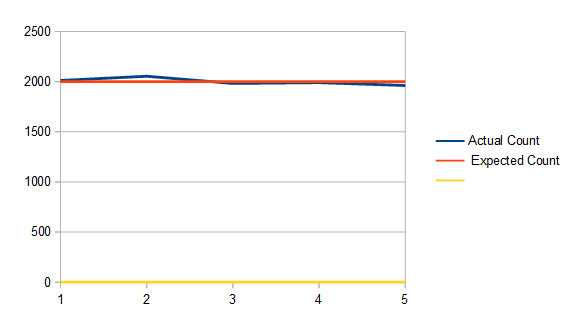
Another important aspect to look at is the histogram of colors used of these images when adding golden ratio. The ideal situation is that the starting images have roughly the same number of every color in the image, and that when adding the golden ratio for each frame, that we still use roughly the same number of every color. That turns out to be the case luckily.
The white noise histogram has a minimum count of 213, a maximum count of 303, an average count of 256 (the image is 256×256), and a standard deviation of 15.64. Those values are the same for each frame of the animation.
For interleaved gradient noise, it has a minimum count of 245, a maximum count of 266, an average count of 256 and a standard deviation of 2.87. Those values are the same for the entire animation.
Lastly, for blue noise, it has a minimum, maximum, and average count of 256, and a standard deviation of 0. This also remains true for the entire animation.
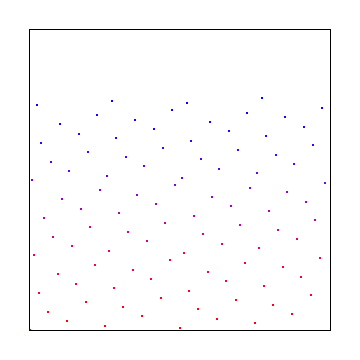
Integration Over Time
A big reason we might want animated noise in graphics is because we are taking multiple samples and want to numerically integrate them.
Lets analyze how these two types of animations (regular and golden ratio) compare for integration.
These animations are the same as before, but on frame 1, we show the average of frame 0 and 1. On frame 2 we show the average of frame 0, 1 and 2. And so on to frame 7 which is the average of all 8 frames. This is an integration of our black and white sample points we are taking, where the correct value of the integration is the greyscale image we started with.
Here is white noise, IG noise and blue noise animated (new noise each frame), integrated over those 8 frames, playing at 8 frames a second:



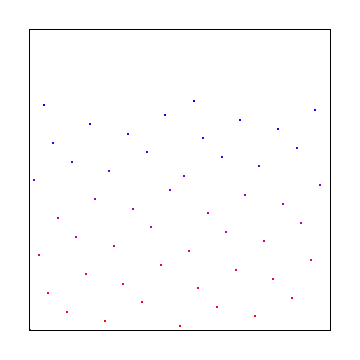
Here is the same using the golden ratio to animate the noise instead:



Since it can be a little difficult to compare these things while they are in motion, here is the final frames of each method and some graphs to show the average error and standard deviation of the error, compared to the ground truth source image.
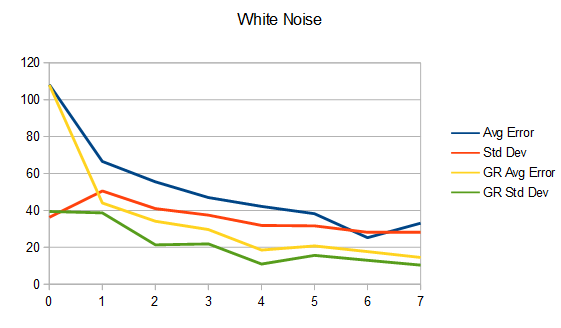
White Noise vs White Noise Golden Ratio:


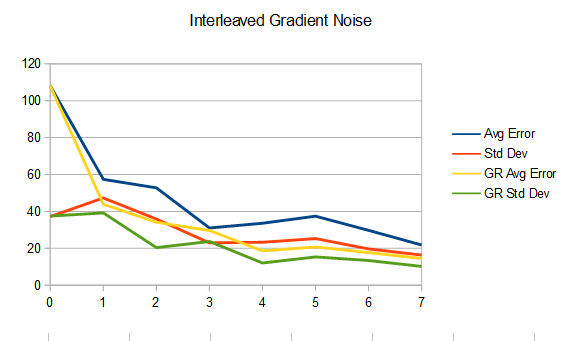
IG Noise vs IG Noise Golden Ratio:


Blue Noise vs Blue Noise Golden Ratio:



Interestingly, the golden ratio average error and standard deviation (from the ground truth) are pretty even for all types of noise by frame 7, even though the blue noise is perceptually superior. This also happens for the non golden ratio integrations of blue noise and white noise. That’s part of the value of blue noise, that even if it has the same amount of error as say, white noise, it still looks better.
Another interesting observation is that interleaved gradient noise performs better at integration (at least numerically) than white or blue noise, when not using the golden ratio. The only way I can explain this is that when picking random pixel offsets to generate each frame of interleaved gradient noise, it’s somehow more blue over time than the other two methods. It’s a strange but pretty useful property.
Despite IG having success when looking at the numbers, it has very visible directional patterns which are not so nice. The fact that it is as cheap as white noise to generate, but has results much closer to blue noise perceptually is pretty awesome though.
Something else important to note is that white noise beats blue noise in the long run (higher sample counts). It’s only at these lower sample counts that blue noise is the clear winner.
Lastly, it seems like the ideal setup for integrating some values over time with a lower sample count would be to have N blue noise textures to use over N frames, but *somehow* have a constraint on those textures generated such that each individual pixel over time has blue noise distributed values.
I’m not sure how to generate that, or if it’s even possible to do so, but doing that seems like it would be pretty near the ideal for doing integration like the above.
Taking a guess at how the DFT’s would look, each individual slice seems like it should look like a totally normal blue noise texture where it’s black in the middle (low frequencies) and noisy elsewhere (high frequencies). If you had N slices of these it would look like a black cylinder surrounded by noise when taking the 3D DFT. I’m not sure though how having the constraint on individual pixels would modify the DFT, or if it even would.
This “ideal” I’m describing is different than vanilla 3d blue noise. The 3d DFT of 3d blue noise is a black sphere surrounded by noise. What I’m describing is a cylinder instead of a sphere.
3d blue noise turns out not to be great for these needs. You can read about that here:
The problem with 3D blue noise
That author also has some an interesting post on blue noise, and a zip file full of blue noise textures that you can take and use.
I have some thoughts on generating this blue noise cylinder that if they work out may very well be the next blog post.
Code
Here is the code used to generate the images in this post. It’s also on github, which also contains the source images used.
Atrix256: RandomCode/AnimatedNoise
#define _CRT_SECURE_NO_WARNINGS
#include <windows.h> // for bitmap headers. Sorry non windows people!
#include <stdint.h>
#include <vector>
#include <random>
#include <atomic>
#include <thread>
#include <complex>
#include <array>
typedef uint8_t uint8;
const float c_pi = 3.14159265359f;
// settings
const bool c_doDFT = true;
// globals
FILE* g_logFile = nullptr;
//======================================================================================
inline float Lerp (float A, float B, float t)
{
return A * (1.0f - t) + B * t;
}
//======================================================================================
struct SImageData
{
SImageData ()
: m_width(0)
, m_height(0)
{ }
size_t m_width;
size_t m_height;
size_t m_pitch;
std::vector<uint8> m_pixels;
};
//======================================================================================
struct SColor
{
SColor (uint8 _R = 0, uint8 _G = 0, uint8 _B = 0)
: R(_R), G(_G), B(_B)
{ }
inline void Set (uint8 _R, uint8 _G, uint8 _B)
{
R = _R;
G = _G;
B = _B;
}
uint8 B, G, R;
};
//======================================================================================
struct SImageDataComplex
{
SImageDataComplex ()
: m_width(0)
, m_height(0)
{ }
size_t m_width;
size_t m_height;
std::vector<std::complex<float>> m_pixels;
};
//======================================================================================
std::complex<float> DFTPixel (const SImageData &srcImage, size_t K, size_t L)
{
std::complex<float> ret(0.0f, 0.0f);
for (size_t x = 0; x < srcImage.m_width; ++x)
{
for (size_t y = 0; y < srcImage.m_height; ++y)
{
// Get the pixel value (assuming greyscale) and convert it to [0,1] space
const uint8 *src = &srcImage.m_pixels[(y * srcImage.m_pitch) + x * 3];
float grey = float(src[0]) / 255.0f;
// Add to the sum of the return value
float v = float(K * x) / float(srcImage.m_width);
v += float(L * y) / float(srcImage.m_height);
ret += std::complex<float>(grey, 0.0f) * std::polar<float>(1.0f, -2.0f * c_pi * v);
}
}
return ret;
}
//======================================================================================
void ImageDFT (const SImageData &srcImage, SImageDataComplex &destImage)
{
// NOTE: this function assumes srcImage is greyscale, so works on only the red component of srcImage.
// ImageToGrey() will convert an image to greyscale.
// size the output dft data
destImage.m_width = srcImage.m_width;
destImage.m_height = srcImage.m_height;
destImage.m_pixels.resize(destImage.m_width*destImage.m_height);
size_t numThreads = std::thread::hardware_concurrency();
//if (numThreads > 0)
//numThreads = numThreads - 1;
std::vector<std::thread> threads;
threads.resize(numThreads);
printf("Doing DFT with %zu threads...\n", numThreads);
// calculate 2d dft (brute force, not using fast fourier transform) multithreadedly
std::atomic<size_t> nextRow(0);
for (std::thread& t : threads)
{
t = std::thread(
[&] ()
{
size_t row = nextRow.fetch_add(1);
bool reportProgress = (row == 0);
int lastPercent = -1;
while (row < srcImage.m_height)
{
// calculate the DFT for every pixel / frequency in this row
for (size_t x = 0; x < srcImage.m_width; ++x)
{
destImage.m_pixels[row * destImage.m_width + x] = DFTPixel(srcImage, x, row);
}
// report progress if we should
if (reportProgress)
{
int percent = int(100.0f * float(row) / float(srcImage.m_height));
if (lastPercent != percent)
{
lastPercent = percent;
printf(" \rDFT: %i%%", lastPercent);
}
}
// go to the next row
row = nextRow.fetch_add(1);
}
}
);
}
for (std::thread& t : threads)
t.join();
printf("\n");
}
//======================================================================================
void GetMagnitudeData (const SImageDataComplex& srcImage, SImageData& destImage)
{
// size the output image
destImage.m_width = srcImage.m_width;
destImage.m_height = srcImage.m_height;
destImage.m_pitch = 4 * ((srcImage.m_width * 24 + 31) / 32);
destImage.m_pixels.resize(destImage.m_pitch*destImage.m_height);
// get floating point magnitude data
std::vector<float> magArray;
magArray.resize(srcImage.m_width*srcImage.m_height);
float maxmag = 0.0f;
for (size_t x = 0; x < srcImage.m_width; ++x)
{
for (size_t y = 0; y < srcImage.m_height; ++y)
{
// Offset the information by half width & height in the positive direction.
// This makes frequency 0 (DC) be at the image origin, like most diagrams show it.
int k = (x + (int)srcImage.m_width / 2) % (int)srcImage.m_width;
int l = (y + (int)srcImage.m_height / 2) % (int)srcImage.m_height;
const std::complex<float> &src = srcImage.m_pixels[l*srcImage.m_width + k];
float mag = std::abs(src);
if (mag > maxmag)
maxmag = mag;
magArray[y*srcImage.m_width + x] = mag;
}
}
if (maxmag == 0.0f)
maxmag = 1.0f;
const float c = 255.0f / log(1.0f+maxmag);
// normalize the magnitude data and send it back in [0, 255]
for (size_t x = 0; x < srcImage.m_width; ++x)
{
for (size_t y = 0; y < srcImage.m_height; ++y)
{
float src = c * log(1.0f + magArray[y*srcImage.m_width + x]);
uint8 magu8 = uint8(src);
uint8* dest = &destImage.m_pixels[y*destImage.m_pitch + x * 3];
dest[0] = magu8;
dest[1] = magu8;
dest[2] = magu8;
}
}
}
//======================================================================================
bool ImageSave (const SImageData &image, const char *fileName)
{
// open the file if we can
FILE *file;
file = fopen(fileName, "wb");
if (!file) {
printf("Could not save %s\n", fileName);
return false;
}
// make the header info
BITMAPFILEHEADER header;
BITMAPINFOHEADER infoHeader;
header.bfType = 0x4D42;
header.bfReserved1 = 0;
header.bfReserved2 = 0;
header.bfOffBits = 54;
infoHeader.biSize = 40;
infoHeader.biWidth = (LONG)image.m_width;
infoHeader.biHeight = (LONG)image.m_height;
infoHeader.biPlanes = 1;
infoHeader.biBitCount = 24;
infoHeader.biCompression = 0;
infoHeader.biSizeImage = (DWORD) image.m_pixels.size();
infoHeader.biXPelsPerMeter = 0;
infoHeader.biYPelsPerMeter = 0;
infoHeader.biClrUsed = 0;
infoHeader.biClrImportant = 0;
header.bfSize = infoHeader.biSizeImage + header.bfOffBits;
// write the data and close the file
fwrite(&header, sizeof(header), 1, file);
fwrite(&infoHeader, sizeof(infoHeader), 1, file);
fwrite(&image.m_pixels[0], infoHeader.biSizeImage, 1, file);
fclose(file);
return true;
}
//======================================================================================
bool ImageLoad (const char *fileName, SImageData& imageData)
{
// open the file if we can
FILE *file;
file = fopen(fileName, "rb");
if (!file)
return false;
// read the headers if we can
BITMAPFILEHEADER header;
BITMAPINFOHEADER infoHeader;
if (fread(&header, sizeof(header), 1, file) != 1 ||
fread(&infoHeader, sizeof(infoHeader), 1, file) != 1 ||
header.bfType != 0x4D42 || infoHeader.biBitCount != 24)
{
fclose(file);
return false;
}
// read in our pixel data if we can. Note that it's in BGR order, and width is padded to the next power of 4
imageData.m_pixels.resize(infoHeader.biSizeImage);
fseek(file, header.bfOffBits, SEEK_SET);
if (fread(&imageData.m_pixels[0], imageData.m_pixels.size(), 1, file) != 1)
{
fclose(file);
return false;
}
imageData.m_width = infoHeader.biWidth;
imageData.m_height = infoHeader.biHeight;
imageData.m_pitch = 4 * ((imageData.m_width * 24 + 31) / 32);
fclose(file);
return true;
}
//======================================================================================
void ImageInit (SImageData& image, size_t width, size_t height)
{
image.m_width = width;
image.m_height = height;
image.m_pitch = 4 * ((width * 24 + 31) / 32);
image.m_pixels.resize(image.m_pitch * image.m_height);
std::fill(image.m_pixels.begin(), image.m_pixels.end(), 0);
}
//======================================================================================
template <typename LAMBDA>
void ImageForEachPixel (SImageData& image, const LAMBDA& lambda)
{
size_t pixelIndex = 0;
for (size_t y = 0; y < image.m_height; ++y)
{
SColor* pixel = (SColor*)&image.m_pixels[y * image.m_pitch];
for (size_t x = 0; x < image.m_width; ++x)
{
lambda(*pixel, pixelIndex);
++pixel;
++pixelIndex;
}
}
}
//======================================================================================
template <typename LAMBDA>
void ImageForEachPixel (const SImageData& image, const LAMBDA& lambda)
{
size_t pixelIndex = 0;
for (size_t y = 0; y < image.m_height; ++y)
{
SColor* pixel = (SColor*)&image.m_pixels[y * image.m_pitch];
for (size_t x = 0; x < image.m_width; ++x)
{
lambda(*pixel, pixelIndex);
++pixel;
++pixelIndex;
}
}
}
//======================================================================================
void ImageConvertToLuma (SImageData& image)
{
ImageForEachPixel(
image,
[] (SColor& pixel, size_t pixelIndex)
{
float luma = float(pixel.R) * 0.3f + float(pixel.G) * 0.59f + float(pixel.B) * 0.11f;
uint8 lumau8 = uint8(luma + 0.5f);
pixel.R = lumau8;
pixel.G = lumau8;
pixel.B = lumau8;
}
);
}
//======================================================================================
void ImageCombine2 (const SImageData& imageA, const SImageData& imageB, SImageData& result)
{
// put the images side by side. A on left, B on right
ImageInit(result, imageA.m_width + imageB.m_width, max(imageA.m_height, imageB.m_height));
std::fill(result.m_pixels.begin(), result.m_pixels.end(), 0);
// image A on left
for (size_t y = 0; y < imageA.m_height; ++y)
{
SColor* destPixel = (SColor*)&result.m_pixels[y * result.m_pitch];
SColor* srcPixel = (SColor*)&imageA.m_pixels[y * imageA.m_pitch];
for (size_t x = 0; x < imageA.m_width; ++x)
{
destPixel[0] = srcPixel[0];
++destPixel;
++srcPixel;
}
}
// image B on right
for (size_t y = 0; y < imageB.m_height; ++y)
{
SColor* destPixel = (SColor*)&result.m_pixels[y * result.m_pitch + imageA.m_width * 3];
SColor* srcPixel = (SColor*)&imageB.m_pixels[y * imageB.m_pitch];
for (size_t x = 0; x < imageB.m_width; ++x)
{
destPixel[0] = srcPixel[0];
++destPixel;
++srcPixel;
}
}
}
//======================================================================================
void ImageCombine3 (const SImageData& imageA, const SImageData& imageB, const SImageData& imageC, SImageData& result)
{
// put the images side by side. A on left, B in middle, C on right
ImageInit(result, imageA.m_width + imageB.m_width + imageC.m_width, max(max(imageA.m_height, imageB.m_height), imageC.m_height));
std::fill(result.m_pixels.begin(), result.m_pixels.end(), 0);
// image A on left
for (size_t y = 0; y < imageA.m_height; ++y)
{
SColor* destPixel = (SColor*)&result.m_pixels[y * result.m_pitch];
SColor* srcPixel = (SColor*)&imageA.m_pixels[y * imageA.m_pitch];
for (size_t x = 0; x < imageA.m_width; ++x)
{
destPixel[0] = srcPixel[0];
++destPixel;
++srcPixel;
}
}
// image B in middle
for (size_t y = 0; y < imageB.m_height; ++y)
{
SColor* destPixel = (SColor*)&result.m_pixels[y * result.m_pitch + imageA.m_width * 3];
SColor* srcPixel = (SColor*)&imageB.m_pixels[y * imageB.m_pitch];
for (size_t x = 0; x < imageB.m_width; ++x)
{
destPixel[0] = srcPixel[0];
++destPixel;
++srcPixel;
}
}
// image C on right
for (size_t y = 0; y < imageC.m_height; ++y)
{
SColor* destPixel = (SColor*)&result.m_pixels[y * result.m_pitch + imageA.m_width * 3 + imageC.m_width * 3];
SColor* srcPixel = (SColor*)&imageC.m_pixels[y * imageC.m_pitch];
for (size_t x = 0; x < imageC.m_width; ++x)
{
destPixel[0] = srcPixel[0];
++destPixel;
++srcPixel;
}
}
}
//======================================================================================
float GoldenRatioMultiple (size_t multiple)
{
return float(multiple) * (1.0f + std::sqrtf(5.0f)) / 2.0f;
}
//======================================================================================
void IntegrationTest (const SImageData& dither, const SImageData& groundTruth, size_t frameIndex, const char* label)
{
// calculate min, max, total and average error
size_t minError = 0;
size_t maxError = 0;
size_t totalError = 0;
size_t pixelCount = 0;
for (size_t y = 0; y < dither.m_height; ++y)
{
SColor* ditherPixel = (SColor*)&dither.m_pixels[y * dither.m_pitch];
SColor* truthPixel = (SColor*)&groundTruth.m_pixels[y * groundTruth.m_pitch];
for (size_t x = 0; x < dither.m_width; ++x)
{
size_t error = 0;
if (ditherPixel->R > truthPixel->R)
error = ditherPixel->R - truthPixel->R;
else
error = truthPixel->R - ditherPixel->R;
totalError += error;
if ((x == 0 && y == 0) || error < minError)
minError = error;
if ((x == 0 && y == 0) || error > maxError)
maxError = error;
++ditherPixel;
++truthPixel;
++pixelCount;
}
}
float averageError = float(totalError) / float(pixelCount);
// calculate standard deviation
float sumSquaredDiff = 0.0f;
for (size_t y = 0; y < dither.m_height; ++y)
{
SColor* ditherPixel = (SColor*)&dither.m_pixels[y * dither.m_pitch];
SColor* truthPixel = (SColor*)&groundTruth.m_pixels[y * groundTruth.m_pitch];
for (size_t x = 0; x < dither.m_width; ++x)
{
size_t error = 0;
if (ditherPixel->R > truthPixel->R)
error = ditherPixel->R - truthPixel->R;
else
error = truthPixel->R - ditherPixel->R;
float diff = float(error) - averageError;
sumSquaredDiff += diff*diff;
}
}
float stdDev = std::sqrtf(sumSquaredDiff / float(pixelCount - 1));
// report results
fprintf(g_logFile, "%s %zu error\n", label, frameIndex);
fprintf(g_logFile, " min error: %zu\n", minError);
fprintf(g_logFile, " max error: %zu\n", maxError);
fprintf(g_logFile, " avg error: %0.2f\n", averageError);
fprintf(g_logFile, " stddev: %0.2f\n", stdDev);
fprintf(g_logFile, "\n");
}
//======================================================================================
void HistogramTest (const SImageData& noise, size_t frameIndex, const char* label)
{
std::array<size_t, 256> counts;
std::fill(counts.begin(), counts.end(), 0);
ImageForEachPixel(
noise,
[&] (const SColor& pixel, size_t pixelIndex)
{
counts[pixel.R]++;
}
);
// calculate min, max, total and average
size_t minCount = 0;
size_t maxCount = 0;
size_t totalCount = 0;
for (size_t i = 0; i < 256; ++i)
{
if (i == 0 || counts[i] < minCount)
minCount = counts[i];
if (i == 0 || counts[i] > maxCount)
maxCount = counts[i];
totalCount += counts[i];
}
float averageCount = float(totalCount) / float(256.0f);
// calculate standard deviation
float sumSquaredDiff = 0.0f;
for (size_t i = 0; i < 256; ++i)
{
float diff = float(counts[i]) - averageCount;
sumSquaredDiff += diff*diff;
}
float stdDev = std::sqrtf(sumSquaredDiff / 255.0f);
// report results
fprintf(g_logFile, "%s %zu histogram\n", label, frameIndex);
fprintf(g_logFile, " min count: %zu\n", minCount);
fprintf(g_logFile, " max count: %zu\n", maxCount);
fprintf(g_logFile, " avg count: %0.2f\n", averageCount);
fprintf(g_logFile, " stddev: %0.2f\n", stdDev);
fprintf(g_logFile, " counts: ");
for (size_t i = 0; i < 256; ++i)
{
if (i > 0)
fprintf(g_logFile, ", ");
fprintf(g_logFile, "%zu", counts[i]);
}
fprintf(g_logFile, "\n\n");
}
//======================================================================================
void GenerateWhiteNoise (SImageData& image, size_t width, size_t height)
{
ImageInit(image, width, height);
std::random_device rd;
std::mt19937 rng(rd());
std::uniform_int_distribution<unsigned int> dist(0, 255);
ImageForEachPixel(
image,
[&] (SColor& pixel, size_t pixelIndex)
{
uint8 value = dist(rng);
pixel.R = value;
pixel.G = value;
pixel.B = value;
}
);
}
//======================================================================================
void GenerateInterleavedGradientNoise (SImageData& image, size_t width, size_t height, float offsetX, float offsetY)
{
ImageInit(image, width, height);
std::random_device rd;
std::mt19937 rng(rd());
std::uniform_int_distribution<unsigned int> dist(0, 255);
for (size_t y = 0; y < height; ++y)
{
SColor* pixel = (SColor*)&image.m_pixels[y * image.m_pitch];
for (size_t x = 0; x < width; ++x)
{
float valueFloat = std::fmodf(52.9829189f * std::fmod(0.06711056f*float(x + offsetX) + 0.00583715f*float(y + offsetY), 1.0f), 1.0f);
size_t valueBig = size_t(valueFloat * 256.0f);
uint8 value = uint8(valueBig % 256);
pixel->R = value;
pixel->G = value;
pixel->B = value;
++pixel;
}
}
}
//======================================================================================
void DitherWithTexture (const SImageData& ditherImage, const SImageData& noiseImage, SImageData& result)
{
// init the result image
ImageInit(result, ditherImage.m_width, ditherImage.m_height);
// make the result image
for (size_t y = 0; y < ditherImage.m_height; ++y)
{
SColor* srcDitherPixel = (SColor*)&ditherImage.m_pixels[y * ditherImage.m_pitch];
SColor* destDitherPixel = (SColor*)&result.m_pixels[y * result.m_pitch];
for (size_t x = 0; x < ditherImage.m_width; ++x)
{
// tile the noise in case it isn't the same size as the image we are dithering
size_t noiseX = x % noiseImage.m_width;
size_t noiseY = y % noiseImage.m_height;
SColor* noisePixel = (SColor*)&noiseImage.m_pixels[noiseY * noiseImage.m_pitch + noiseX * 3];
uint8 value = 0;
if (noisePixel->R < srcDitherPixel->R)
value = 255;
destDitherPixel->R = value;
destDitherPixel->G = value;
destDitherPixel->B = value;
++srcDitherPixel;
++destDitherPixel;
}
}
}
//======================================================================================
void DitherWhiteNoise (const SImageData& ditherImage)
{
printf("\n%s\n", __FUNCTION__);
// make noise
SImageData noise;
GenerateWhiteNoise(noise, ditherImage.m_width, ditherImage.m_height);
// dither the image
SImageData dither;
DitherWithTexture(ditherImage, noise, dither);
// save the results
SImageData combined;
ImageCombine3(ditherImage, noise, dither, combined);
ImageSave(combined, "out/still_whitenoise.bmp");
}
//======================================================================================
void DitherInterleavedGradientNoise (const SImageData& ditherImage)
{
printf("\n%s\n", __FUNCTION__);
// make noise
SImageData noise;
GenerateInterleavedGradientNoise(noise, ditherImage.m_width, ditherImage.m_height, 0.0f, 0.0f);
// dither the image
SImageData dither;
DitherWithTexture(ditherImage, noise, dither);
// save the results
SImageData combined;
ImageCombine3(ditherImage, noise, dither, combined);
ImageSave(combined, "out/still_ignoise.bmp");
}
//======================================================================================
void DitherBlueNoise (const SImageData& ditherImage, const SImageData& blueNoise)
{
printf("\n%s\n", __FUNCTION__);
// dither the image
SImageData dither;
DitherWithTexture(ditherImage, blueNoise, dither);
// save the results
SImageData combined;
ImageCombine3(ditherImage, blueNoise, dither, combined);
ImageSave(combined, "out/still_bluenoise.bmp");
}
//======================================================================================
void DitherWhiteNoiseAnimated (const SImageData& ditherImage)
{
printf("\n%s\n", __FUNCTION__);
// animate 8 frames
for (size_t i = 0; i < 8; ++i)
{
char fileName[256];
sprintf(fileName, "out/anim_whitenoise%zu.bmp", i);
// make noise
SImageData noise;
GenerateWhiteNoise(noise, ditherImage.m_width, ditherImage.m_height);
// dither the image
SImageData dither;
DitherWithTexture(ditherImage, noise, dither);
// save the results
SImageData combined;
ImageCombine2(noise, dither, combined);
ImageSave(combined, fileName);
}
}
//======================================================================================
void DitherInterleavedGradientNoiseAnimated (const SImageData& ditherImage)
{
printf("\n%s\n", __FUNCTION__);
std::random_device rd;
std::mt19937 rng(rd());
std::uniform_real_distribution<float> dist(0.0f, 1000.0f);
// animate 8 frames
for (size_t i = 0; i < 8; ++i)
{
char fileName[256];
sprintf(fileName, "out/anim_ignoise%zu.bmp", i);
// make noise
SImageData noise;
GenerateInterleavedGradientNoise(noise, ditherImage.m_width, ditherImage.m_height, dist(rng), dist(rng));
// dither the image
SImageData dither;
DitherWithTexture(ditherImage, noise, dither);
// save the results
SImageData combined;
ImageCombine2(noise, dither, combined);
ImageSave(combined, fileName);
}
}
//======================================================================================
void DitherBlueNoiseAnimated (const SImageData& ditherImage, const SImageData blueNoise[8])
{
printf("\n%s\n", __FUNCTION__);
// animate 8 frames
for (size_t i = 0; i < 8; ++i)
{
char fileName[256];
sprintf(fileName, "out/anim_bluenoise%zu.bmp", i);
// dither the image
SImageData dither;
DitherWithTexture(ditherImage, blueNoise[i], dither);
// save the results
SImageData combined;
ImageCombine2(blueNoise[i], dither, combined);
ImageSave(combined, fileName);
}
}
//======================================================================================
void DitherWhiteNoiseAnimatedIntegrated (const SImageData& ditherImage)
{
printf("\n%s\n", __FUNCTION__);
std::vector<float> integration;
integration.resize(ditherImage.m_width * ditherImage.m_height);
std::fill(integration.begin(), integration.end(), 0.0f);
// animate 8 frames
for (size_t i = 0; i < 8; ++i)
{
char fileName[256];
sprintf(fileName, "out/animint_whitenoise%zu.bmp", i);
// make noise
SImageData noise;
GenerateWhiteNoise(noise, ditherImage.m_width, ditherImage.m_height);
// dither the image
SImageData dither;
DitherWithTexture(ditherImage, noise, dither);
// integrate and put the current integration results into the dither image
ImageForEachPixel(
dither,
[&] (SColor& pixel, size_t pixelIndex)
{
float pixelValueFloat = float(pixel.R) / 255.0f;
integration[pixelIndex] = Lerp(integration[pixelIndex], pixelValueFloat, 1.0f / float(i+1));
uint8 integratedPixelValue = uint8(integration[pixelIndex] * 255.0f);
pixel.R = integratedPixelValue;
pixel.G = integratedPixelValue;
pixel.B = integratedPixelValue;
}
);
// do an integration test
IntegrationTest(dither, ditherImage, i, __FUNCTION__);
// save the results
SImageData combined;
ImageCombine2(noise, dither, combined);
ImageSave(combined, fileName);
}
}
//======================================================================================
void DitherInterleavedGradientNoiseAnimatedIntegrated (const SImageData& ditherImage)
{
printf("\n%s\n", __FUNCTION__);
std::vector<float> integration;
integration.resize(ditherImage.m_width * ditherImage.m_height);
std::fill(integration.begin(), integration.end(), 0.0f);
std::random_device rd;
std::mt19937 rng(rd());
std::uniform_real_distribution<float> dist(0.0f, 1000.0f);
// animate 8 frames
for (size_t i = 0; i < 8; ++i)
{
char fileName[256];
sprintf(fileName, "out/animint_ignoise%zu.bmp", i);
// make noise
SImageData noise;
GenerateInterleavedGradientNoise(noise, ditherImage.m_width, ditherImage.m_height, dist(rng), dist(rng));
// dither the image
SImageData dither;
DitherWithTexture(ditherImage, noise, dither);
// integrate and put the current integration results into the dither image
ImageForEachPixel(
dither,
[&](SColor& pixel, size_t pixelIndex)
{
float pixelValueFloat = float(pixel.R) / 255.0f;
integration[pixelIndex] = Lerp(integration[pixelIndex], pixelValueFloat, 1.0f / float(i + 1));
uint8 integratedPixelValue = uint8(integration[pixelIndex] * 255.0f);
pixel.R = integratedPixelValue;
pixel.G = integratedPixelValue;
pixel.B = integratedPixelValue;
}
);
// do an integration test
IntegrationTest(dither, ditherImage, i, __FUNCTION__);
// save the results
SImageData combined;
ImageCombine2(noise, dither, combined);
ImageSave(combined, fileName);
}
}
//======================================================================================
void DitherBlueNoiseAnimatedIntegrated (const SImageData& ditherImage, const SImageData blueNoise[8])
{
printf("\n%s\n", __FUNCTION__);
std::vector<float> integration;
integration.resize(ditherImage.m_width * ditherImage.m_height);
std::fill(integration.begin(), integration.end(), 0.0f);
// animate 8 frames
for (size_t i = 0; i < 8; ++i)
{
char fileName[256];
sprintf(fileName, "out/animint_bluenoise%zu.bmp", i);
// dither the image
SImageData dither;
DitherWithTexture(ditherImage, blueNoise[i], dither);
// integrate and put the current integration results into the dither image
ImageForEachPixel(
dither,
[&] (SColor& pixel, size_t pixelIndex)
{
float pixelValueFloat = float(pixel.R) / 255.0f;
integration[pixelIndex] = Lerp(integration[pixelIndex], pixelValueFloat, 1.0f / float(i+1));
uint8 integratedPixelValue = uint8(integration[pixelIndex] * 255.0f);
pixel.R = integratedPixelValue;
pixel.G = integratedPixelValue;
pixel.B = integratedPixelValue;
}
);
// do an integration test
IntegrationTest(dither, ditherImage, i, __FUNCTION__);
// save the results
SImageData combined;
ImageCombine2(blueNoise[i], dither, combined);
ImageSave(combined, fileName);
}
}
//======================================================================================
void DitherWhiteNoiseAnimatedGoldenRatio (const SImageData& ditherImage)
{
printf("\n%s\n", __FUNCTION__);
// make noise
SImageData noiseSrc;
GenerateWhiteNoise(noiseSrc, ditherImage.m_width, ditherImage.m_height);
SImageData noise;
ImageInit(noise, noiseSrc.m_width, noiseSrc.m_height);
SImageDataComplex noiseDFT;
SImageData noiseDFTMag;
// animate 8 frames
for (size_t i = 0; i < 8; ++i)
{
char fileName[256];
sprintf(fileName, "out/animgr_whitenoise%zu.bmp", i);
// add golden ratio to the noise after each frame
noise.m_pixels = noiseSrc.m_pixels;
float add = GoldenRatioMultiple(i);
ImageForEachPixel(
noise,
[&] (SColor& pixel, size_t pixelIndex)
{
float valueFloat = (float(pixel.R) / 255.0f) + add;
size_t valueBig = size_t(valueFloat * 255.0f);
uint8 value = uint8(valueBig % 256);
pixel.R = value;
pixel.G = value;
pixel.B = value;
}
);
// DFT the noise
if (c_doDFT)
{
ImageDFT(noise, noiseDFT);
GetMagnitudeData(noiseDFT, noiseDFTMag);
}
else
{
ImageInit(noiseDFTMag, noise.m_width, noise.m_height);
std::fill(noiseDFTMag.m_pixels.begin(), noiseDFTMag.m_pixels.end(), 0);
}
// Histogram test the noise
HistogramTest(noise, i, __FUNCTION__);
// dither the image
SImageData dither;
DitherWithTexture(ditherImage, noise, dither);
// save the results
SImageData combined;
ImageCombine3(noiseDFTMag, noise, dither, combined);
ImageSave(combined, fileName);
}
}
//======================================================================================
void DitherInterleavedGradientNoiseAnimatedGoldenRatio (const SImageData& ditherImage)
{
printf("\n%s\n", __FUNCTION__);
// make noise
SImageData noiseSrc;
GenerateInterleavedGradientNoise(noiseSrc, ditherImage.m_width, ditherImage.m_height, 0.0f, 0.0f);
SImageData noise;
ImageInit(noise, noiseSrc.m_width, noiseSrc.m_height);
SImageDataComplex noiseDFT;
SImageData noiseDFTMag;
// animate 8 frames
for (size_t i = 0; i < 8; ++i)
{
char fileName[256];
sprintf(fileName, "out/animgr_ignoise%zu.bmp", i);
// add golden ratio to the noise after each frame
noise.m_pixels = noiseSrc.m_pixels;
float add = GoldenRatioMultiple(i);
ImageForEachPixel(
noise,
[&] (SColor& pixel, size_t pixelIndex)
{
float valueFloat = (float(pixel.R) / 255.0f) + add;
size_t valueBig = size_t(valueFloat * 255.0f);
uint8 value = uint8(valueBig % 256);
pixel.R = value;
pixel.G = value;
pixel.B = value;
}
);
// DFT the noise
if (c_doDFT)
{
ImageDFT(noise, noiseDFT);
GetMagnitudeData(noiseDFT, noiseDFTMag);
}
else
{
ImageInit(noiseDFTMag, noise.m_width, noise.m_height);
std::fill(noiseDFTMag.m_pixels.begin(), noiseDFTMag.m_pixels.end(), 0);
}
// Histogram test the noise
HistogramTest(noise, i, __FUNCTION__);
// dither the image
SImageData dither;
DitherWithTexture(ditherImage, noise, dither);
// save the results
SImageData combined;
ImageCombine3(noiseDFTMag, noise, dither, combined);
ImageSave(combined, fileName);
}
}
//======================================================================================
void DitherBlueNoiseAnimatedGoldenRatio (const SImageData& ditherImage, const SImageData& noiseSrc)
{
printf("\n%s\n", __FUNCTION__);
SImageData noise;
ImageInit(noise, noiseSrc.m_width, noiseSrc.m_height);
SImageDataComplex noiseDFT;
SImageData noiseDFTMag;
// animate 8 frames
for (size_t i = 0; i < 8; ++i)
{
char fileName[256];
sprintf(fileName, "out/animgr_bluenoise%zu.bmp", i);
// add golden ratio to the noise after each frame
noise.m_pixels = noiseSrc.m_pixels;
float add = GoldenRatioMultiple(i);
ImageForEachPixel(
noise,
[&] (SColor& pixel, size_t pixelIndex)
{
float valueFloat = (float(pixel.R) / 255.0f) + add;
size_t valueBig = size_t(valueFloat * 255.0f);
uint8 value = uint8(valueBig % 256);
pixel.R = value;
pixel.G = value;
pixel.B = value;
}
);
// DFT the noise
if (c_doDFT)
{
ImageDFT(noise, noiseDFT);
GetMagnitudeData(noiseDFT, noiseDFTMag);
}
else
{
ImageInit(noiseDFTMag, noise.m_width, noise.m_height);
std::fill(noiseDFTMag.m_pixels.begin(), noiseDFTMag.m_pixels.end(), 0);
}
// Histogram test the noise
HistogramTest(noise, i, __FUNCTION__);
// dither the image
SImageData dither;
DitherWithTexture(ditherImage, noise, dither);
// save the results
SImageData combined;
ImageCombine3(noiseDFTMag, noise, dither, combined);
ImageSave(combined, fileName);
}
}
//======================================================================================
void DitherWhiteNoiseAnimatedGoldenRatioIntegrated (const SImageData& ditherImage)
{
printf("\n%s\n", __FUNCTION__);
std::vector<float> integration;
integration.resize(ditherImage.m_width * ditherImage.m_height);
std::fill(integration.begin(), integration.end(), 0.0f);
// make noise
SImageData noiseSrc;
GenerateWhiteNoise(noiseSrc, ditherImage.m_width, ditherImage.m_height);
SImageData noise;
ImageInit(noise, noiseSrc.m_width, noiseSrc.m_height);
// animate 8 frames
for (size_t i = 0; i < 8; ++i)
{
char fileName[256];
sprintf(fileName, "out/animgrint_whitenoise%zu.bmp", i);
// add golden ratio to the noise after each frame
noise.m_pixels = noiseSrc.m_pixels;
float add = GoldenRatioMultiple(i);
ImageForEachPixel(
noise,
[&] (SColor& pixel, size_t pixelIndex)
{
float valueFloat = (float(pixel.R) / 255.0f) + add;
size_t valueBig = size_t(valueFloat * 255.0f);
uint8 value = uint8(valueBig % 256);
pixel.R = value;
pixel.G = value;
pixel.B = value;
}
);
// dither the image
SImageData dither;
DitherWithTexture(ditherImage, noise, dither);
// integrate and put the current integration results into the dither image
ImageForEachPixel(
dither,
[&] (SColor& pixel, size_t pixelIndex)
{
float pixelValueFloat = float(pixel.R) / 255.0f;
integration[pixelIndex] = Lerp(integration[pixelIndex], pixelValueFloat, 1.0f / float(i+1));
uint8 integratedPixelValue = uint8(integration[pixelIndex] * 255.0f);
pixel.R = integratedPixelValue;
pixel.G = integratedPixelValue;
pixel.B = integratedPixelValue;
}
);
// do an integration test
IntegrationTest(dither, ditherImage, i, __FUNCTION__);
// save the results
SImageData combined;
ImageCombine2(noise, dither, combined);
ImageSave(combined, fileName);
}
}
//======================================================================================
void DitherInterleavedGradientNoiseAnimatedGoldenRatioIntegrated (const SImageData& ditherImage)
{
printf("\n%s\n", __FUNCTION__);
std::vector<float> integration;
integration.resize(ditherImage.m_width * ditherImage.m_height);
std::fill(integration.begin(), integration.end(), 0.0f);
// make noise
SImageData noiseSrc;
GenerateInterleavedGradientNoise(noiseSrc, ditherImage.m_width, ditherImage.m_height, 0.0f, 0.0f);
SImageData noise;
ImageInit(noise, noiseSrc.m_width, noiseSrc.m_height);
// animate 8 frames
for (size_t i = 0; i < 8; ++i)
{
char fileName[256];
sprintf(fileName, "out/animgrint_ignoise%zu.bmp", i);
// add golden ratio to the noise after each frame
noise.m_pixels = noiseSrc.m_pixels;
float add = GoldenRatioMultiple(i);
ImageForEachPixel(
noise,
[&] (SColor& pixel, size_t pixelIndex)
{
float valueFloat = (float(pixel.R) / 255.0f) + add;
size_t valueBig = size_t(valueFloat * 255.0f);
uint8 value = uint8(valueBig % 256);
pixel.R = value;
pixel.G = value;
pixel.B = value;
}
);
// dither the image
SImageData dither;
DitherWithTexture(ditherImage, noise, dither);
// integrate and put the current integration results into the dither image
ImageForEachPixel(
dither,
[&] (SColor& pixel, size_t pixelIndex)
{
float pixelValueFloat = float(pixel.R) / 255.0f;
integration[pixelIndex] = Lerp(integration[pixelIndex], pixelValueFloat, 1.0f / float(i+1));
uint8 integratedPixelValue = uint8(integration[pixelIndex] * 255.0f);
pixel.R = integratedPixelValue;
pixel.G = integratedPixelValue;
pixel.B = integratedPixelValue;
}
);
// do an integration test
IntegrationTest(dither, ditherImage, i, __FUNCTION__);
// save the results
SImageData combined;
ImageCombine2(noise, dither, combined);
ImageSave(combined, fileName);
}
}
//======================================================================================
void DitherBlueNoiseAnimatedGoldenRatioIntegrated (const SImageData& ditherImage, const SImageData& noiseSrc)
{
printf("\n%s\n", __FUNCTION__);
std::vector<float> integration;
integration.resize(ditherImage.m_width * ditherImage.m_height);
std::fill(integration.begin(), integration.end(), 0.0f);
SImageData noise;
ImageInit(noise, noiseSrc.m_width, noiseSrc.m_height);
// animate 8 frames
for (size_t i = 0; i < 8; ++i)
{
char fileName[256];
sprintf(fileName, "out/animgrint_bluenoise%zu.bmp", i);
// add golden ratio to the noise after each frame
noise.m_pixels = noiseSrc.m_pixels;
float add = GoldenRatioMultiple(i);
ImageForEachPixel(
noise,
[&] (SColor& pixel, size_t pixelIndex)
{
float valueFloat = (float(pixel.R) / 255.0f) + add;
size_t valueBig = size_t(valueFloat * 255.0f);
uint8 value = uint8(valueBig % 256);
pixel.R = value;
pixel.G = value;
pixel.B = value;
}
);
// dither the image
SImageData dither;
DitherWithTexture(ditherImage, noise, dither);
// integrate and put the current integration results into the dither image
ImageForEachPixel(
dither,
[&] (SColor& pixel, size_t pixelIndex)
{
float pixelValueFloat = float(pixel.R) / 255.0f;
integration[pixelIndex] = Lerp(integration[pixelIndex], pixelValueFloat, 1.0f / float(i+1));
uint8 integratedPixelValue = uint8(integration[pixelIndex] * 255.0f);
pixel.R = integratedPixelValue;
pixel.G = integratedPixelValue;
pixel.B = integratedPixelValue;
}
);
// do an integration test
IntegrationTest(dither, ditherImage, i, __FUNCTION__);
// save the results
SImageData combined;
ImageCombine2(noise, dither, combined);
ImageSave(combined, fileName);
}
}
//======================================================================================
int main (int argc, char** argv)
{
// load the dither image and convert it to greyscale (luma)
SImageData ditherImage;
if (!ImageLoad("src/ditherimage.bmp", ditherImage))
{
printf("Could not load src/ditherimage.bmp");
return 0;
}
ImageConvertToLuma(ditherImage);
// load the blue noise images.
SImageData blueNoise[8];
for (size_t i = 0; i < 8; ++i)
{
char buffer[256];
sprintf(buffer, "src/BN%zu.bmp", i);
if (!ImageLoad(buffer, blueNoise[i]))
{
printf("Could not load %s", buffer);
return 0;
}
// They have different values in R, G, B so make R be the value for all channels
ImageForEachPixel(
blueNoise[i],
[] (SColor& pixel, size_t pixelIndex)
{
pixel.G = pixel.R;
pixel.B = pixel.R;
}
);
}
g_logFile = fopen("log.txt", "w+t");
// still image dither tests
DitherWhiteNoise(ditherImage);
DitherInterleavedGradientNoise(ditherImage);
DitherBlueNoise(ditherImage, blueNoise[0]);
// Animated dither tests
DitherWhiteNoiseAnimated(ditherImage);
DitherInterleavedGradientNoiseAnimated(ditherImage);
DitherBlueNoiseAnimated(ditherImage, blueNoise);
// Golden ratio animated dither tests
DitherWhiteNoiseAnimatedGoldenRatio(ditherImage);
DitherInterleavedGradientNoiseAnimatedGoldenRatio(ditherImage);
DitherBlueNoiseAnimatedGoldenRatio(ditherImage, blueNoise[0]);
// Animated dither integration tests
DitherWhiteNoiseAnimatedIntegrated(ditherImage);
DitherInterleavedGradientNoiseAnimatedIntegrated(ditherImage);
DitherBlueNoiseAnimatedIntegrated(ditherImage, blueNoise);
// Golden ratio animated dither integration tests
DitherWhiteNoiseAnimatedGoldenRatioIntegrated(ditherImage);
DitherInterleavedGradientNoiseAnimatedGoldenRatioIntegrated(ditherImage);
DitherBlueNoiseAnimatedGoldenRatioIntegrated(ditherImage, blueNoise[0]);
fclose(g_logFile);
return 0;
}






























































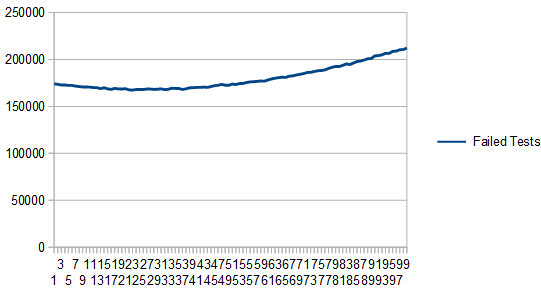
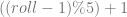 . This works because there is no remainder for 20 % 5. If there was a remainder it would bias the rolls towards the numbers <= the remainder, making them more likely to come up than the other numbers.
. This works because there is no remainder for 20 % 5. If there was a remainder it would bias the rolls towards the numbers <= the remainder, making them more likely to come up than the other numbers.
 .
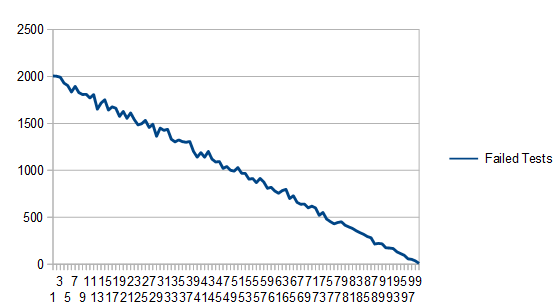
. where x is in [0,1) and I'm using a box that goes from (0,0) to (1,2) to get 100,000 samples.
where x is in [0,1) and I'm using a box that goes from (0,0) to (1,2) to get 100,000 samples.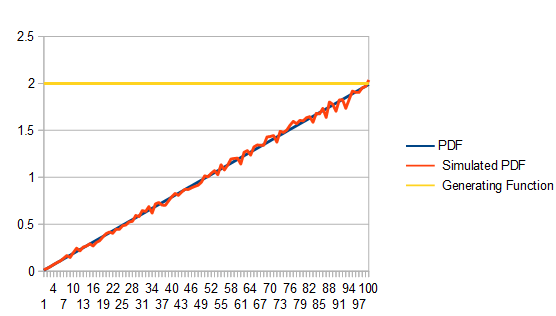
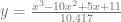
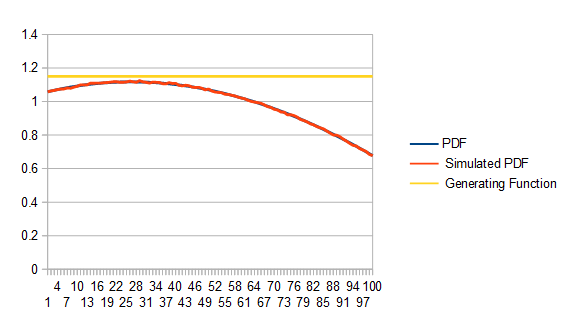


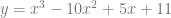


 , you can use any PDF
, you can use any PDF 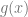 to do so, so long as you multiply
to do so, so long as you multiply 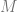 so that
so that 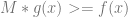 for all values of x. In other words: scale up g so that it’s always bigger than f.
for all values of x. In other words: scale up g so that it’s always bigger than f.
 . We’ll use an
. We’ll use an 


 where
where ![x \in [0,1]](https://s0.wp.com/latex.php?latex=x+%5Cin+%5B0%2C1%5D&bg=ffffff&fg=666666&s=0&c=20201002) . The graph looks like this:
. The graph looks like this:
 where
where 


 which looks like this:
which looks like this:
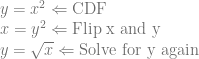
 and looks like this:
and looks like this:



 . The area under that curve where x is in [0,1) is 1.0 and it’s non negative everywhere in that range too, so it’s a valid PDF.
. The area under that curve where x is in [0,1) is 1.0 and it’s non negative everywhere in that range too, so it’s a valid PDF. for the CDF. Then we invert the CDF:
for the CDF. Then we invert the CDF:![y=x^3 \Leftarrow \text{CDF}\\ x=y^3 \Leftarrow \text{Flip x and y}\\ y=\sqrt[3]{x} \Leftarrow \text{Solve for y again}](https://s0.wp.com/latex.php?latex=y%3Dx%5E3+%5CLeftarrow+%5Ctext%7BCDF%7D%5C%5C+x%3Dy%5E3+%5CLeftarrow+%5Ctext%7BFlip+x+and+y%7D%5C%5C+y%3D%5Csqrt%5B3%5D%7Bx%7D+%5CLeftarrow+%5Ctext%7BSolve+for+y+again%7D&bg=ffffff&fg=666666&s=0&c=20201002)







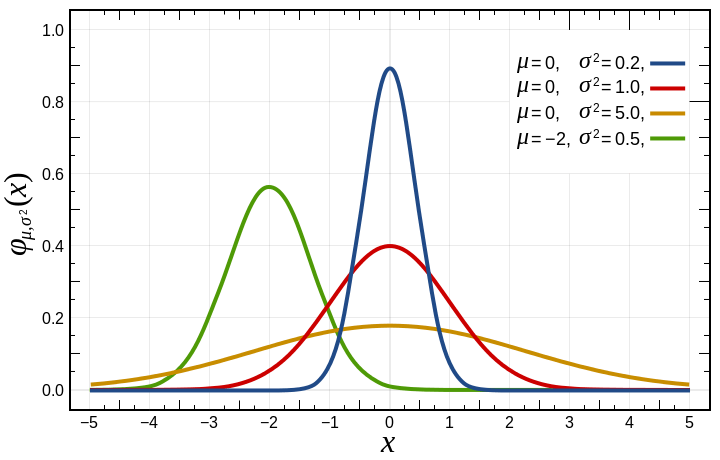
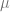 – “mu” is the mean. This is the average value of the distribution. This is where the center (peak) of the curve is on the x axis.
– “mu” is the mean. This is the average value of the distribution. This is where the center (peak) of the curve is on the x axis. – “sigma squared” is the variance, and is just the standard deviation squared. I find standard deviation more intuitive to think about.
– “sigma squared” is the variance, and is just the standard deviation squared. I find standard deviation more intuitive to think about.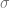 – “sigma” is the standard deviation, which (surprise surprise!) is the square root of the variance. This controls the “width” of the graph. The area under the cover is 1.0, so as you increase standard deviation and make the graph wider, it also gets shorter.
– “sigma” is the standard deviation, which (surprise surprise!) is the square root of the variance. This controls the “width” of the graph. The area under the cover is 1.0, so as you increase standard deviation and make the graph wider, it also gets shorter.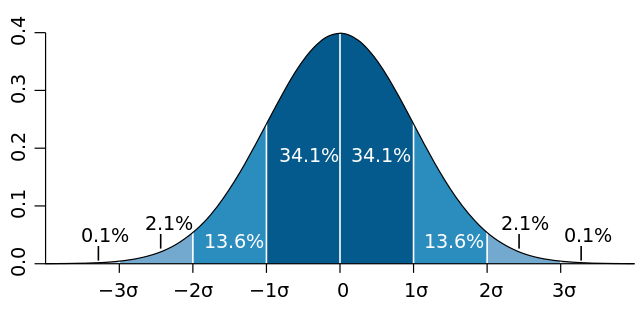
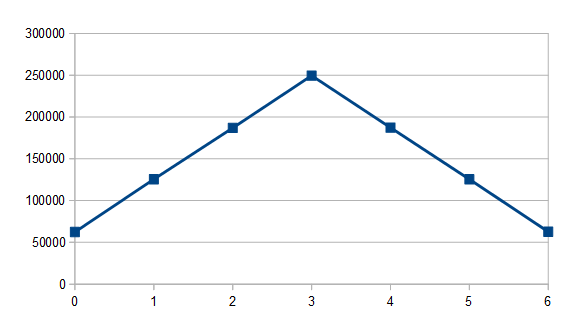
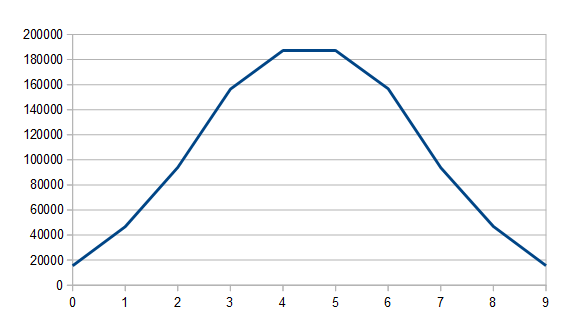
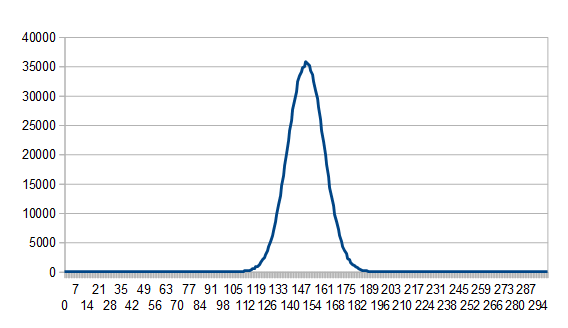
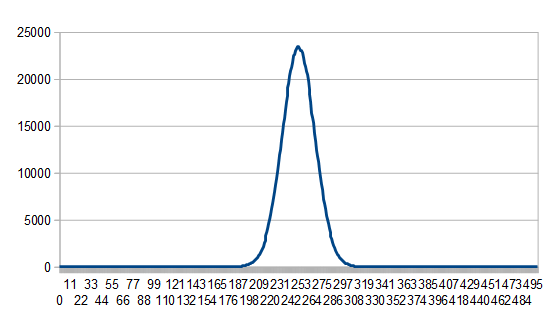
 . Note that if you instead are generating random numbers in [1,N], the mean instead is
. Note that if you instead are generating random numbers in [1,N], the mean instead is  .
.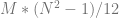 . The standard deviation is the square root of that.
. The standard deviation is the square root of that.




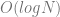 steps, where
steps, where  is the number of items in the list. In this post’s solution, it always takes
is the number of items in the list. In this post’s solution, it always takes  steps.
steps.

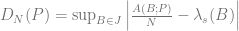













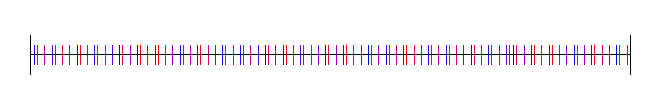





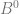 ,
, 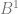 ,
,  , etc (where B is the base), you instead treat them as
, etc (where B is the base), you instead treat them as 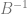 ,
, 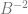 ,
, 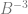 and so on. In other words, you multiply each digit by a fraction and add up the results.
and so on. In other words, you multiply each digit by a fraction and add up the results. , so we can see that 110 is in fact 6 in binary.
, so we can see that 110 is in fact 6 in binary.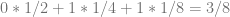 .
.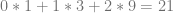 .
.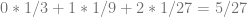




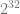





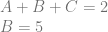


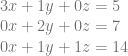
![\left[\begin{array}{rrr} 3 & 1 & 0 \\ 0 & 2 & 0 \\ 0 & 1 & 1 \end{array}\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B%5Cbegin%7Barray%7D%7Brrr%7D+3+%26+1+%26+0+%5C%5C+0+%26+2+%26+0+%5C%5C+0+%26+1+%26+1+%5Cend%7Barray%7D%5Cright%5D+&bg=ffffff&fg=666666&s=0&c=20201002)
![\left[\begin{array}{rrr|r} 3 & 1 & 0 & 5 \\ 0 & 2 & 0 & 7 \\ 0 & 1 & 1 & 14 \end{array}\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B%5Cbegin%7Barray%7D%7Brrr%7Cr%7D+3+%26+1+%26+0+%26+5+%5C%5C+0+%26+2+%26+0+%26+7+%5C%5C+0+%26+1+%26+1+%26+14+%5Cend%7Barray%7D%5Cright%5D+&bg=ffffff&fg=666666&s=0&c=20201002)
![\left[\begin{array}{rrrrr} 1 & 0 & a_1 & 0 & b_1 \\ 0 & 1 & a_2 & 0 & b_2 \\ 0 & 0 & 0 & 1 & b_3 \end{array}\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B%5Cbegin%7Barray%7D%7Brrrrr%7D+1+%26+0+%26+a_1+%26+0+%26+b_1+%5C%5C+0+%26+1+%26+a_2+%26+0+%26+b_2+%5C%5C+0+%26+0+%26+0+%26+1+%26+b_3+%5Cend%7Barray%7D%5Cright%5D+&bg=ffffff&fg=666666&s=0&c=20201002)
![\left[\begin{array}{rrr|r} 1 & 0 & 0 & 0.5 \\ 0 & 1 & 0 & 3.5 \\ 0 & 0 & 1 & 10.5 \end{array}\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B%5Cbegin%7Barray%7D%7Brrr%7Cr%7D+1+%26+0+%26+0+%26+0.5+%5C%5C+0+%26+1+%26+0+%26+3.5+%5C%5C+0+%26+0+%26+1+%26+10.5+%5Cend%7Barray%7D%5Cright%5D+&bg=ffffff&fg=666666&s=0&c=20201002)


![\left[\begin{array}{rrr|r} 1 & 0.3333 & 0 & 1.6666 \\ 0 & 2 & 0 & 7 \\ 0 & 1 & 1 & 14 \end{array}\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B%5Cbegin%7Barray%7D%7Brrr%7Cr%7D+1+%26+0.3333+%26+0+%26+1.6666+%5C%5C+0+%26+2+%26+0+%26+7+%5C%5C+0+%26+1+%26+1+%26+14+%5Cend%7Barray%7D%5Cright%5D+&bg=ffffff&fg=666666&s=0&c=20201002)
![\left[\begin{array}{rrr|r} 1 & 0.3333 & 0 & 1.6666 \\ 0 & 1 & 0 & 3.5 \\ 0 & 1 & 1 & 14 \end{array}\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B%5Cbegin%7Barray%7D%7Brrr%7Cr%7D+1+%26+0.3333+%26+0+%26+1.6666+%5C%5C+0+%26+1+%26+0+%26+3.5+%5C%5C+0+%26+1+%26+1+%26+14+%5Cend%7Barray%7D%5Cright%5D+&bg=ffffff&fg=666666&s=0&c=20201002)

![\left[\begin{array}{rr|r} 1 & 1 & 3 \\ 1 & 0 & 1 \\ 0 & 1 & 2 \end{array}\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B%5Cbegin%7Barray%7D%7Brr%7Cr%7D+1+%26+1+%26+3+%5C%5C+1+%26+0+%26+1+%5C%5C+0+%26+1+%26+2+%5Cend%7Barray%7D%5Cright%5D+&bg=ffffff&fg=666666&s=0&c=20201002)
![\left[\begin{array}{rr|r} 1 & 0 & 1 \\ 0 & 1 & 2 \\ 0 & 0 & 0 \end{array}\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B%5Cbegin%7Barray%7D%7Brr%7Cr%7D+1+%26+0+%26+1+%5C%5C+0+%26+1+%26+2+%5C%5C+0+%26+0+%26+0+%5Cend%7Barray%7D%5Cright%5D+&bg=ffffff&fg=666666&s=0&c=20201002)

![\left[\begin{array}{rr|r} 1 & 1 & 3 \\ 1 & 0 & 1 \\ 0 & 1 & 10 \end{array}\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B%5Cbegin%7Barray%7D%7Brr%7Cr%7D+1+%26+1+%26+3+%5C%5C+1+%26+0+%26+1+%5C%5C+0+%26+1+%26+10+%5Cend%7Barray%7D%5Cright%5D+&bg=ffffff&fg=666666&s=0&c=20201002)
![\left[\begin{array}{rr|r} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{array}\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B%5Cbegin%7Barray%7D%7Brr%7Cr%7D+1+%26+0+%26+0+%5C%5C+0+%26+1+%26+0+%5C%5C+0+%26+0+%26+1+%5Cend%7Barray%7D%5Cright%5D+&bg=ffffff&fg=666666&s=0&c=20201002)


![\left[\begin{array}{rrr|r} 1 & 1 & 1 & 2 \\ 0 & 1 & 0 & 5 \\ \end{array}\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B%5Cbegin%7Barray%7D%7Brrr%7Cr%7D+1+%26+1+%26+1+%26+2+%5C%5C+0+%26+1+%26+0+%26+5+%5C%5C+%5Cend%7Barray%7D%5Cright%5D+&bg=ffffff&fg=666666&s=0&c=20201002)
![\left[\begin{array}{rrr|r} 1 & 0 & 1 & -3 \\ 0 & 1 & 0 & 5 \\ \end{array}\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B%5Cbegin%7Barray%7D%7Brrr%7Cr%7D+1+%26+0+%26+1+%26+-3+%5C%5C+0+%26+1+%26+0+%26+5+%5C%5C+%5Cend%7Barray%7D%5Cright%5D+&bg=ffffff&fg=666666&s=0&c=20201002)
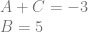

![\left[\begin{array}{rrr|r} 1 & 1 & 1 & 2 \\ 0 & 1 & 0 & 5 \\ 0 & -1 & 0 & -5 \\ \end{array}\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B%5Cbegin%7Barray%7D%7Brrr%7Cr%7D+1+%26+1+%26+1+%26+2+%5C%5C+0+%26+1+%26+0+%26+5+%5C%5C+0+%26+-1+%26+0+%26+-5+%5C%5C+%5Cend%7Barray%7D%5Cright%5D+&bg=ffffff&fg=666666&s=0&c=20201002)
![\left[\begin{array}{rrr|r} 1 & 0 & 1 & -3 \\ 0 & 1 & 0 & 5 \\ 0 & 0 & 0 & 0 \\ \end{array}\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B%5Cbegin%7Barray%7D%7Brrr%7Cr%7D+1+%26+0+%26+1+%26+-3+%5C%5C+0+%26+1+%26+0+%26+5+%5C%5C+0+%26+0+%26+0+%26+0+%5C%5C+%5Cend%7Barray%7D%5Cright%5D+&bg=ffffff&fg=666666&s=0&c=20201002)
![\left[\begin{array}{rrr|rrr} 1 & 0 & 1 & 1 & 0 & 0 \\ 0 & 3 & 0 & 0 & 1 & 0 \\ 0 & 0 & 1 & 0 & 0 & 1\\ \end{array}\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B%5Cbegin%7Barray%7D%7Brrr%7Crrr%7D+1+%26+0+%26+1+%26+1+%26+0+%26+0+%5C%5C+0+%26+3+%26+0+%26+0+%26+1+%26+0+%5C%5C+0+%26+0+%26+1+%26+0+%26+0+%26+1%5C%5C+%5Cend%7Barray%7D%5Cright%5D+&bg=ffffff&fg=666666&s=0&c=20201002)
![\left[\begin{array}{rrr|rrr} 1 & 0 & 0 & 1 & 0 & -1 \\ 0 & 1 & 0 & 0 & 0.3333 & 0 \\ 0 & 0 & 1 & 0 & 0 & 1\\ \end{array}\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B%5Cbegin%7Barray%7D%7Brrr%7Crrr%7D+1+%26+0+%26+0+%26+1+%26+0+%26+-1+%5C%5C+0+%26+1+%26+0+%26+0+%26+0.3333+%26+0+%5C%5C+0+%26+0+%26+1+%26+0+%26+0+%26+1%5C%5C+%5Cend%7Barray%7D%5Cright%5D+&bg=ffffff&fg=666666&s=0&c=20201002)

![\left[\begin{array}{rrr|r} 2 & 0 & 0 & 2 \\ 0 & 2 & 0 & 4 \\ 0 & 0 & 2 & 8 \\ \end{array}\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B%5Cbegin%7Barray%7D%7Brrr%7Cr%7D+2+%26+0+%26+0+%26+2+%5C%5C+0+%26+2+%26+0+%26+4+%5C%5C+0+%26+0+%26+2+%26+8+%5C%5C+%5Cend%7Barray%7D%5Cright%5D+&bg=ffffff&fg=666666&s=0&c=20201002)
![\left[\begin{array}{rrr|r} 1 & 0 & 0 & 1 \\ 0 & 1 & 0 & 2 \\ 0 & 0 & 1 & 4 \\ \end{array}\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B%5Cbegin%7Barray%7D%7Brrr%7Cr%7D+1+%26+0+%26+0+%26+1+%5C%5C+0+%26+1+%26+0+%26+2+%5C%5C+0+%26+0+%26+1+%26+4+%5C%5C+%5Cend%7Barray%7D%5Cright%5D+&bg=ffffff&fg=666666&s=0&c=20201002)
