
The other day I was thinking about how you might do a binary search branchlessly. I came up with a way, and I’m pretty sure I’m not the first to come up with it, but it was fun to think about and I wanted to share my solution.
All code in this post is public domain.
Here it is searching a list of 8 items in 3 steps:
size_t BinarySearch8 (size_t needle, const size_t haystack[8])
{
size_t ret = (haystack[4] <= needle) ? 4 : 0;
ret += (haystack[ret + 2] <= needle) ? 2 : 0;
ret += (haystack[ret + 1] <= needle) ? 1 : 0;
return ret;
}
The three steps it does are:
- The list has 8 items in it. We test index 4 to see if we need to continue searching index 0 to 3, or index 4 to 7. The returned index becomes either 0xx or 1xx.
- The list has 4 items in it now. We test index 2 to see if we need to continue searching index 0 to 1, or index 2 to 3. The returned index becomes one of the following: 00x, 01x, 10x or 11x.
- The list has 2 items in it. We test index 1 to see if we need to take the left item or the right item. The returned index becomes: 000, 001, 010, 011, 100, 101, 110, or 111.
But Big O Complexity is Worse!
Usually a binary search can take up to 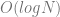


It probably seems odd that this branchless version could be considered an improvement when it has big O complexity that is always the worst case of a regular binary search. That is strange, but in the world of SIMD and shader programs, going branchless can be a big win that is not captured by looking at big O complexity. (Note that cache coherancy and thread contention are two other things not captured by looking at big O complexity).
Also, when working in something like video games or other interactive simulations, an even frame rate is more important than a high frame rate for making a game look and feel smooth. Because of this, if you have algorithms that have very fast common cases but much slower worst cases, you may actually prefer to use an algorithm that is slower in the common case but faster in the worst case just to keep performance more consistent. Using an algorithm such as this, which has a constant amount of work regardless of input can be a good trade off there.
Lastly, in cryptographic applications, attackers can gather secret information by seeing how long certain operations take. For instance, if you use a shorter password than other people, an attacker may be able to detect that by seeing that it consistently takes you a little bit less time to login than other people. They now have an idea of the length of your password, and maybe will brute force you, knowing that you are low hanging fruit!
These timing based attacks can be thwarted by algorithms which run at a constant time regardless of input. This algorithm is one of those algorithms.
As an example of another algorithm that runs in constant time regardless of input, check out CORDIC math. I really want to write up a post on that someday, it’s pretty cool stuff.
Traditional Binary Searching
You might have noticed that if the item you are searching for isn’t in the list, the function doesn’t return anything indicating that, and you might think that’s strange.
This function actually just returns the largest index that isn’t greater than the value you are searching for. If all the numbers are greater than the value you are searching for, it returns zero.
This might seem odd but this can actually come in handy if the list you are searching represents something like animation data, where there are keyframes sorted by time, and you want to find which two keyframes you are between so that you can interpolate.
To actually test if your value was in the list, you could do an extra check:
size_t searchValue = 3;
size_t index = BinarySearch8(searchValue, list);
bool found = (list[index] == searchValue);
If you need that extra check, it’s easy enough to add, and if you don’t need that extra check, it’s nice to not have it.
Without Ternary Operator
If in your setup you don’t have a ternary operator, or if the ternary operator isn’t branchless for you, you get the same results using multiplication:
size_t BinarySearch8 (size_t needle, const size_t haystack[8])
{
size_t ret = (haystack[4] <= needle) * 4;
ret += (haystack[ret + 2] <= needle) * 2;
ret += (haystack[ret + 1] <= needle) * 1;
return ret;
}
Note that on some platforms, the less than or equal test will be a branch! None of the platforms or compilers I tested had that issue but if you find yourself hitting that issue, you can do a branchless test via subtraction or similar.
Here is a godbolt link that lets you view the assembly for various compilers. When you open the link you’ll see clang doing this work branchlessly.
View Assembly
@adamjmiles from twitter also verified that GCN does it branchlessly, which you can see at the link below. Thanks for that!
View GCN Assembly
Something to keep in mind for the non GPU case though is that if you were doing this in SIMD, you’d be using SIMD intrinsics.
Larger Lists
It’s trivial to search larger numbers of values. Here it is searching 16 items in 4 steps:
size_t BinarySearch16 (size_t needle, const size_t haystack[16])
{
size_t ret = (haystack[8] <= needle) ? 8 : 0;
ret += (haystack[ret + 4] <= needle) ? 4 : 0;
ret += (haystack[ret + 2] <= needle) ? 2 : 0;
ret += (haystack[ret + 1] <= needle) ? 1 : 0;
return ret;
}
And here it is searching 32 items in 5 steps:
size_t BinarySearch32 (size_t needle, const size_t haystack[32])
{
size_t ret = (haystack[16] <= needle) ? 16 : 0;
ret += (haystack[ret + 8] <= needle) ? 8 : 0;
ret += (haystack[ret + 4] <= needle) ? 4 : 0;
ret += (haystack[ret + 2] <= needle) ? 2 : 0;
ret += (haystack[ret + 1] <= needle) ? 1 : 0;
return ret;
}
Non Power of 2 Lists
Let’s say that your list is not a perfect power of two in length. GASP!
You can still use the technique, but you treat it as if it has the next power of 2 up items, and then make sure your indices stay in range. The nice part here is that you don’t have to do extra work on the index at each step of the way, only in the places where it’s possible for the index to go out of range.
Here it is searching an array of size 7 in 3 steps:
size_t BinarySearch7 (size_t needle, const size_t haystack[7])
{
size_t ret = 0;
size_t testIndex = 0;
// test index is at most 4, so is within range.
testIndex = ret + 4;
ret = (haystack[testIndex] <= needle) ? testIndex : ret;
// test index is at most 6, so is within range.
testIndex = ret + 2;
ret = (haystack[testIndex] <= needle) ? testIndex : ret;
// test index is at most 7, so could be out of range.
// use min() to make sure the index stays in range.
testIndex = std::min<size_t>(ret + 1, 6);
ret = (haystack[testIndex] <= needle) ? testIndex : ret;
return ret;
}
There are some other techniques for dealing with non power of 2 sized lists that you can find in the links at the bottom, but there was one particularly interesting that my friend and ex boss James came up with.
Basically, you start out with something like this if you were searching a list of 7 items:
// 7 because the list has 7 items in it.
// 4 because it's half of the next power of 2 that is <= 7.
ret = (haystack[4] <= needle) * (7-4);
The result is that instead of having ret go to either 0 or 4, it goes to 0 or 3.
From there, in both cases you have 4 items in your sublist remaining, so you don’t need to worry about the index going out of bounds from that point on.
Code
Here’s some working code demonstrating the ideas above, as well as it’s output.

#include <algorithm>
#include <stdlib.h>
size_t BinarySearch8 (size_t needle, const size_t haystack[8])
{
// using ternary operator
size_t ret = (haystack[4] <= needle) ? 4 : 0;
ret += (haystack[ret + 2] <= needle) ? 2 : 0;
ret += (haystack[ret + 1] <= needle) ? 1 : 0;
return ret;
}
size_t BinarySearch8b (size_t needle, const size_t haystack[8])
{
// using multiplication
size_t ret = (haystack[4] <= needle) * 4;
ret += (haystack[ret + 2] <= needle) * 2;
ret += (haystack[ret + 1] <= needle) * 1;
return ret;
}
size_t BinarySearch7 (size_t needle, const size_t haystack[7])
{
// non perfect power of 2. use min() to keep it from going out of bounds.
size_t ret = 0;
size_t testIndex = 0;
// test index is 4, so is within range.
testIndex = ret + 4;
ret = (haystack[testIndex] <= needle) ? testIndex : ret;
// test index is at most 6, so is within range.
testIndex = ret + 2;
ret = (haystack[testIndex] <= needle) ? testIndex : ret;
// test index is at most 7, so could be out of range.
// use min() to make sure the index stays in range.
testIndex = std::min<size_t>(ret + 1, 6);
ret = (haystack[testIndex] <= needle) ? testIndex : ret;
return ret;
}
int main (int argc, char **argv)
{
// search a list of size 8
{
// show the data
printf("Seaching through a list with 8 items:\n");
size_t data[8] = { 1, 3, 5, 6, 9, 11, 15, 21 };
printf("data = [");
for (size_t i = 0; i < sizeof(data)/sizeof(data[0]); ++i)
{
if (i > 0)
printf(", ");
printf("%zu", data[i]);
}
printf("]\n");
// do some searches on it using ternary operation based function
printf("\nTernary based searches:\n");
#define FIND(needle) printf("Find " #needle ": index = %zu, value = %zu, found = %s\n", BinarySearch8(needle, data), data[BinarySearch8(needle, data)], data[BinarySearch8(needle, data)] == needle ? "true" : "false");
FIND(2);
FIND(3);
FIND(0);
FIND(22);
FIND(16);
FIND(15);
FIND(21);
#undef FIND
// do some searches on it using multiplication based function
printf("\nMultiplication based searches:\n");
#define FIND(needle) printf("Find " #needle ": index = %zu, value = %zu, found = %s\n", BinarySearch8b(needle, data), data[BinarySearch8b(needle, data)], data[BinarySearch8b(needle, data)] == needle ? "true" : "false");
FIND(2);
FIND(3);
FIND(0);
FIND(22);
FIND(16);
FIND(15);
FIND(21);
#undef FIND
printf("\n\n\n\n");
}
// search a list of size 7
{
// show the data
printf("Seaching through a list with 7 items:\n");
size_t data[7] = { 1, 3, 5, 6, 9, 11, 15};
printf("data = [");
for (size_t i = 0; i < sizeof(data)/sizeof(data[0]); ++i)
{
if (i > 0)
printf(", ");
printf("%zu", data[i]);
}
printf("]\n");
// do some searches on it using ternary operation based function
printf("\nTernary based searches:\n");
#define FIND(needle) printf("Find " #needle ": index = %zu, value = %zu, found = %s\n", BinarySearch7(needle, data), data[BinarySearch7(needle, data)], data[BinarySearch7(needle, data)] == needle ? "true" : "false");
FIND(2);
FIND(3);
FIND(0);
FIND(22);
FIND(16);
FIND(15);
FIND(21);
#undef FIND
printf("\n\n\n\n");
}
system("pause");
return 0;
}
Closing
Another facet of binary searching is that it isn’t the most cache friendly algorithm out there. There might be some value in combining the above with the information in the link below.
If you like this sort of thing, here is an interesting paper from this year (2017):
Array Layouts For Comparison-Based Searching
And further down the rabbit hole a bit, this talks about re-ordering the search array to fit things into a cache line better:
https://people.mpi-inf.mpg.de/~rgemulla/publications/schlegel09search.pdf
Taking the next step is Intel and Oracle’s FAST paper:
http://www.timkaldewey.de/pubs/FAST__TODS11.pdf
Florian Gross from twitch made me aware of the last two links and also mentioned his master’s these in this area (thank you Florian!):
https://www.researchgate.net/profile/Florian_Gross/publication/275971053_Index_Search_Algorithms_for_Databases_and_Modern_CPUs/links/554cffca0cf29f836c9cd539.pdf
@rygorous mentioned on twitter some improvements such as ternary and quaternary search, as well as a way to handle the case of non power of 2 sized lists without extra index checks:
https://twitter.com/rygorous/status/877418592752488449/photo/1
Thanks to everyone who gave feedback. It’s a very interesting topic, of which this post only seems to scratch this surface!
Hopefully you found this interesting. Questions, comments, corrections, let me know!

For the size 7 case, you can also test indices 3, 2, 1, without any clamping, right? Or for the general non-power-of-2 case, start with test index n – 2^k, where k is maximal such that 2^k < n.
LikeLike
That would totally work, yep. There’s a variant someone came up with where for the “search 7” case, you test index 3 first, and the index to continue from is either going to be 0 or 3. Since both of those sublists have 4 items, you can continue the search without worrying about indices out of range.
LikeLike
This is not branchless: as soon as you have a test like <=, the compiler will translate that into a CMP … BLE sequence, which is a branch. Look at the generated assembler code.
LikeLike
Well, if writing SIMD code, you’d be using SIMD intrinsics, and if working on the GPU, it’s a different instruction set (here shows GCN doing it branchlessly: https://twitter.com/adamjmiles/status/877310625864613888)
But not all compilers do what you are saying either (nor do they all do what i say apparently, what compiler did you test on?). Here’s clang doing it branchlessly. GCC does as well, and MSVC was doing it branchlessly for me.
https://t.co/wvt7lRrfIA
LikeLike
> as soon as you have a test like <=, the compiler will translate that into a CMP. Not true – from ternary operator compiler might generate CMOV (conditional move) instruction(s)
LikeLike
Just to be sure, as I might have a different interpretation of branchless.
What you’re avoiding are jumps, not conditionals?
I haven’t benchmarked if it has any advantages, but here’s another version, which compiles to condtional moves and is two instructions shorter: https://godbolt.org/g/YYaRQZ
LikeLike
Right, I’m avoiding divergent execution paths, which are painful in SIMD and GPU programming. Conditionals would be a secondary thing to avoid for sure though (:
LikeLike
Pingback: 【知识】6月22日 – 每日安全知识热点-安全路透社
Pingback: 半月安全看看看2017六月(下) – 安全0day
Pingback: Performance comparison: linear search vs binary search. | Dirty hands coding
Pingback: Linear Fit Search « The blog at the bottom of the sea