There are two performance implications of using std::function that might surprise you:
- When calling a std::function, it does a virtual function call.
- When assigning a lambda with significant captures to a std::function, it will do a dynamic memory allocation!
Here is an example of what I mean:
array i;
auto A = [=] () -> int {
return (i[0] + i[1] * i[2] + i[3]) ^ i[4];
};
// A dynamic memory allocation of sizeof(A) + some change is done on assignment
// sizeof(A) = 20 on my machine, and it ends up doing a 28 byte allocation from the heap.
function fA = A;
// A virtual function is called to be able to execute A()
int ret = fA();
The reason for the virtual function call is because under the hood, a lambda creates a class that contains the code and all the captured data you specified for capture. Since other callers of your std::function have no idea what the type of that object is (it’s only visible in the scope the lambda was defined in, and is not a human friendly name), the std::function has to use a virtual function to “blindly” call into from the outside, to perform the correct work on the inside. This technique is called “type erasure” and you can read more about it in the links section at the bottom of this post!
The reason for the dynamic memory allocation is that std::function is generic and has no idea how much data you captured, but that captured data has to exist inside of a std::function and also has to be able to be copied as a std::function is moved around or copied to other locations. It needs the storage space for your captures.
That is unfortunate in the cases of when you don’t plan on using the lambda in those ways though. Your data is already on the stack, it would be great if it could just use THAT copy of the captures and avoid the allocation.
If you capture only a small amount (in the implementations I’ve seen, typically something around 8 bytes max… so 2 pointers or references worth), it doesn’t have to allocate, as it has a small static buffer for use in these “small capture” cases. That’s a nice optimization, but the allocations can still sneak in and bite us when we least expect it, so we have to be careful.
Avoid Both Problems With Template Parameters
If you are passing a lambda to some other code to execute, you can avoid both problems by using templated functions like below:
template <typename T>
void RunLambda (const T &lambda)
{
// No virtual function calls or dynamic memory allocations!
lambda();
}
You could then call that function like this and it’ll deduce the type of the lambda as the template parameter:
RunLambda([] () {printf("hello world!");});
The reason why this works, is because your lambda does have an actual type (even if we don’t know what it is, and can’t really type what it is). The template function is able to make a version of itself for the specific type that the lamdba is, and it can make a custom shrink wrapped function to call it.
In my experiences, it’s also able to inline the lambda code & template function, which is pretty awesome since then it’s basically no extra overhead at all.
The problem going this route though, is that you hit the usual problems of templated functions: without jumping through extra hoops, you have to put the implementation of the function in the header file.
The rest of the solutions i present get rid of the allocation, but the virtual call remains. The allocation is the real monster here though, and if you really have to avoid the virtual function call too, you can always resort to using template functions.
Solution 1: Wrapping
Like I said above, a lambda makes a type for you behind the scenes that contains your code and capture storage.
If this type is small enough, if won’t require dynamic allocation to hold it in a std::function.
So, let’s say we have a lambda with a large capture and storing it in a std::function would require a dynamic allocation.
What if we capture that lambda in a new lambda, but capture it by reference, and inside this lambda we call the other lambda?
Our new lambda now has only a single capture, which is by reference, so has a size of 4.
That’s small enough to store in a std::function without needing a dynamic allocation.
Weird huh?
array i;
auto A = [=]() -> int {
return (i[0] + i[1] * i[2] + i[3]) ^ i[4];
}; // sizeof(A) == 20
auto B = [&]() -> int {
return A();
}; // sizeof(B) = 4!
// no allocation needed, B is small enough to use the static storage buffer!
function fB(B);

Notes:
- When using this technique, you can’t return B (or fB) from the function. Once the function exits, those guys are garbage and using them will cause a crash. This is the usual case when capturing locals by reference though, so nothing new there!
- I tried to come up with a helper object / function to do this wrapping for you, to make it easier and more concise to do this. I hit a problem in that in my generic template code, I was able to deduce the return type of the lambda being passed in, but not the argument types. I’m sure it’s possible, but I wasn’t able to get it to work.
Solution 2: Stack Allocation
Due to the fact that you can give a std::function a custom allocator to use, you can solve this problem by having the std::function allocate from the stack (or a small pool allocator if that was more desirable for you!).
Unfortunately we can’t naively use something like alloca() to allocate from the stack, because when a function returns that alloca() is used in, that stack memory is released.
However, you COULD make a custom allocator, give it a buffer for it to give out memory from, and allocate THAT buffer on the stack (or just define it on the stack).
You’ll find the source code to that solution in the sample code below.
One problem with the solution as I made it though, is that you have to manually declare an allocator, define a buffer, pass it to this allocator, then pass that allocator to the std::function.
That is a lot of manual steps which could go wrong.
You could probably clean it up with a helper macro or something, but that still isn’t nearly as clean as the wrapping solution.
Also, the amount of memory that is allocated seems somewhat arbitrarily larger than the size of your type. If you look at the sample code and output of that code, in one case it wants 8 more bytes than the size of the type, and in another, it wants 12 bytes more. Coming up with the right sized buffer can be tricky and problematic which makes this solve a bit uglier.
This is because it isn’t always just your type that needs to be allocated, but is usually your type wrapped in some other type, that adds a little bit of it’s own storage.
A good way to fix this would be to have the allocator store a type “T” object inside of it, and just give out that object when asked for memory, but unfortunately, due to the way allocators are used and converted from allocating one type to another, I was unable to get that working.
Solution 3: std::ref() / std::cref()
There is a third way I’ve found to solve the allocation problem that seems like it’s the official solve that the STL gods would recommend.
Problem is, in my testing it was available in visual studio 2013, but not visual studio 2010. Boo hoo!
std::ref() and std::cref() return reference wrappers (costant ref wrapper in the cref case) which can hold arbitrary types as references. If you put your large capture lambda into one of these functions and give it to std::function, there’s a std::function constructor which is able to take this reference, and use that instead of allocating more memory.
It’s very elegant and simple to do, check it out:
array i;
auto A = [=]() -> int {
return (i[0] + i[1] * i[2] + i[3]) ^ i[4];
};
// no allocation, std::function stores a reference to A instead of A itself
function fA(ref(A));
Again to re-iterate though, this works in vs 2013 but not 2010. If you are stuck in 2010, I recommend manually wrapping your lambdas like in solution 1 ![]()
Sample Code
#include
#include
using namespace std;
#include
// prototype for the function that runs our lambdas
int RunLambda(const function& f);
// ======================================= Allocators =======================================
template
class CAllocator : public allocator
{
public:
template
struct rebind
{
typedef CAllocator other;
};
T* allocate(size_type n, const void *hint = 0)
{
printf("!!CAllocator was asked for %u bytes, dynamically allocating memory.n", n*sizeof(T));
return allocator::allocate(n, hint);
}
void deallocate(pointer p, size_type n)
{
return allocator::deallocate(p, n);
}
CAllocator() throw() : allocator() { }
CAllocator(const CAllocator &a) throw() : allocator(a) { }
template
CAllocator(const CAllocator<U> &a) throw() : allocator(a) { }
~CAllocator() throw() { }
};
template
class CStackAllocator : public allocator
{
public:
template
struct rebind
{
typedef CStackAllocator other;
};
T* allocate(size_type n, const void *hint = 0)
{
int a = sizeof(T);
printf(" CStackAllocator was asked for %u bytes, returning buffer given.n", n*sizeof(T));
return (T*)m_buffer;
}
void deallocate(pointer p, size_type n)
{
}
CStackAllocator() throw() : allocator(), m_buffer(nullptr), m_bufferSize(0) { }
CStackAllocator(const CStackAllocator &a) throw() : allocator(a), m_buffer(a.m_buffer), m_bufferSize(a.m_bufferSize) { }
template
CStackAllocator(const CStackAllocator<U> &a) throw() : allocator(a), m_buffer(a.m_buffer), m_bufferSize(a.m_bufferSize) { }
~CStackAllocator() throw() { }
void SetBuffer(void *buffer, size_t bufferSize)
{
m_buffer = buffer;
m_bufferSize = bufferSize;
}
void *m_buffer;
size_t m_bufferSize;
// It would be neat to be able to do the below instead, but it complains about trying to use an undefined type unfortunately.
// It would be less error prone and require fewer manual steps by the caller.
// unsigned char m_buffer[sizeof(T)];
};
// ======================================= Lambda Tests =======================================
void LambdaTest_Normal()
{
printf("=====LambdaTest_Normal()=====n");
printf("Large Capture Lambda A:n");
array i;
i[0] = 2;
i[1] = 57;
i[2] = i[0] ^ i[1];
i[3] = i[1] ^ i[2];
i[4] = i[3] ^ i[2] + i[0] ^ i[1];
auto A = [=]() -> int {
return (i[0] + i[1] * i[2] + i[3]) ^ i[4];
};
printf(" sizeof(A) = %un", sizeof(A));
printf(" creating allocatorAn");
CAllocator allocatorA;
printf(" storing A in fAn");
function fA(A, allocatorA);
printf(" RunLambda(fA)= %un", RunLambda(fA));
printf("n");
// Allocation, no good for perf intensive code!
// Also a virtual function call, but unavoidable when using std::functions
}
void LambdaTest_Wrap()
{
printf("=====LambdaTest_Wrap()=====n");
printf("Lambda B which captures A by reference:n");
array i;
i[0] = 2;
i[1] = 57;
i[2] = i[0] ^ i[1];
i[3] = i[1] ^ i[2];
i[4] = i[3] ^ i[2] + i[0] ^ i[1];
auto A = [=]() -> int {
return (i[0] + i[1] * i[2] + i[3]) ^ i[4];
};
auto B = [&]() -> int {
return A();
};
printf(" sizeof(B) = %un", sizeof(B));
printf(" creating allocatorBn");
CAllocator allocatorB;
printf(" storing B in fBn");
function fB(B, allocatorB);
printf(" RunLambda(fB)= %un", RunLambda(fB));
printf("n");
// Could alternately do this to create fB more concisely while still avoiding allocation
// function fB([&A]()->int {return A();});
// It would be nice to make some kind of helper object / function to wrap
// lambdas instead of having to wrap them twice yourself. Couldn't figure out
// a way to do that unfortunately. decltype(A()) gives you the return type,
// but figuring out the parameter type(s) is more difficult.
}
void LambdaTest_StackAlloc()
{
printf("=====LambdaTest_StackAlloc()=====n");
printf("Large Capture Lambda A:n");
array i;
i[0] = 2;
i[1] = 57;
i[2] = i[0] ^ i[1];
i[3] = i[1] ^ i[2];
i[4] = i[3] ^ i[2] + i[0] ^ i[1];
auto A = [=]() -> int {
return (i[0] + i[1] * i[2] + i[3]) ^ i[4];
};
printf(" sizeof(A) = %un", sizeof(A));
printf(" creating stack allocatorAn");
CStackAllocator allocatorA;
unsigned char buffer[sizeof(A) + 12];
printf(" Giving stack allocator %u byte buffern", sizeof(buffer));
allocatorA.SetBuffer(buffer, sizeof(buffer));
printf(" storing A in fAn");
function fA(A, allocatorA);
printf(" RunLambda(fA)= %un", RunLambda(fA));
printf("n");
// It would have been nice for the allocator to hold it's own storage, since it
// has to live on the stack anyways, and has knowledge of the type it's allocating
// for (so knows the type size). Hit some issues trying that though unfortunately.
}
void LambdaTest_Ref()
{
printf("=====LambdaTest_Ref()=====n");
printf("Large Capture Lambda A:n");
array i;
i[0] = 2;
i[1] = 57;
i[2] = i[0] ^ i[1];
i[3] = i[1] ^ i[2];
i[4] = i[3] ^ i[2] + i[0] ^ i[1];
auto A = [=]() -> int {
return (i[0] + i[1] * i[2] + i[3]) ^ i[4];
};
printf(" sizeof(A) = %un", sizeof(A));
printf(" creating allocatorAn");
CAllocator allocatorA;
printf(" storing ref(A) in fAn");
function fA(ref(A), allocatorA);
printf(" RunLambda(fA)= %un", RunLambda(fA));
printf("n");
// Nice and simple, this seems to be the correct solution, so long as you have access to
// std::ref / std::cref!
// vs2010 has it, but it seems to be partially implemented, as the above doesn't work.
// vs2013 has it and it works wonderfully though.
}
// ======================================= Driver Program =======================================
void WaitForEnter()
{
printf("Press Enter to quit");
fflush(stdin);
(void)getchar();
}
int main(int argc, char **argv)
{
LambdaTest_Normal();
LambdaTest_Wrap();
LambdaTest_StackAlloc();
LambdaTest_Ref();
WaitForEnter();
return 0;
}
// Pretend like this function is in another cpp file, where it can't be a templated function
int RunLambda(const function& f)
{
return f() * 3;
}
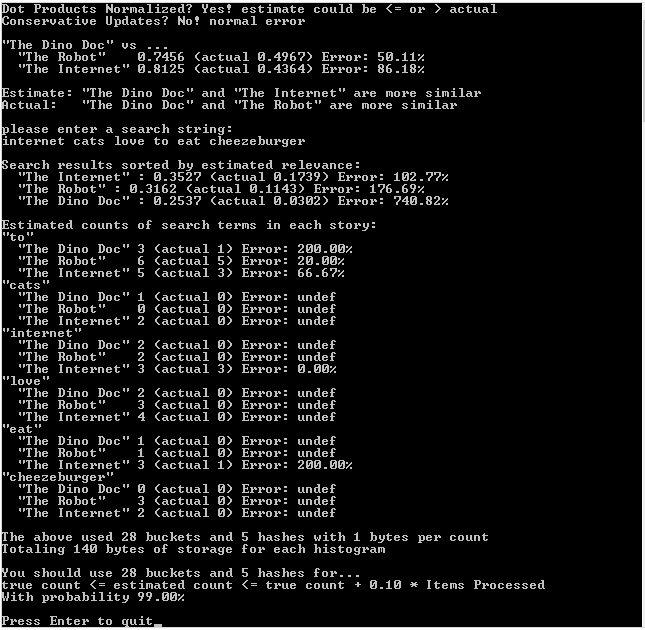
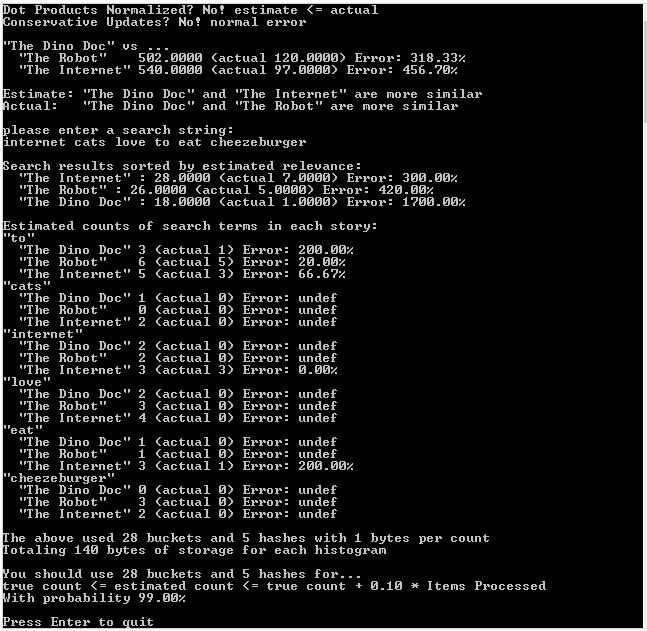
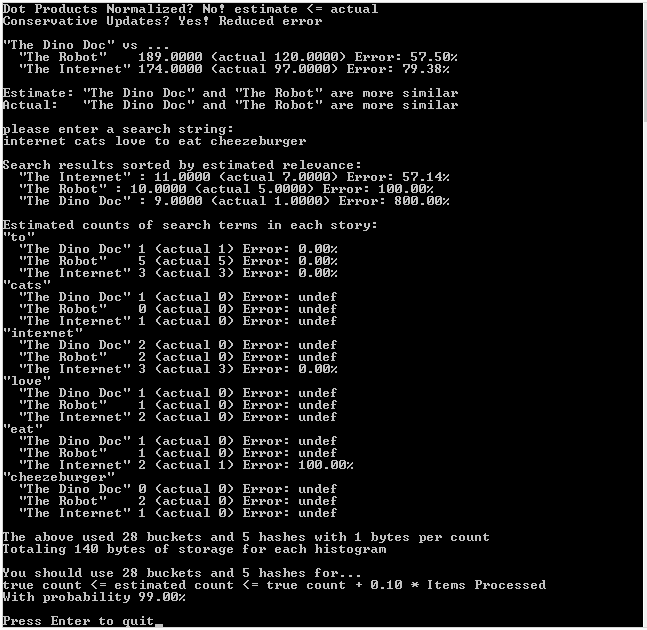
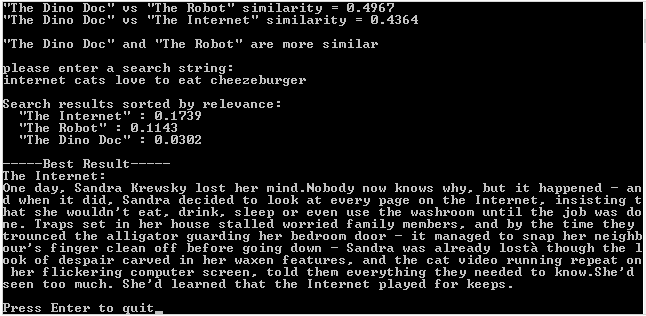
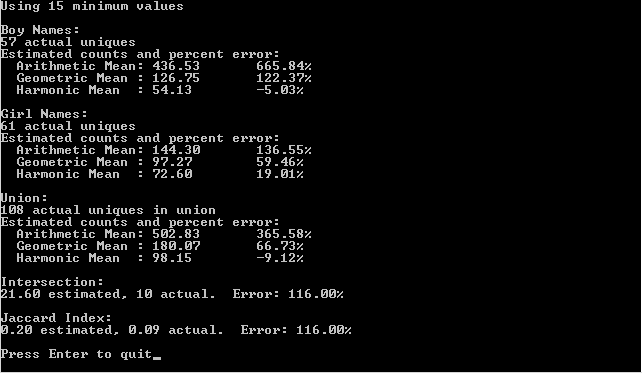
And here is the example output of that run in visual studio 2013. Same output in debug and release:

Links
A similar article:
DDJ: Efficient Use of Lambda Expressions and std::function
Two good reads about type erasure:
cplusplus.com: C++ Type Erasure
Andrzej’s C++ blog: Type erasure — Part I
If you have any improvements to any of the above solutions, or other solutions of your own, post a comment and let us know!