
The last post showed how to fit a 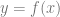
This post generalizes that process to equations of any dimension such as 

Below is an image of a surface that is degree (2,2). This is a screenshot taken from the interactive webgl2 demo I made for this post: Least Squares Surface Fitting

How Do You Do It?
The two main players from the last post were the ATA matrix and the ATY vector. These two could be incrementally updated as new data points came in, which would allow you to do an incremental (or “online”) least squares fit of a curve.
When working with surfaces and volumes, you have the same things basically. Both the ATA matrix and the ATY vector still exist, but they contain slightly different information – which I’ll explain lower down. However, the ATY vector is renamed, since in the case of a surface it should be called ATZ, and for a volume it should be called ATW. I call it ATV to generalize it, where v stands for value, and represents the last component in a data point, which is the output value we are trying to fit given the input values. The input values are the rest of the components of the data point.
At the end, you once again need to solve the equation 
It’s all pretty similar to fitting a curve, but the details change a bit. Let’s work through an example to see how it differs.
Example: Bilinear Surface Fitting
Let’s fit 4 data points to a bilinear surface, otherwise known as a surface that is linear on each axis, or a surface of degree(1,1):
(0,0,5)
(0,1,3)
(1,0,8)
(1,1,2)
Since we are fitting those data points with a bilinear surface, we are looking for a function that takes in x,y values and gives as output the z coordinate. We want a surface that gives us the closest answer possible (minimizing the sum of the squared difference for each input data point) for the data points we do have, so that we can give it other data points and get z values as output that approximate what we expect to see for that input.
A linear equation looks like this, with coefficients A and B:

Since we want a bilinear equation this time around, this is the equation we are going to end up with, after solving for the coefficients A,B,C,D:
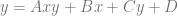
The first step is to make the A matrix. In the last post, this matrix was made up of powers of the x coordinates. In this post, they are actually going to be made up of the permutation of powers of the x and y coordinates.
Last time the matrix looked like this:

This time, the matrix is going to look like this:

Simplifying that matrix a bit, it looks like this:

To simplify it even further, there is one row in the A matrix per data point, where the row looks like this:

You can see that every permutation of the powers of x and y for each data point is present in the matrix.
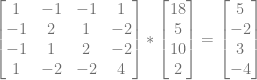
The A matrix for our data points is this:

Next we need to calculate the ATA matrix by multiplying the transpose of that matrix, by that matrix.

Taking the inverse of that matrix we get this:

Next we need to calculate the ATV vector (formerly known as ATY). We calculate that by multiplying the transpose of the A matrix by the Z values:

Lastly we multiply the inversed ATA matrix by the ATV vector to get our coefficients.
In the last post, the coefficients we got out were in x power order, so the first (top) was for the 
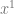
This time around, the coefficients are in the same order as the permutations of the powers of x and y:
That makes our final equation this:

If you plug in the (x,y) values from the data set we fit, you’ll see that you get the corresponding z values as output. We perfectly fit the data set!
The process isn’t too different from last post and not too difficult either right?
Let’s see if we can generalize and formalize things a bit.
Some Observations
Firstly you may be wondering how we come up with the correct permutation of powers of our inputs. It actually doesn’t matter so long as you are consistent. You can have your A matrix rows have the powers in any order, so long as all orders are present, and you use the same order in all operations.
Regarding storage sizes needed, the storage of surfaces and (hyper) volumes are a bit different and generally larger than curves.
To see how, let’s look at the powers of the ATA matrix of a bilinear surface, using the ordering of powers that we used in the example:

Let’s rewrite it as just the powers:

And the permutation we used as just powers to help us find the pattern in the powers of x and y in the ATA matrix:

Can you find the pattern of the powers used at the different spots in the ATA matrix?
I had to stare at it for a while before I figured it out but it’s this: For the i,j location in the ATA matrix, the powers of x and y are the powers of x and y in the i permutation added to the powers of x and y in the j permutation.
For example, 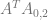
Another example, 
That’s a bit more complex than last post, not too much more difficult to construct the ATA matrix directly – and also construct it incrementally as new data points come in!
How many unique values are there in the ATA matrix though? We need to know this to know how much storage we need.
In the last post, we needed (degree+1)*2–1 values to store the unique ATA matrix values. That can also be written as degree*2+1.
It turns out that when generalizing this to surfaces and volumes, that we need to take the product of that for each axis.
For instance, a surface has ((degreeX*2)+1)*((degreeY*2)+1) unique values. A volume has ((degreeX*2)+1)*((degreeY*2)+1)*((degreeZ*2)+1) unique values.
The pattern continues for higher dimensions, as well as lower, since you can see how in the curve case, it’s the same formula as it was before.
For the same ATA matrix size, a surface has more unique values than a curve does.
As far as what those values actually are, they are the full permutations of the powers of a surface (or hyper volume) that is one degree higher on each axis. For a bilinear surface, that means the 9 permutations of x and y for powers 0,1 and 2:
Or simplified:


What about the ATV vector?
For the bilinear case, The ATV vector is the sums of the permutations of x,y multiplied by z, for every data point. In other words, you add this to ATV for each data point:

How much storage space do we need in general for the ATV vector then? it’s the product of (degree+1) for each axis.
For instance, a surface has (degreeX+1)*(degreeY+1) values in ATV, and a volume has (degreeX+1)*(degreeY+1)*(degreeZ+1).
You may also be wondering how many data points are required minimum to fit a curve, surface or hypervolume to a data set. The answer is that you need as many data points as there are terms in the polynomial. We are trying to solve for the polynomial coefficients, so there are as many unknowns as there are polynomial terms.
How many polynomial terms are there? There are as many terms as there are permutations of the axes powers involved. In other words, the size of ATV is also the minimum number of points you need to fit a curve, surface, or hypervolume to a data set.
Measuring Quality of a Fit
You are probably wondering if there’s a way to calculate how good of a fit you have for a given data set. It turns out that there are a few ways to calculate a value for this.
The value I use in the code below and in the demos is called 
First you calculate the average (mean) output value from the input data set.
Then you calculate SSTot which is the sum of the square of the mean subtracted from each input point’s output value. Pseudo code:
SSTot = 0; for (point p in points) SSTot += (p.out - mean)^2;
You then calculate SSRes which is the sum of the square of the fitted function evaluated at a point, subtracted from each input points’ output value. Pseudo code:
SSRes= 0; for (point p in points) SSRes += (p.out - f(p.in))^2;
The final value for R^2 is 1-SSRes/SSTot.
The value is nice because it’s unitless, and since SSRes and SSTot is a sum of squares, SSRes/SSTot is basically the value that the fitting algorithm minimizes. The value is subtracted from 1 so that it’s a fit quality metric. A value of 0 is a bad fit, and a value of 1 is a good fit and generally it will be between those values.
If you want to read more about this, check out this link: Coefficient of Determination
Example Code
Here is a run from the sample code:

And here is the source code:
#include <stdio.h>
#include <array>
#define FILTER_ZERO_COEFFICIENTS true // if false, will show terms which have a coefficient of 0
//====================================================================
template<size_t N>
using TVector = std::array<float, N>;
template<size_t M, size_t N>
using TMatrix = std::array<TVector<N>, M>;
//====================================================================
// Specify a degree per axis.
// 1 = linear, 2 = quadratic, etc
template <size_t... DEGREES>
class COnlineLeastSquaresFitter
{
public:
COnlineLeastSquaresFitter ()
{
// initialize our sums to zero
std::fill(m_SummedPowers.begin(), m_SummedPowers.end(), 0.0f);
std::fill(m_SummedPowersTimesValues.begin(), m_SummedPowersTimesValues.end(), 0.0f);
}
// Calculate how many summed powers we need.
// Product of degree*2+1 for each axis.
template <class T>
constexpr static size_t NumSummedPowers(T degree)
{
return degree * 2 + 1;
}
template <class T, class... DEGREES>
constexpr static size_t NumSummedPowers(T first, DEGREES... degrees)
{
return NumSummedPowers(first) * NumSummedPowers(degrees...);
}
// Calculate how many coefficients we have for our equation.
// Product of degree+1 for each axis.
template <class T>
constexpr static size_t NumCoefficients(T degree)
{
return (degree + 1);
}
template <class T, class... DEGREES>
constexpr static size_t NumCoefficients(T first, DEGREES... degrees)
{
return NumCoefficients(first) * NumCoefficients(degrees...);
}
// Helper function to get degree of specific axis
static size_t Degree (size_t axisIndex)
{
static const std::array<size_t, c_dimension-1> c_degrees = { DEGREES... };
return c_degrees[axisIndex];
}
// static const values
static const size_t c_dimension = sizeof...(DEGREES) + 1;
static const size_t c_numCoefficients = NumCoefficients(DEGREES...);
static const size_t c_numSummedPowers = NumSummedPowers(DEGREES...);
// Typedefs
typedef TVector<c_numCoefficients> TCoefficients;
typedef TVector<c_dimension> TDataPoint;
// Function for converting from an index to a specific power permutation
static void IndexToPowers (size_t index, std::array<size_t, c_dimension-1>& powers, size_t maxDegreeMultiply, size_t maxDegreeAdd)
{
for (int i = c_dimension-2; i >= 0; --i)
{
size_t degree = Degree(i) * maxDegreeMultiply + maxDegreeAdd;
powers[i] = index % degree;
index = index / degree;
}
}
// Function for converting from a specific power permuation back into an index
static size_t PowersToIndex (std::array<size_t, c_dimension - 1>& powers, size_t maxDegreeMultiply, size_t maxDegreeAdd)
{
size_t ret = 0;
for (int i = 0; i < c_dimension - 1; ++i)
{
ret *= Degree(i) * maxDegreeMultiply + maxDegreeAdd;
ret += powers[i];
}
return ret;
}
// Add a datapoint to our fitting
void AddDataPoint (const TDataPoint& dataPoint)
{
// Note: It'd be a good idea to memoize the powers and calculate them through repeated
// multiplication, instead of calculating them on demand each time, using std::pow.
// add the summed powers of the input values
std::array<size_t, c_dimension-1> powers;
for (size_t i = 0; i < m_SummedPowers.size(); ++i)
{
IndexToPowers(i, powers, 2, 1);
float valueAdd = 1.0;
for (size_t j = 0; j < c_dimension - 1; ++j)
valueAdd *= (float)std::pow(dataPoint[j], powers[j]);
m_SummedPowers[i] += valueAdd;
}
// add the summed powers of the input value, multiplied by the output value
for (size_t i = 0; i < m_SummedPowersTimesValues.size(); ++i)
{
IndexToPowers(i, powers, 1, 1);
float valueAdd = dataPoint[c_dimension - 1];
for (size_t j = 0; j < c_dimension-1; ++j)
valueAdd *= (float)std::pow(dataPoint[j], powers[j]);
m_SummedPowersTimesValues[i] += valueAdd;
}
}
// Get the coefficients of the equation fit to the points
bool CalculateCoefficients (TCoefficients& coefficients) const
{
// make the ATA matrix
std::array<size_t, c_dimension - 1> powersi;
std::array<size_t, c_dimension - 1> powersj;
std::array<size_t, c_dimension - 1> summedPowers;
TMatrix<c_numCoefficients, c_numCoefficients> ATA;
for (size_t j = 0; j < c_numCoefficients; ++j)
{
IndexToPowers(j, powersj, 1, 1);
for (size_t i = 0; i < c_numCoefficients; ++i)
{
IndexToPowers(i, powersi, 1, 1);
for (size_t k = 0; k < c_dimension - 1; ++k)
summedPowers[k] = powersi[k] + powersj[k];
size_t summedPowersIndex = PowersToIndex(summedPowers, 2, 1);
ATA[j][i] = m_SummedPowers[summedPowersIndex];
}
}
// solve: ATA * coefficients = m_SummedPowers
// for the coefficients vector, using Gaussian elimination.
coefficients = m_SummedPowersTimesValues;
for (size_t i = 0; i < c_numCoefficients; ++i)
{
for (size_t j = 0; j < c_numCoefficients; ++j)
{
if (ATA[i][i] == 0.0f)
return false;
float c = ((i == j) - ATA[j][i]) / ATA[i][i];
coefficients[j] += c*coefficients[i];
for (size_t k = 0; k < c_numCoefficients; ++k)
ATA[j][k] += c*ATA[i][k];
}
}
// Note: this is the old, "bad" way to solve the equation using matrix inversion.
// It's a worse choice for larger matrices, and surfaces and volumes use larger matrices than curves in general.
/*
// Inverse the ATA matrix
TMatrix<c_numCoefficients, c_numCoefficients> ATAInverse;
if (!InvertMatrix(ATA, ATAInverse))
return false;
// calculate the coefficients
for (size_t i = 0; i < c_numCoefficients; ++i)
coefficients[i] = DotProduct(ATAInverse[i], m_SummedPowersTimesValues);
*/
return true;
}
private:
//Storage Requirements:
// Summed Powers = Product of degree*2+1 for each axis.
// Summed Powers Times Values = Product of degree+1 for each axis.
TVector<c_numSummedPowers> m_SummedPowers;
TVector<c_numCoefficients> m_SummedPowersTimesValues;
};
//====================================================================
char AxisIndexToLetter (size_t axisIndex)
{
// x,y,z,w,v,u,t,....
if (axisIndex < 3)
return 'x' + char(axisIndex);
else
return 'x' + 2 - char(axisIndex);
}
//====================================================================
template <class T, size_t M, size_t N>
float EvaluateFunction (const T& fitter, const TVector<M>& dataPoint, const TVector<N>& coefficients)
{
float ret = 0.0f;
for (size_t i = 0; i < coefficients.size(); ++i)
{
// start with the coefficient
float term = coefficients[i];
// then the powers of the input variables
std::array<size_t, T::c_dimension - 1> powers;
fitter.IndexToPowers(i, powers, 1, 1);
for (size_t j = 0; j < powers.size(); ++j)
term *= (float)std::pow(dataPoint[j], powers[j]);
// add this term to our return value
ret += term;
}
return ret;
}
//====================================================================
template <size_t... DEGREES>
void DoTest (const std::initializer_list<TVector<sizeof...(DEGREES)+1>>& data)
{
// say what we are are going to do
printf("Fitting a function of degree (");
for (size_t i = 0; i < COnlineLeastSquaresFitter<DEGREES...>::c_dimension - 1; ++i)
{
if (i > 0)
printf(",");
printf("%zi", COnlineLeastSquaresFitter<DEGREES...>::Degree(i));
}
printf(") to %zi data points: n", data.size());
// show input data points
for (const COnlineLeastSquaresFitter<DEGREES...>::TDataPoint& dataPoint : data)
{
printf(" (");
for (size_t i = 0; i < dataPoint.size(); ++i)
{
if (i > 0)
printf(", ");
printf("%0.2f", dataPoint[i]);
}
printf(")n");
}
// fit data
COnlineLeastSquaresFitter<DEGREES...> fitter;
for (const COnlineLeastSquaresFitter<DEGREES...>::TDataPoint& dataPoint : data)
fitter.AddDataPoint(dataPoint);
// calculate coefficients if we can
COnlineLeastSquaresFitter<DEGREES...>::TCoefficients coefficients;
bool success = fitter.CalculateCoefficients(coefficients);
if (!success)
{
printf("Could not calculate coefficients!nn");
return;
}
// print the polynomial
bool firstTerm = true;
printf("%c = ", AxisIndexToLetter(sizeof...(DEGREES)));
bool showedATerm = false;
for (int i = (int)coefficients.size() - 1; i >= 0; --i)
{
// don't show zero terms
if (FILTER_ZERO_COEFFICIENTS && std::abs(coefficients[i]) < 0.00001f)
continue;
showedATerm = true;
// show an add or subtract between terms
float coefficient = coefficients[i];
if (firstTerm)
firstTerm = false;
else if (coefficient >= 0.0f)
printf(" + ");
else
{
coefficient *= -1.0f;
printf(" - ");
}
printf("%0.2f", coefficient);
std::array<size_t, COnlineLeastSquaresFitter<DEGREES...>::c_dimension - 1> powers;
fitter.IndexToPowers(i, powers, 1, 1);
for (size_t j = 0; j < powers.size(); ++j)
{
if (powers[j] > 0)
printf("%c", AxisIndexToLetter(j));
if (powers[j] > 1)
printf("^%zi", powers[j]);
}
}
if (!showedATerm)
printf("0");
printf("n");
// Calculate and show R^2 value.
float rSquared = 1.0f;
if (data.size() > 0)
{
float mean = 0.0f;
for (const COnlineLeastSquaresFitter<DEGREES...>::TDataPoint& dataPoint : data)
mean += dataPoint[sizeof...(DEGREES)];
mean /= data.size();
float SSTot = 0.0f;
float SSRes = 0.0f;
for (const COnlineLeastSquaresFitter<DEGREES...>::TDataPoint& dataPoint : data)
{
float value = dataPoint[sizeof...(DEGREES)] - mean;
SSTot += value*value;
value = dataPoint[sizeof...(DEGREES)] - EvaluateFunction(fitter, dataPoint, coefficients);
SSRes += value*value;
}
if (SSTot != 0.0f)
rSquared = 1.0f - SSRes / SSTot;
}
printf("R^2 = %0.4fnn", rSquared);
}
//====================================================================
int main (int argc, char **argv)
{
// bilinear - 4 data points
DoTest<1, 1>(
{
TVector<3>{ 0.0f, 0.0f, 5.0f },
TVector<3>{ 0.0f, 1.0f, 3.0f },
TVector<3>{ 1.0f, 0.0f, 8.0f },
TVector<3>{ 1.0f, 1.0f, 2.0f },
}
);
// biquadratic - 9 data points
DoTest<2, 2>(
{
TVector<3>{ 0.0f, 0.0f, 8.0f },
TVector<3>{ 0.0f, 1.0f, 4.0f },
TVector<3>{ 0.0f, 2.0f, 6.0f },
TVector<3>{ 1.0f, 0.0f, 5.0f },
TVector<3>{ 1.0f, 1.0f, 2.0f },
TVector<3>{ 1.0f, 2.0f, 1.0f },
TVector<3>{ 2.0f, 0.0f, 7.0f },
TVector<3>{ 2.0f, 1.0f, 9.0f },
TVector<3>{ 2.0f, 2.5f, 12.0f },
}
);
// trilinear - 8 data points
DoTest<1, 1, 1>(
{
TVector<4>{ 0.0f, 0.0f, 0.0f, 8.0f },
TVector<4>{ 0.0f, 0.0f, 1.0f, 4.0f },
TVector<4>{ 0.0f, 1.0f, 0.0f, 6.0f },
TVector<4>{ 0.0f, 1.0f, 1.0f, 5.0f },
TVector<4>{ 1.0f, 0.0f, 0.0f, 2.0f },
TVector<4>{ 1.0f, 0.0f, 1.0f, 1.0f },
TVector<4>{ 1.0f, 1.0f, 0.0f, 7.0f },
TVector<4>{ 1.0f, 1.0f, 1.0f, 9.0f },
}
);
// trilinear - 9 data points
DoTest<1, 1, 1>(
{
TVector<4>{ 0.0f, 0.0f, 0.0f, 8.0f },
TVector<4>{ 0.0f, 0.0f, 1.0f, 4.0f },
TVector<4>{ 0.0f, 1.0f, 0.0f, 6.0f },
TVector<4>{ 0.0f, 1.0f, 1.0f, 5.0f },
TVector<4>{ 1.0f, 0.0f, 0.0f, 2.0f },
TVector<4>{ 1.0f, 0.0f, 1.0f, 1.0f },
TVector<4>{ 1.0f, 1.0f, 0.0f, 7.0f },
TVector<4>{ 1.0f, 1.0f, 1.0f, 9.0f },
TVector<4>{ 0.5f, 0.5f, 0.5f, 12.0f },
}
);
// Linear - 2 data points
DoTest<1>(
{
TVector<2>{ 1.0f, 2.0f },
TVector<2>{ 2.0f, 4.0f },
}
);
// Quadratic - 4 data points
DoTest<2>(
{
TVector<2>{ 1.0f, 5.0f },
TVector<2>{ 2.0f, 16.0f },
TVector<2>{ 3.0f, 31.0f },
TVector<2>{ 4.0f, 16.0f },
}
);
// Cubic - 4 data points
DoTest<3>(
{
TVector<2>{ 1.0f, 5.0f },
TVector<2>{ 2.0f, 16.0f },
TVector<2>{ 3.0f, 31.0f },
TVector<2>{ 4.0f, 16.0f },
}
);
system("pause");
return 0;
}
Closing
The next logical step here for me would be to figure out how to break the equation for a surface or hypervolume up into multiple equations, like you’d have with a tensor product surface/hypervolume equation. It would also be interesting to see how to convert from these multidimensional polynomials to multidimensional Bernstein basis functions, which are otherwise known as Bezier rectangles (and Bezier hypercubes i guess).
The last post inverted the ATA matrix and multiplied by ATY to get the coefficients. Thanks to some feedback on reddit, I found out that is NOT how you want to solve this sort of equation. I ended up going with Gaussian elimination for this post which is more numerically robust while also being less computation to calculate. There are other options out there too that may be even better choices. I’ve found out that in general, if you are inverting a matrix in code, or even just using an inverted matrix that has already been given to you, you are probably doing it wrong. You can read more about that here: John D. Cook: Don’t invert that matrix.
I didn’t go over what to do if you don’t have enough data points because if you find yourself in that situation, you can either decrease the degree of one of the axes, or you could remove and axis completely if you wanted to. It’s situational and ambiguous what parameter to decrease when you don’t have enough data points to fit a specific curve or hypervolume, but it’s still possible to decay the fit to a lower degree or dimension if you hit this situation, because you will already have all the values you need in the ATA matrix values and the ATV vector. I leave that to you to decide how to handle it in your own usage cases. Something interesting to note is that ATA[0][0] is STILL the count of how many data points you have, so you can use this value to know how much you need to decay your fit to be able to handle the data set.
In the WebGL2 demo I mention, I use a finite difference method to calculate the normals of the surface, however since the surface is described by a polynomial, it’d be trivial to calculate the coefficients for the equations that described the partial derivatives of the surface for each axis and use those instead.
I also wanted to mention that in the case of surfaces and hypervolumes it’s still possible to get an imperfect fit to your data set, even though you may give the exact minimum required number of control points. The reason for this is that not all axes are necesarily created equal. If you have a surface of degree (1,2) it’s linear on the x axis, but quadratic on the y axis, and requires a minimum of 6 data points to be able to fit a data set. As you can imagine, it’s possible to give data points such that the data points ARE NOT LINEAR on the x axis. When this happens, the surface will not be a perfect fit.
Lastly, you may be wondering how to fit data sets where there is more than one output value, like an equation of the form 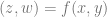
I’m not aware of any ways to least square fit that as a whole, but apparently a common practice is to fit one equation to z and another to w and treat them independently. There is a math stack exchange question about that here: Math Stack Exchange: Least square fitting multiple values
Here is the webgl demo that goes with this post again:
Least Squares Surface Fitting
Thanks for reading, and please speak up if you have anything to add or correct, or a comment to make!
