
The code that made the data and diagrams for this post is plain C++ and can be found at https://github.com/Atrix256/Adam
I recently published a set 3 of articles on machine learning in plain C++ for game developers, as well as a video version of the same content. This article explains an improvement to plain gradient descent called Adam and can be read as a follow up to those articles.
Part 1: https://www.ea.com/seed/news/machine-learning-game-devs-part-1
Part 2: https://www.ea.com/seed/news/machine-learning-game-devs-part-2
Part 3: https://www.ea.com/seed/news/machine-learning-game-devs-part-3
45 minute video: https://www.youtube.com/watch?v=sTAqWRsEiy0
Adam Motivation
Let’s say we wanted to find the values of the x parameters in the function below that gives the lowest y value:
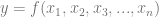
This is an optimization problem and functions of this form are called cost functions. Gradient descent is a method for doing this optimization, where you start with a random set of x values, and “roll down hill” by making small adjustments to those x values that lead to lower y values. You can stop either after a specific number of steps, or when the y value is below some threshold.
The gradient of a function is a vector of the partial derivatives of the x parameters, and the vector as a whole points the steepest direction up hill on the surface of the function. If you want to go the steepest direction down hill, you just go in the opposite direction.
A challenge is that the steepest path down hill is most often a curved path, not a straight line. To deal with this, you can take small steps down hill and re-evaluate the gradient at each step to figure out the direction to step in next. In machine learning, this step size is called the learning rate and is often called α (“alpha”) and is tuned by hand.
Smaller steps give you a more accurate result, but may be computationally wasteful, taking many small steps when you could take fewer, larger steps towards the goal. This makes for longer than necessary computation (or training) times.
Larger steps might be able to get you nearer to the goal faster, but if the minimum value of the function lies in a deep, narrow canyon, large steps won’t be able to get you into the deepest part of the function.
Having to adjust this learning rate by hand, and having the appropriate learning rate change as you do gradient descent is one of the two problems Adam addresses, by turning down the learning rate when the terrain gets more complicated / bumpy.
Another challenge with gradient descent is that it’s possible to get stuck in a shallow valley when there is a much deeper canyon waiting to be found. This is called a local minima, because while it’s the deepest point locally, it isn’t the globally deepest part of the function, or the global minimum.
A common way of dealing with this is to add momentum to our imaginary ball rolling down hill, so that it can escape local minima and hopefully find deeper, more global minima. If not, it should just roll back into the minima it did find. Momentum is the second benefit Adam gives over plain gradient descent.
Adam is a popular, and simple, method of improving gradient descent and is heavily used in machine learning, which uses gradient descent to train neural networks.
Adam
Adam has 4 parameters, but only alpha usually needs to be tuned.
- Alpha – This is essentially the learning rate.
- Beta1 – The rate of exponential moving average of the derivative (First Moment). Default is 0.9.
- Beta2 – The same for the derivative squared (Second Moment). Default is 0.999.
- Epsilon – a value to prevent division by zero. Default is 1e-8.
Adam works by keeping an exponential moving average of the derivative (the first moment of the derivative), as well as a moving average of the derivative squared (the second moment of the derivative), each with their own smoothing factor. In this way, this gives Adam an imperfect memory of the derivatives it has seen, tending to forget older derivative values, and weight newer derivative values more highly. The squared derivative moving average is also more sensitive to large outliers.
The code for doing this is straight forward:
static const float c_beta1 = 0.9f;
static const float c_beta2 = 0.999f;
m = c_beta1 * m + (1.0f - c_beta1) * derivative;
v = c_beta2 * v + (1.0f - c_beta2) * derivative * derivative;
Interestingly, the m calculation is the same as doing a lerp from m to derivative with a t value of 0.1. If you work in real time rendering, that should look familiar, as that is how TAA (Temporal Anti Aliasing) works as well, also often using a value of 0.1. v works similarly, but uses a t value in the lerp of 0.001.
So, m and v are a moving average of recent derivative and derivative squared values respectively.
The learning rate alpha is then multiplied by m and divided by the square root of v, to calculate an adjusted derivative to use for gradient descent.
float adjustedDerivative = alpha * m / sqrt(v);
if the derivative was a constant, m would be that constant value, and so would sqrt(v), which means alpha would be the amount to adjust the parameter by. if m was bigger than sqrt(v), it would increase the learning rate, else if m is smaller than sqrt(v), it would decrease the learning rate. Through this simple operation, Adam gives both momentum to escape local minima, as well as the ability to slow down when there are more details to explore on the surface of a function.
We aren’t quite done though. If you work in graphics, you likely have noticed that when using TAA, the first several frames rendered are darker than they should be, before enough frames have been processed. This same problem occurs in Adam, meaning that when it’s first starting out, both m and v are biased towards zero. Adam does bias correction to account for this, essentially making the numbers larger (or for TAA, it’d make the pixels brighter). It calculates an “m hat” and a “v hat”, and that is what is used to calculate the learning rate instead of the raw m and v. Since v hat could possibly be zero, we have to account for that in the division.
static const float c_epsilon = 1e-8f;
float mhat = m / (1.0f - std::pow(c_beta1, sampleCount));
float vhat = v / (1.0f - std::pow(c_beta2, sampleCount));
float adjustedDerivative = alpha * mhat / (sqrt(vhat)+c_epsilon);
Putting it all together, here is a small struct you can use to put a derivative through Adam to get an adjusted derivative. You would have one of these per parameter to your function, so that Adam was able to adjust the learning rate of each parameter individually.
// Note: alpha needs to be tuned, but beta1, beta2, epsilon as usually fine as is
struct Adam
{
// Internal state
float m = 0.0f;
float v = 0.0f;
// Internal state calculated for convenience
// If you have a bunch of derivatives, you would probably want to store / calculate these once
// for the entire gradient, instead of each derivative like this is doing.
float beta1Decayed = 1.0f;
float beta2Decayed = 1.0f;
float GetAdjustedDerivative(float derivative, float alpha)
{
// Adam parameters
static const float c_beta1 = 0.9f;
static const float c_beta2 = 0.999f;
static const float c_epsilon = 1e-8f;
// exponential moving average of first and second moment
m = c_beta1 * m + (1.0f - c_beta1) * derivative;
v = c_beta2 * v + (1.0f - c_beta2) * derivative * derivative;
// bias correction
beta1Decayed *= c_beta1;
beta2Decayed *= c_beta2;
float mhat = m / (1.0f - beta1Decayed);
float vhat = v / (1.0f - beta2Decayed);
// Adam adjusted derivative
return alpha * mhat / (std::sqrt(vhat) + c_epsilon);
}
};
An interesting aspect of Adam is that you can see that it adjusts the step size (alpha) by saying “be bigger” or “be smaller” but it never gives a specific value that is an optimal step size, and you still have to tune the learning rate value by hand. To me, that looks like something we’ll likely have a better answer to in the future.
I also find it interesting that adam calculates an adjusted learning rate (alpha) and doesn’t multiply the derivative by that, but just uses that for the derivative instead. That makes it so while the length of a function’s gradient may change from location to location, this actual step size is more fixed, and is just affected by how the gradient changes over time.
Another thing people do with gradient descent is start with a larger learning rate, and decrease it over time. This helps the gradient descent move quickly in the beginning to get closer to the global minimum, and then as it slows down, it helps it refine the search. Interestingly, some people do this ALONG SIDE of Adam, which to me makes some sense. Since Adam can only slow down or speed up a learning rate, but not set it to a specific value, it seems like it could be a good idea to decrease the learning rate over time as well. But, then you have another hyper parameter to tune – how much should alpha decrease each iteration?
Results
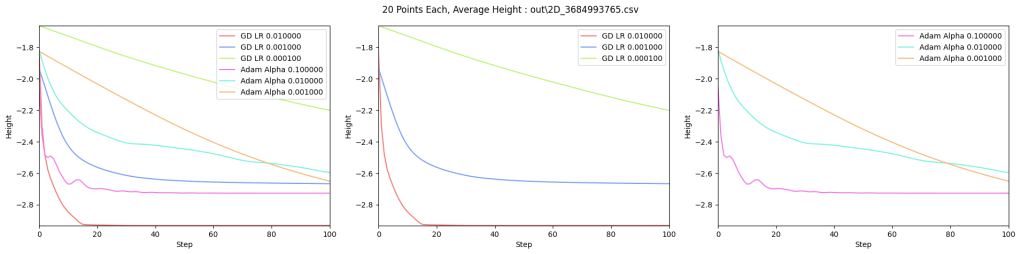
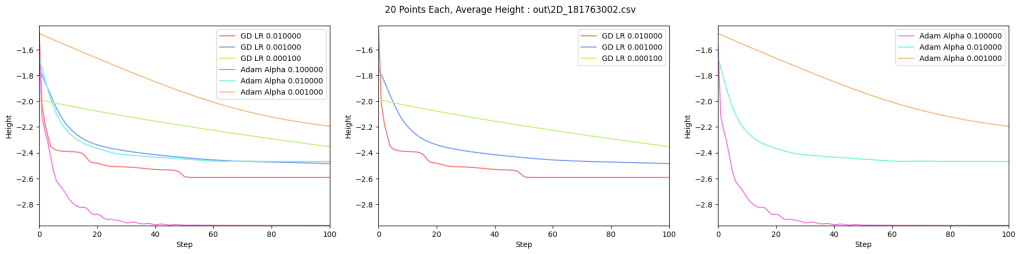
As a test, I’ve compared Adam to plain gradient descent, on finding the minimum height location of a 2D terrain made of randomized Gaussians. The code that made these diagrams and data can be found at https://github.com/Atrix256/Adam
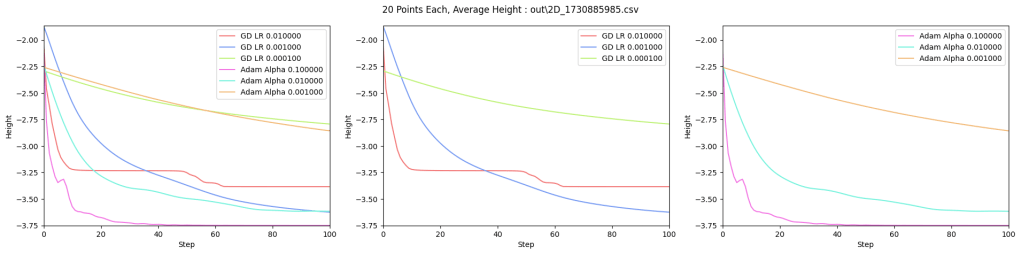
The difference between the two methods is not as big as I’d hoped, but I think Adam does better in higher dimensions (more than the 2 parameters of x and y), where the per parameter (per dimension) adjustable training weight means Adam becomes more maneuverable. In this case for only 2 dimensions, I’m not real impressed. Here’s a relevant quote from Andrej Karpathy (https://karpathy.github.io/2019/04/25/recipe/) though:

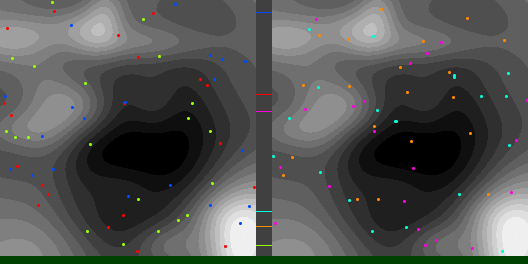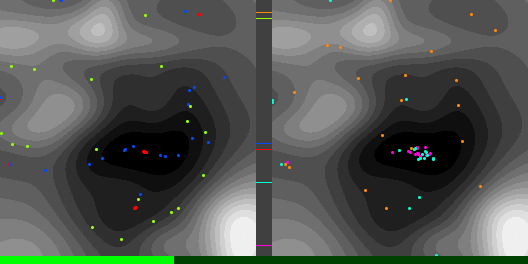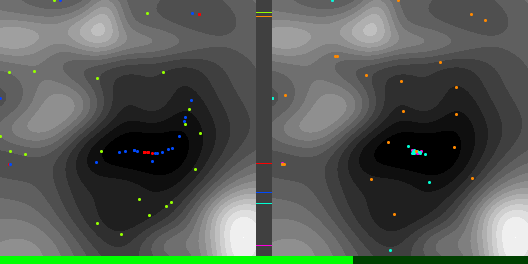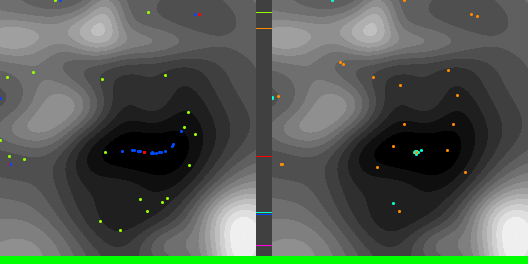
Below are graphs to show how gradient descent (GD) with different learning rates compares to Adam with different alpha parameters, and each to themselves. Also below are animated gifs showing several points of each type searching for the minimum. Gradient descent is on the left, with Adam on the right. The colored bars in the center show the relative average heights of each particle type.
In the animated images, I used only 16 greys to show the Gaussians, to make it easier to read as a topo map, but the actual heights being optimized against are continuous.
Seed = 3684993765
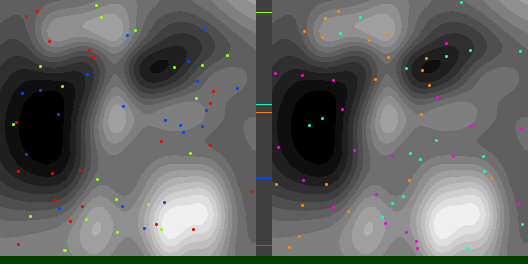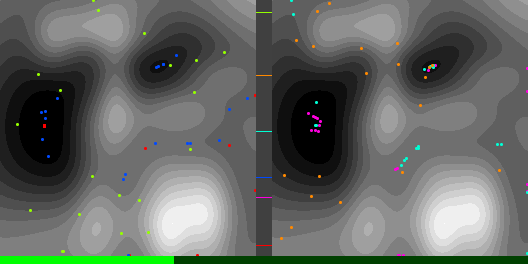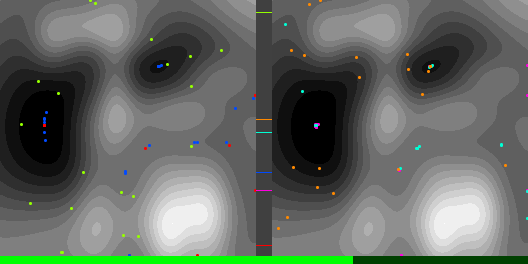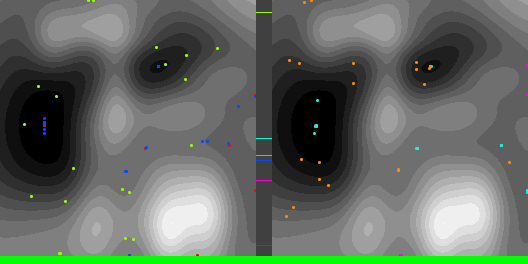
Seed =181763002
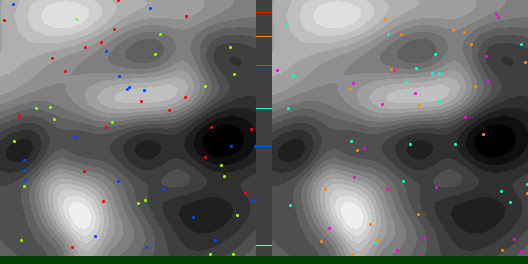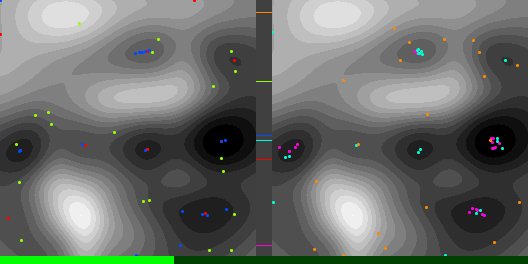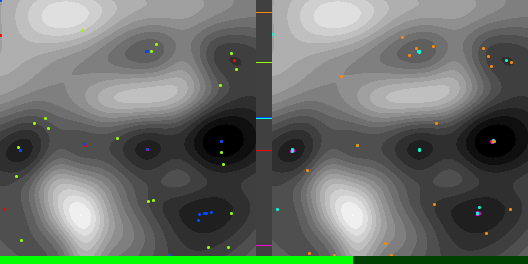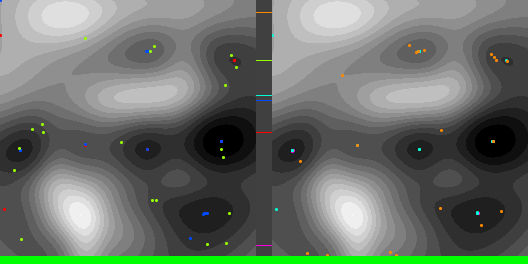
Seed = 1730885985
Links
The paper that introduced Adam is surprisingly easy to read. It’s called “Adam: A Method for Stochastic Optimization” https://arxiv.org/abs/1412.6980
Here are some other resources relating to Adam, and other gradient descent methods.
- An overview of gradient descent algorithms https://www.ruder.io/optimizing-gradient-descent/
- Gradient Descent (and Beyond) https://www.cs.cornell.edu/courses/cs4780/2018fa/lectures/lecturenote07.html
- A Recipe for Training Neural Networks https://karpathy.github.io/2019/04/25/recipe/
- The Math Behind the Adam Optimizer – https://towardsdatascience.com/the-math-behind-adam-optimizer-c41407efe59b
- Code Adam Optimization Algorithm From Scratch https://machinelearningmastery.com/adam-optimization-from-scratch/
- Gentle Introduction to the Adam Optimization Algorithm for Deep Learning https://machinelearningmastery.com/adam-optimization-algorithm-for-deep-learning/
- Tuning Adam Optimizer Parameters in PyTorch https://www.kdnuggets.com/2022/12/tuning-adam-optimizer-parameters-pytorch.html
- [7 minute youtube video] Adam Optimization Algorithm (C2W2L08) https://www.youtube.com/watch?v=JXQT_vxqwIs
- Advantages of Adam over SGD https://qr.ae/pKmZTp
