
Finite differences are numerical methods for approximating function derivatives – otherwise known as the slope of a function at a specific point on the graph. This can be helpful if it’s undesirable or impossible to calculate the actual derivative of a specific function.
This post talks about three methods: central difference, backwards difference and forward difference. They are all based on evaluating the function at two points and using the slope between those points as the derivative estimate.
The distance between those sample points is called an epsilon, and the smaller it is, the more accurate the approximation is in theory. In practice, extremely small values (like FLT_MIN) may hit numerical problems due to floating points number usage, and also you could hit performance problems due to using floating point denormals. Check the links section at the bottom for more info on denormals.
Central Difference
The central difference is the most accurate technique of the three. You can find information about comparitive accuracy of these three techniques in the links section at the end. In practical terms, this may also be the slowest method too – or the most computationally expensive – which i’ll explain further down.
If you want to know the derivative of some function 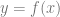


Remembering that the slope is just rise over run, and that the derivative at a point on a function is just the slope of the function at that point, this should hopefully make sense and be pretty intuitive why it works.
The resulting equation looks like:
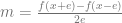
This process is visualized below. The black line is the actual slope at 0.4 and the orange line is the estimated slope. The orange dots are the sample points taken. The epsilon in this case is 0.2.

Interestingly, when dealing with quadratic (or linear) functions, the central difference method will give you the correct result. The picture above uses a quadratic function, so you can see no matter what value of e we use, it will always be parallel to the actual slope at that point. For cubic and higher functions, that won’t always be true.
Backward Difference
The backward difference works just like the central difference except uses different sample points. It evaluates 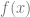
The resulting equation looks like this:
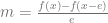
A neat property shared by both this and the forward difference is that many times you are already going to be evaluating f(x) for other uses, so in practice this will just mean that you only have to evaluate f(x-e), and will already have the f(x) value. That can make it more efficient than the central difference method, but it can be less precise.
Also, if you are walking down a function (say, rendering a Bezier curve, and wanting the slope at each point to do something with), you may very well be able to use the f(x) of the previous point as your f(x-e) function, which means that you could possibly calculate the backwards difference by using the previous point, instead of evaluating the function extra times in your loop!
Check out the image below to see how different values of e result in different quality approximations. The smaller the epsilon value, the more accurate the result. An infinitely small epsilon would give the exact right answer.

Forward Difference
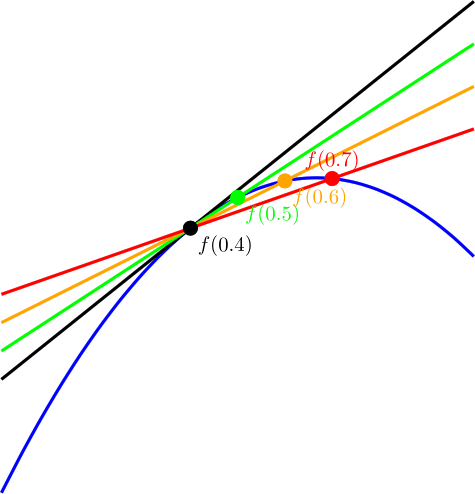
The forward difference is just like the backwards difference but it evaluates forward instead of backwards.
The equation looks like this:
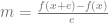
Below you can see it visually. Note again that smaller values of e make the estimation closer to correct.
On the GPU
If you’ve ever encountered the glsl functions dFdx and dFdy and wondered how they work, they actually use these same techniques.
Shaders run in groups, and using dFdx, the shader just looks to it’s neighbor for the value that was passed to it’s dFdx, then using “local differencing” (per the docs), gives each shader the derivative it was able to calculate.
Links
GLSL: dFdx, dFdy
Wikipediate: Finite Difference – The wikipedia page talks about more details, including how to calculate 2nd derivatives and higher!
Floating Point Denormals, Insignificant But Controversial
Comparing Methods of First Derivative Approximation Forward, Backward and Central Divided Difference
