
The other day I had a thought:
Rendering smaller than full screen images is super helpful for performance, but upsizing an image results in pretty bad quality vs a full resolution render.
What if instead of upsizing the final rendered image, we upsized the values that were used to shade each pixel?
In other words, what if we rendered a scene from a less than full resolution g-buffer?
I was thinking that could be useful in doing ray based graphics, not having to trace or march quite so many rays, but also perhaps it could be useful for things like reflections where a user isn’t likely to notice a drop in resolution.
I’m sure I’m not the first to think of this, but I figured I’d explore it anyways and see what I could see.
I made an interactive shadertoy demo to explore this if you want to see it first hand:
Shadertoy: G-Buffer Upsizing
Result
In short, it does look better in a lot of ways because the normals, uv coordinates and similar parameters interpolate really well, but the edges of shapes are aliased really bad (jaggies).
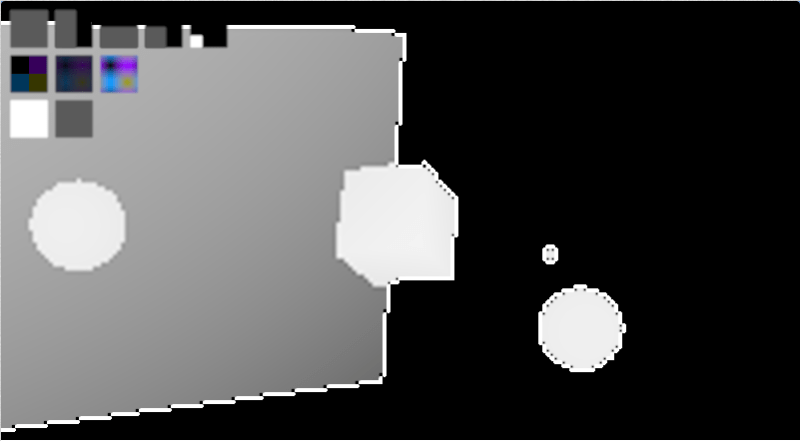
Check out the images below to see what i mean. The first image is a full sized render. The second image is a 1/4 sized render (half x and half y resolution). The third image is a 1/16th sized render (quarter x and quarter y resolution)



For comparison, here’s a 1/4 sized and 1/16 sized render upsized using bicubic IMAGE interpolation instead of g-buffer data interpolation:


Details & More Information
Despite the aliased results at 1/16th render size, this seems like it may be a reasonable technique at larger render sizes, depending on the level of quality you need. Doing half vertical or half horizontal resolution looks very close to the full sized image for instance. The edges are a tiny bit more aliased along one direction, but otherwise things seem decent:

Since the g-buffer has only limited space, you will probably want to bit pack multiple fields together in the same color channels. When you do that, you throw out the possibility of doing hardware interpolation unfortunately, because it interpolates the resulting bit packed value, not the individual fields that you packed in.
Even when doing the interpolation yourself in the pixel shader, for the most part you can really only store information that interpolates well. For instance, you could store a diffuse R,G,B color, but you wouldn’t want to store and then interpolate a material index. This is because you might have material index 10 (say it’s blue) next to material index 0 (say it’s green), and then when you interpolate you could end up with material index 5 which may be red. You’d get red between your blue and green which is very obviously wrong.
In my demo I did have a material index per pixel, but i just used nearest neighbor for that particular value always. To help the appearance of aliasing, I also stored an RGB diffuse color that i interpolated.
I stored the uvs in the g-buffer and sampled the textures themselves in the final shader though, to make sure and get the best texture information I could. This makes textures look great at virtually any resolution and is a lot of the reason why the result looks as good as it does IMO.
The fact that normals interpolate is a good thing, except when it comes to hard edges like the edge of the cube, or at the edge of any object really. In the case of the cube edge, it smooths the edge a little bit, making a surface that catches specular lighting and so highlights itself as being incorrect (!!). In the case of the edge of regular objects, a similar thing happens because it will interpolate between the normal at the edge of the object and the background, making a halo around the object which again catches specular lighting and highlights itself as being incorrect.
I think it could be interesting or fruitful to explore using edge detection to decide when to blend or not, to help the problem with normals, or maybe even just some edge detection based anti aliasing could be nice to make the resulting images better. The depth (z buffer value) could also maybe be used to help decide when to interpolate or not, to help the problem of halos around every object.
Interestingly, bicubic interpolation actually seems to enhance the problem areas compared to bilinear. It actually seems to highlight areas of change, where you would actually want it to sort of not point out the problems hehe. I think this is due to Runge’s phenomenon. Check out the depth information below to see what i mean. The first is bilinear, the second is bicubic:

One final side benefit of this I wanted to mention, is that if you are doing ray based rendering, where finding the geometry information per pixel can be time consuming, you could actually create your g-buffer once and re-shade it with different animated texture or lighting parameters, to give you a constant time (and very quick) render of any scene of any complexity, so long as the camera wasn’t moving, and there were no geometry changes happening. This is kind of along the same lines as the very first post I made to this blog about 4 years ago, which caches geometry in screen space tiles, allowing dirty rectangles to be used (MoriRT: Pixel and Geometry Caching to Aid Real Time Raytracing).
Anyone else go down this path and have some advice, or have any ideas on other things not mentioned? (:
Next up I think I want to look at temporal interpolation of g-buffers, to see what sort of characteristics that might have. (Quick update, the naive implementation of that is basically useless as far as i can tell: G-Buffer Temporal Interpolation).
Related Stuff
On shadertoy, casty mentioned that if you have some full res information, and some less than full res information, you can actually do something called “Joint Bilateral Upsampling” to get a better result.
Give this paper a read to learn more!
Joint Bilateral Upsampling
It turns out someone has already solved this challenge with great success. They use “the MSAA trick” to get more samples at the edges. Check out ~page 38:
GPU-Driven Rendering Pipelines
