
The C++ code that goes with this post is at https://github.com/Atrix256/EulersBestCandidate
The last post talked about links between Euler’s number e, and probability, inspired by a really cool youtube video on the subject: https://www.youtube.com/watch?v=AAir4vcxRPU
One of the things illustrated is that if you want to evaluate N candidates and pick the best one, you can evaluate the first N/e candidates (~36.8%), keep track of the highest score, then start evaluating the rest of the candidates, and choose the first one that scores higher.
That made me think of “Mitchell’s Best Candidate” algorithm for generating blue noise sample points. It isn’t the most modern way to make blue noise points, but it is easy to describe, easy to code, and gives decent-quality blue noise points.
I wrote up the algorithm in a previous blog post (https://blog.demofox.org/2017/10/20/generating-blue-noise-sample-points-with-mitchells-best-candidate-algorithm/) but here is a minimal description:
- If you already have N blue noise points (N can be 0)
- Generate N+1 white noise points as candidates.
- The score for a candidate is the distance between it and the closest existing blue noise point.
- Keep whichever candidate has the largest score.
The above generates one more blue noise point than you have. You repeat that until you have as many points as you want.
So, can we merge these two things? The idea is that instead of generating and evaluating all N+1 candidates, we generate and evaluate (N+1)/e of them, keeping track of the best score.
We then generate more candidates, until we find a candidate with a better score, and then exit, or until we run out of candidates, at which case we return the best candidate we found in the first (N+1)/e of them.
This is done through a simple modification in Mitchell’s Best Candidate algorithm:
- We calculate a “minimum stopping index” which is ceil((N+1)/e).
- When we are evaluating candidates, if we have a new best candidate, and the candidate index is >= the minimum stopping index, we exit the loop and stop generating and evaluating candidates.
Did it work? Here are two blue noise sets side by side. 1000 points each. Can you tell which is which?

Here are the averaged DFTs of 100 tests.

In both sets of images, the left is Mitchell’s Best Candidate, and the right is Euler’s Best Candidate.
The program output shows us that EBC took 71% of the time that MBC did though. Also, the inner most loop of these best candidate algorithms is calculating the distance between a candidate and an existing point. EBC only had to do 73.6% of these calculations as MBC did for the same quality result. While MBC has a fixed number of “hot loops”, EBC is randomized though and has a standard deviation of 3.5 million, when the operation takes at max 333 million, so has a standard deviation of about 1%.
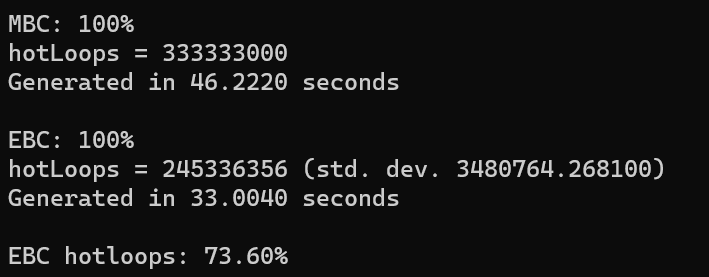
It looks like a win to me! Note that the timing includes writing the noise to disk as pngs.
This could perhaps be a decent way to do randomized organic object placement on a map, like for bushes and trees and such. There are other algorithms that generate several candidates and keep the best one though. It should work just fine in those situations as well. Here is a mastodon thread on the subject https://mastodon.gamedev.place/@demofox/110030932447201035.
The next time you have to evaluate a bunch of random candidates to find the best one, you can remember “find the best out of the first 1/3, then continue processing til the next best one you find, or you run out of items”.
For more info, check out this Wikipedia page, which also talks about variations such as what to do if you don’t know how many candidates you are going to need: https://en.wikipedia.org/wiki/Secretary_problem

Nice, neat idea! I forgot it was suggested to increase the candidate count like this, it seems costly. That reminds me that the void and cluster method to generate blue noise dithering masks first randomly generate a bunch of samples (and optimise them), as a seed, then it just deterministically put each new point directly at the location the farthest apart from all other points. As it also works pretty well, this suggests that you only need to introduce some randomness, add “defects” in the early stages. I also suspect that it’s approximately what happen with MBE as it should give results closer and closer to void and cluster as the candidate count increases.
LikeLike
That’s a great idea applying it to void and cluster. Adding to TODOs as a follow up post 🙂
LikeLike