I haven’t made many blog posts this year, due to working on a project at work that I just got open sourced. The project is called Gigi and it is a rapid prototyping and development platform for real time rendering, and GPU programming. We’ve used it to prototype techniques and collaborate with game teams, we’ve used it in published research (FAST noise), and used it to generate code we’ve shared out into the world.
I also used Gigi to do the experiments and make the code that go with this blog post. Both the Gigi source files and the C++ DX12 code generated from those Gigi files are on github at https://github.com/Atrix256/BNOctaves.
Nikita tagged me in this interesting post with a neat looking screenshot. I thought this was interesting and wanted to look deeper so got the details.
The idea is that you start with a blue noise texture. You then add in another blue noise texture, but 2x bigger and multiplied by 1/2. You then add in another blue noise texture again, but 4x bigger, and multiplied by 1/4. Repeat this as many times as desired. While doing this process you sum up the weights (1 + 1/2 + 1/4 + …) and you divide the result by the weight to normalize it.
Results – Blue Noise
Here is a blue noise texture by itself, made using the FAST command line utility (https://github.com/electronicarts/fastnoise). The upper left is the noise texture. The upper right is the DFT to show frequency content, and the bottom half is a histogram. Here we can see that the texture is uniform blue noise. The histogram shows the uniform distribution, and the DFT shows that the noise is blue, because there is a dark circle in the center, showing that the noise has attenuated low frequencies.
With 2 octaves shown below, there are lower frequencies present, and the histogram gets a hump in the middle. The low frequencies increase because when we double the size of the texture, it lowers the frequency content. The reason the histogram is no longer uniform is because of the central limit theorem. Adding random numbers together makes them follow a binomial distribution, and Gaussian at the limit (more info: https://blog.demofox.org/2019/07/30/dice-distributions-noise-colors/).
With 3 octaves shown below, the effects are even more pronounced.
So yeah, adding octaves of blue noise together does produce blue noise! It makes the distribution more Gaussian though, and reduces the frequency cutoff of the blue noise.
Note: It doesn’t seem to matter much if I use the same blue noise texture for each octave, or different ones. You can control this in the demo using the “DifferentNoisePerOctave” checkbox.
Results – Other Noise Types
After going through the work of making this thing, I wanted to see what happened using different noise types too.
White Noise
Here is 1 octave of white noise, then 3 octaves. White noise starts with randomized but roughly equal levels of noise in each frequency. This process looks to make the low frequencies more pronounced, which makes sense since the octaves get bigger and so are lower frequency.
3×3 Binomial Noise
This noise type is something we found to rival “traditional” (gaussian) blue noise while writing the FAST paper. Some intuition here is that while blue noise has a frequency cutoff equal distance from the center (0hz aka DC), this binomial noise frequency cutoff has roughly equal distance from the edges (aka nyquist). More info on FAST here https://www.ea.com/seed/news/spatio-temporal-sampling.
Below is 1 octave, then 3 octaves. It seems to tell the same story, but the 3 octaves seem to have some concentric rings in the DFT which is interesting.
3×3 Box Noise
Here is noise optimized to be filtered away using a 3×3 box filter. 1 octave, then 3 octaves.
5×5 Box Noise
Here is noise optimized to be filtered away using a 5×5 box filter. 1 octave, then 3 octaves.
Results – Low Discrepancy Noise Types
Here are some types of low discrepancy noise.
Interleaved Gradient Noise
Interleaved gradient noise is a low discrepancy object that doesn’t really have a name in formal literature. I call it a low discrepancy grid, which means we can use it as a per pixel source of random numbers, but it has low discrepancy properties spatially. It was invented by Jorge Jimenez at Activision and you can read more about it at https://blog.demofox.org/2022/01/01/interleaved-gradient-noise-a-different-kind-of-low-discrepancy-sequence/.
Here is 1 octave then 3 octaves. The DFT goes from a starfield to a more dense starfield.
// R2 Low discrepancy grid
// A generalization of the golden ratio to 2D
// From https://extremelearning.com.au/unreasonable-effectiveness-of-quasirandom-sequences/
float R2LDG(uint2 pos)
{
static const float g = 1.32471795724474602596f;
static const float a1 = 1 / g;
static const float a2 = 1 / (g * g);
return frac(float(pos.x) * a1 + float(pos.y) * a2);
}
1 octave, then 3 octaves. The DFT goes from a starfield, to a swirly galaxy. That is pretty cool honestly! The histogram also have a lot less variance than other noise types, which is a cool property.
Wait… Isn’t This Backwards?
When we make Perlin noise, we start with the chunky noise first at full weight, then we add finer detail noise at less weight, like the below with 1 and 8 octaves of perlin noise.
In our noise experiments so far, we’ve been doing it backwards – starting with the smallest detailed noise at full weight, then adding in chunkier noise as lower weight. What if we did it the other way? The demo has a “BlueReverse” noise type that lets you look at this with blue noise. Here is 1, 3 and 5 octaves:
It has an interesting look, but does not result in blue noise!
Use of Gigi – The Editor
I used Gigi to make the demo and do the experiments for this blog post. You can run the demo in the Gigi viewer, or you can run the C++ dx12 code that Gigi generated from the technique I authored.
I want to walk you through how Gigi was used.
Below is the technique in the Gigi editor. The “CS: Display” node makes the noise texture with the desired number of octaves. “Sub: Histogram” makes the histogram graph. “Sub: DFT” makes the DFT. “CS: MakeCombinedOutput” puts the 3 things together into the final images I pasted into this blog post.
If you double click the “Sub: Histogram” subgraph node, it shows you the process for making a histogram for whatever input texture you give it. This is a modular technique that you could grab and use in any of your Gigi projects, like it was used here!
If you double click the “Sub: DFT” subgraph node instead, you would see this, which is also a modular, re-usable technique if ever you want to see the frequency magnitudes of an image. Note: This DFT is not an FFT, it’s a naive calculation so is quite slow.
Use of Gigi – The Viewer
If you click “Open Viewer” in the main technique (BNOctaves.gg) it will open it in the viewer. You can change the settings in the upper left “Variables” tab and see the results instantly. You can also look at the graph at different points in the execution on the right in the “Render Graph” tab, and can inspect the values of pixels etc like you would with a render doc capture. A profiler also shows CPU and GPU time in the lower left. (I told you the DFT was slow, ha!). For each image above in this blog post, i set the parameters like I wanted and then clicked “copy image” to get it to paste into this blog post.
Use of Gigi – The Compiler & Generated Code
I used GigiCompiler.exe to generate “DX12_Application” code for this technique and the results of that are in the “dx12” folder in the repo. You run “MakeSolution.bat” to have cmake create BNOctaves.sln and then can open and run it. Running that, you have the same parameters as you do in the viewer, including a built in profiler.
I did have to make one modification after generating the C++ DX12 code. There are “TODO:”s in the main.cpp to help guide you, but in my case, all I needed to do was copy the “Combined Output” texture to the render target. That is on line 456:
// TODO: Do post execution work here, such as copying an output texture to g_mainRenderTargetResource[backBufferIdx]
CopyTextureToTexture(g_pd3dCommandList, m_BNOctaves->m_output.texture_CombinedOutput, m_BNOctaves->m_output.c_texture_CombinedOutput_endingState, g_mainRenderTargetResource[backBufferIdx], D3D12_RESOURCE_STATE_RENDER_TARGET);
Closing
I sincerely believe that “the age of noise” in graphics has just begun. I more mean noise meant for use in sampling or optimized for filtering, but that type of noise may have use in procedural content generation too, like this post explored.
I am also glad that Gigi is finally open sourced, and that I can use this absolute power tool of research in blog posts like this, while also helping other people understand the value it brings. Hopefully you caught a glimpse of that in this post.
The C++ code that goes with this blog post can be found at https://github.com/Atrix256/GoldenRatioShuffle and includes a header file that contains a shuffler that should be easy to drop into other C++ code.
A shuffle iterator lets you iterate through a shuffle without actually doing the shuffle. It can provide the next item when asked while only storing your current index into the shuffle and the random seed. A friend and I wrote an article showing how to achieve that using mathematics and cryptography: https://www.ea.com/seed/news/constant-time-stateless-shuffling
However, the shuffle made with that technique is a “white noise shuffle”. That is, each item in the shuffle has equal probability of being anywhere in the shuffle and each item in the shuffle an independent random number (uniform random selection without replacement). This is useful anywhere a shuffle is used, but in many situations, the algorithm using the shuffled data could perform better if it could use something better than white noise. I recorded a video that talks about the benefits of going beyond white noise here: https://www.youtube.com/watch?v=tethAU66xaA
In this post, I’ll show how to make a stateless constant time shuffle iterator which:
Takes an irrational number to drive the shuffle sequence
Takes a random seed
Supports random access
Supports inversion
Each briefly explained:
Takes an irrational number to drive the shuffle sequence
The golden ratio is best, but if you need multiple shuffles, having two shuffles based on the same irrational number will cause them to be correlated. Like imagine two sine waves, but starting at different angles (phases / offsets). That correlation will show up in what you are using the shuffles for and be a problem. Using different high quality irrational numbers for each shuffle will make them be more uncorrelated, depending on the numbers used. See the previously mentioned youtube video for more details about high quality vs low quality irrational numbers. Note that this also touches on something I call “co-irrational numbers” that you can read about here: https://blog.demofox.org/2020/07/26/irrational-numbers/
The golden ratio is the best choice, but the square root of 2 is also good, as is the square root of 3. Pi however is a very bad choice!
Takes a random seed
The shuffle in this article is a deterministic sequence that gives every item [0,N) exactly once before repeating, and does so in a quasirandom order.
You can imagine that you could add a constant to every item in that sequence and apply modulo N to bring it back to being in [0,N). That constant is the random seed and that is how we apply the seed. So, for a list of N items long, the random seed can be any value between 0 and N-1.
Supports Random Access
You can either ask for the next item in the list, or you can ask for the Mth item in the list.
That is, you can have a shuffle with 4 billion items in it and ask “what is the 1 billionth item in the shuffle?” and it will tell you in constant time – taking just as much computing power / time as if you asked what the 1st item in the shuffle was.
Supports Inversion
You can ask when a specific item will show up in the shuffle.
Again, if you are shuffling 4 billion items, you can ask it “At what point in the shuffle does the 5th item appear?” and it will give you the answer, in constant time again.
Let’s dive into the details.
Low Discrepancy Sequence to Low Discrepancy Shuffle
A well known and powerful one dimensional low discrepancy sequence (LDS) is the golden ratio LDS, which is calculated like this in C++:
The first time you call that function, you can pass any value in between 0 and 1 as the “initial state” or “random seed”. Every time you call it after that, it returns a value between 0 and 1 that you can use as a “random number” in your code. This works for numerical integration (quasi monte carlo integration), but also improves things like calculating treasure drops when a player kills a monster in a video game – see the previously mentioned youtube video for more info.
If you wanted to use these values in [0,1) to shuffle N items, you might think to multiply those values by N and clamp to [0,N-1), or something similar.
That works pretty well, but there are repeats! With an initial starting state of 0.55, here are 10 items shuffled:
5 1 7 4 0 6 2 8 4 1
That sequence has 1 and 4 twice, and misses 3 and 9.
There is a neat trick from Marc Reynolds to convert the golden ratio into an integer for when you want integer sequences (http://marc-b-reynolds.github.io/distribution/2020/01/24/Rank1Pre.html). He does it by multiplying the golden ratio by the number of integers there are and rounding to odd (round up or down, to whichever is the odd number). This treats the [0,N) integer range as if it were the real number range [0,1). It’s basically changing from working in floating point, to fixed point, and gives better results than using the golden ratio with conversion to integers.
That is nice, but doing that, it can still have repeats. Rounding to odd helps it have a longer period sequence, but it is not always a maximal period sequence. To make a maximal period sequence, we would need our integer approximation of the golden ratio to be coprime to the number of items in our shuffle.
We can search for such a number by checking if the number is coprime. If not, look at the number -1, then +1, then -2, then +2 and so on. We will eventually find the number coprime to N that most closely approximates the golden ratio. The farther we get from the golden ratio, the more our low discrepancy properties are degraded, so we want to be as close as possible.
Here’s the graph of the real number GoldenRatio*N (blue) and the integer coprime found (red) up to N=1000, you can see the coprime found is very close.
Here is a graph of the difference between the two. It never goes above 3.5.
So to make a low discrepancy shuffle iterator happens in two steps.
If we have an irrational number A, and want to shuffle N items, we find the integer coprime to N, which is closes to the real number (A*N). We’ll call this P.
Once we have P, we can call this function iteratively to get the next item in the shuffle:
unsigned int Shuffle_NextValue(unsigned int lastValue, unsigned int P, unsigned int N)
{
return (lastValue + P) % N;
}
To give this shuffle a random seed, the first time you call this function, give it a lastValue which is a random integer in [0,N).
Let’s look again at the golden ratio sequence before of 10 items which started at index 5 (a starting value of 0.548813522 for the LDS) and had some duplicates and missing items. We shuffled N=10 items, which gives us a coprime P=7, and we’ll start at index 5.
Sequence
Duplicates
Missing
LDS
5 1 7 4 0 6 2 8 4 1
1 4
3 9
Coprime
5 2 9 6 3 0 7 4 1 8
–
–
The coprime approximation of the golden ratio gets rid of duplicates / missing values, while still being a nice low discrepancy sequence. Neighboring values are “very different” from each other.
Here is a 64 item shuffle with coprime P=41. The index started at 26, and the LDS started at 0.417021990.
The code that goes with this post lets you see the error rate of LDS at different item counts and with different seeds, but the number of missing items in the LDS version of the shuffle is usually around 10-20%. The coprime version never misses any items, and is always pretty close to the integer (fixed point) approximation of the golden ratio.
Random Access
The code for the random access shuffle iterator is shown as an iterative process: you start at the first item and call Shuffle_NextValue() to get the next item. Rinse and repeat until you call it N times and the shuffle starts over.
The shuffle iterator does support random access though. If you want to know what item is at a specific shuffle index, the result is (index*P)%N. if index is a large enough number, you can start to hit problems with overflow though. To help this a bit, you can first modulus index by N, since the shuffle repeats itself every N steps.
That gives you this following code, which does give random access, but can still have integer overflow problems if index and N are large enough. So, be careful and take extra precautions when needed!
unsigned int Shuffle_RandomAccess(
unsigned int index,
unsigned int shuffleSeed,
unsigned int P,
unsigned int N)
{
return (((index % N) * P) + shuffleSeed) % N;
}
Inversion
If we want to know what location a specific item will show up in the shuffle, we can do that. Ignoring the integer overflow problems, and random seed for a moment, the formula for our random shuffle is this:
If we know item, P and N, and we want to know index, we are trying to calculate the “Modular Multiplicative Inverse”, which you can do using the “Extended Euclidean Algorithm”. It’s an iterative algorithm, but is not complicated or super expensive to calculate.
The extended euclidean algorithm tells you what you need to multiply P by to get 1. it gives you the x below.
Once you know how many steps it takes to get to 1, you can double it to get to 2, or triple it to get to 3 and so on. So if you want to know how many times it takes adding P to 0 to get to a specific number, you just multiply x by that number. That number may be much larger than N but you can just put it through modulo N since the sequence repeats every N times.
To handle the seed, you need to subtract out how many times you add P to 0 to get to the seed value.
In the end, the inversion algorithm looks like this:
Notice on the last step we are adding an extra numItems before subtracting stepsToSeed. This is to handle the case where stepsToSeed is larger than stepsToValue and prevent integer underflow.
If you needed to do inversion often, you could store off that t value to make inversion lightning fast, without having to run the extended Euclidean algorithm each time.
To help show why this shuffle is meaningful, we take 10,000 items valued 0 to 9,999, divide them by 9,999 to make them be between 0 and 1, and we iteratively average them from index 0 to index 1, index 2, index 3 and on up to index 9,999.
We do this for both a white noise shuffled array, and also this post’s low discrepancy shuffle iterator. We do that 1000 times and collect the average error.
Below is the graph of that data, which shows the low discrepancy shuffle iterator (blue) far outperforms the white noise shuffled array (orange). It gives a much better average much sooner which shows that it’s low discrepancy and has the desirable numerical properties we would expect from a golden ratio sequence, while still being a shuffle.
Hopefully you enjoyed this post. If you end up using this shuffle iterator for anything and see benefits, I’d love to hear about it here, or on mastodon, at https://mastodon.gamedev.place/@demofox
The C++ code that goes with this blog post can be found at https://github.com/Atrix256/GoldenRatioShuffle and includes a header file that contains a shuffler that should be easy to drop into other C++ code.
Here it is as shadercode (hlsl) as well:
// Example calculations
// 128x128 is 16384 pixels to shuffle, so numItems = 16384
// Coprime is 10127, calculated by code at that repo to be the coprime value closest to the golden ratio.
// StepsToUnity is 5999, calculated by code at that repo, using the chinese remainder theorem.
// Seed is the random seed of the shuffle, such as the constant "435".
// Return shuffle[index]
uint LDSShuffle1D_GetValueAtIndex(uint index, uint numItems, uint coprime, uint seed)
{
return ((index % numItems) * coprime + seed) % numItems;
}
// return the index where shuffle[index] == value
uint LDSShuffle1D_GetIndexOfValue(uint value, uint numItems, uint stepsToUnity, uint seed)
{
uint stepsToValue = (stepsToUnity * value) % numItems;
uint stepsToSeed = (stepsToUnity * seed) % numItems;
return (stepsToValue + numItems - stepsToSeed) % numItems;
}
Disclaimer: This is based on information I believe to be true, in 2024, in the United States, and in the state of California specifically. Laws change over time and there are subtleties to all these things, so please talk to a financial professional before taking specific actions. I do hope this helps illuminates how to get the most out of these benefits though.
If you are a programmer (and mhigherany other fields), you are likely to encounter an Employee Stock Purchase Plan (ESPP) at your work. If you work in an in demand area, you are also likely to encounter Restricted Stock Units (RSUs) as well. This article aims to help illuminate some things I wish I knew / realized earlier in my career.
Let’s talk about how these work.
How Do ESPPs Work?
ESPPs let you deduct money out of your pay check automatically, into an account, where periodically (like once a quarter) it is used to buy company stock. There is commonly a “look back” window of time where the price you pay per share of the stock is the lowest price of the stock in that window of time. Also commonly, the stock is offered at a discount on top of that, say 5%, 10% or 15% off.
The money taken out of your paycheck is post-tax, meaning you pay income tax on the money you use to buy the stock.
When you sell the stock, the amount of discount you had on buying the shares become income, which follows regular tax income rules for both federal and state taxes. If the stock has gone up, capital gains applies to the increased value.
Example:
Let’s say you had 1700$ in your account when it was time for the stock buy to happen. Let’s say the current price of the stock was 130$, but that there was a 6 month “look back” window, and the lowest price of the stock in the last 6 months was 100$. You get to purchase stock at 100$, instead of at the 130$ it currently costs. Buying the stock already gives you a profit of 30$ a share! On top of this, let’s say you get a 15$ discount. That 15% discount applies to the 100$ price, meaning you get to buy shares at 85$ instead of the current market price of 130$. That allows you to buy 20 shares of stock for that 1700$, instead of the 13 you could buy at the current market price.
Let’s say you hold onto the stock for a while and it goes up to 250$ a share, and then you decide to sell.
Since you bought 20 shares of stock at 85$, when the stock was actually 130$ a share, that discount of 45$ per share becomes taxable income. 45$ * 20 shares = 900$ of increased taxable income on your tax return, to perhaps push you into a different tax bracket.
However, the stock also went up 120$ a share. 120$ * 20 shares = 2400$ of “capital gains”. In the united states, for federal taxes, if you’ve held this stock for less than 1 year, you pay “short term capital gains” tax, which means the capital gains are treated as regular income, that can push you into a different tax bracket and all of that. If you’ve held onto it for longer than a year, you pay “long term capital gains” which is taxed based on your income, but most folks will be in the 15% bracket.
In the state of California, there is no distinction between long and short term capital gains. The gains all become taxable income.
RSU stands for “Restricted Stock Unit” and they are stock that is promised to you that vests (becomes yours) over a specified schedule. For instance, you may be given 480 RSUs when you are hired, with 120 vesting (being given to you) at your 1 year anniversary, and 30 more every quarter for the 3 years after that until all are 480 shares are vested.
When the stock vests, it becomes yours, but the value of the stock becomes taxable income that you pay that year. Whenever you sell the shares and if the value has gone up, you then have to pay short term gains if you’ve held the stock less than a year, or long term if you’ve held it more than a year. Same as ESPPs.
Lets look at some motivations of these benefits. Reality is complicated per usual, with a mix of both optimistic and cynical truths.
ESPP
An optimistic viewpoint of ESPPs is that it’s a way to invest in the company because you believe it’s going to do well. The company thinks so too and is helping you out by giving these shares to you at a discount. How awesome!
A more cynical viewpoint is that any money a company pays an employee that goes into the ESPP program never actually left the company. It can effectively reduce payroll costs, turning some of those guaranteed payroll funds into not guaranteed stock holder returns, where the employee takes on the risk. If the company does well, yeah, the employees with ESPP will cash out some, but there will be extra money around to fund that. If the company does poorly, the employees with ESPP will lose, and get their money back at a reduced rate, which is great for the company, effectively having to pay less payroll if things are going poorly.
RSUs
An optimistic viewpoint here is that a company is going to do well, so giving you stock is going to benefit you in the future when the stock goes up.
A reality of the vesting schedule is that you are less likely to leave if you have significant amount of stock that hasn’t vested yet. It helps retention.
A more cynical viewpoint is that RSUs are better for the company than a cash bonus, because the money is still invested in the company (they didn’t actually have to pay anything out). Also, you are given shares, not dollar amounts, so the risk of how much that is actually worth goes to you, the employee.
Bottom Line
The bottom line is that giving stock is a way of not actually giving anything in the short term, and putting any longer term risk on you, the employee. It’s a pretty clever business move frankly. Despite this, these benefits are still beneficial to you – you will get that money eventually!
How Can I Take Most Advantage of These Benefits?
So, companies definitely have an angle on these benefits and are certainly going to do everything in their power to get the most out of it from their side. They are likely to offer educational material that lists the benefits that help them, but not say the things I’m about to say below. So how can you make the most of it for yourself?
ESPPs
If you believe the stock is going to go up, and you want the stock, go ahead and buy the stock! Max out the amount you contribute if you can afford it and sell when you are ready.
If you don’t believe the stock is going to go up, another way of thinking about ESPPs is that they are allowing you to buy money at a discount. If your ESPP program gives you a 15% discount on the stock, that means you only pay 85 cents for every dollar of stock you buy. This stock is paid for with money you are already paying income tax on so buying this stock doesn’t do anything special for you as far as taxes are concerned. You are welcome to then IMMEDIATELY sell the stock, right after purchase and get your dollar back for every 85 cents you paid. It’s true that you then have to take the 15 cents on the dollar as income and pay income tax on it, but that is the same as if you got a raise. If you immediately sell your ESPP stock after buying it, you are essentially giving yourself a raise. Why wouldn’t you do that? And why wouldn’t you max out how much you were contributing to ESPP to max out your raise?
Something to watch out for though is that if the stock is sold to you a lot lower because of the “look back” window, the difference between what you bought it for and what you sold it for becomes “capital gains”, with the short term vs long term implications I explained above. It might be that you prefer to hold onto that stock for a year before selling, to pay a smaller amount of tax on it. If this issue comes up, it’s a good problem to have though. The problem is basically “What do I do with all this money?!”
In short, if you don’t want the stock, and the stock is flat, or decreasing in value, you can max out your ESPP, and sell immediately after the buying event, to give yourself a raise.
RSUs
Again, if you believe the stock is going to go up, and you want the stock, go ahead and keep these RSUs.
If you don’t believe the stock is going to go up, what should you do?
When your RSUs vest, you pay income tax on the value they are at the time of vesting. This is equivalent to the company paying you more, and you go out and buy stock with that extra pay. If this wasn’t your plan for the money, sell it right when it vests! Convert it back into cash. The stock isn’t going to have changed price (except normal market fluctuations), so you aren’t going to have any gains. Take the cash and walk away, as if the stock purchase never happened. This is fine and doesn’t affect your taxes at all.
Furthermore, let’s say you are working at a company where you either don’t have any more RSUs waiting to vest, or you only have a small amount remaining. If you are in a position where you were given RSUs, you can likely go to a competitor, and get more RSUs from them as a signing bonus. Even if you have the same title, job function, and pay, go get some RSUs from the competition and look out for #1 (yourself). When a company is interested in retaining employees, they will offer them more RSUs to keep this vesting train going. If your company is not doing that for you, they are either not very smart, or they are not interested in keeping you. Either way, it might be a good time to jump elsewhere 🙂
Watching The Stock Market
When you have a lot of money in the stock market, it can be nerve wracking. Having “decent fractions of your pay” in the stock market is a lot of money IMO. You might feel like you need to be constantly watching the market to protect your money, in case there is a big spike up or a big spike down.
A nice thing to help this is there are things called “stop orders” and “limit orders” that can help automate some simple tasks to help you not be constantly glued to stock tickers. There are also more complicated things such as “stop limit” orders.
For instance, you can say “Sell this much stock if the price drops below 400$ a share” with a stop order. Sometimes stock can be volatile, and it could drop down to 200$ a share for a moment, then jump back up to 450$ a share. With a stop order, your stock might sell during that moment when it dropped down to 200, and you get sort of screwed, selling your stock too cheaply and losing money. A stop limit order lets you set a minimum price so you can say “Sell this much stock if the price drops below 400$ a share, but don’t sell if it goes below 350$ a share”.
With something like that in place, you can happily go off and have lunch without having to check your phone every few minutes just in case LOL.
ESPP and RSUs can be nice perks when working for companies, but it’s important to know how these mechanisms work, to help make the best decisions for yourself and your own situation.
If you want the stock, by all means, keep it! Otherwise…
ESPPs can be a way to give yourself a raise. You deserve it, give yourself that raise!
RSUs are as if you were given extra pay, but the company bought stock with it before they gave it to you. Sell that stock if you weren’t going to buy stock with that money anyways, and take that cash, for the same tax implications.
I recently published a set 3 of articles on machine learning in plain C++ for game developers, as well as a video version of the same content. This article explains an improvement to plain gradient descent called Adam and can be read as a follow up to those articles.
Let’s say we wanted to find the values of the x parameters in the function below that gives the lowest y value:
This is an optimization problem and functions of this form are called cost functions. Gradient descent is a method for doing this optimization, where you start with a random set of x values, and “roll down hill” by making small adjustments to those x values that lead to lower y values. You can stop either after a specific number of steps, or when the y value is below some threshold.
The gradient of a function is a vector of the partial derivatives of the x parameters, and the vector as a whole points the steepest direction up hill on the surface of the function. If you want to go the steepest direction down hill, you just go in the opposite direction.
A challenge is that the steepest path down hill is most often a curved path, not a straight line. To deal with this, you can take small steps down hill and re-evaluate the gradient at each step to figure out the direction to step in next. In machine learning, this step size is called the learning rate and is often called α (“alpha”) and is tuned by hand.
Smaller steps give you a more accurate result, but may be computationally wasteful, taking many small steps when you could take fewer, larger steps towards the goal. This makes for longer than necessary computation (or training) times.
Larger steps might be able to get you nearer to the goal faster, but if the minimum value of the function lies in a deep, narrow canyon, large steps won’t be able to get you into the deepest part of the function.
Having to adjust this learning rate by hand, and having the appropriate learning rate change as you do gradient descent is one of the two problems Adam addresses, by turning down the learning rate when the terrain gets more complicated / bumpy.
Another challenge with gradient descent is that it’s possible to get stuck in a shallow valley when there is a much deeper canyon waiting to be found. This is called a local minima, because while it’s the deepest point locally, it isn’t the globally deepest part of the function, or the global minimum.
A common way of dealing with this is to add momentum to our imaginary ball rolling down hill, so that it can escape local minima and hopefully find deeper, more global minima. If not, it should just roll back into the minima it did find. Momentum is the second benefit Adam gives over plain gradient descent.
Adam is a popular, and simple, method of improving gradient descent and is heavily used in machine learning, which uses gradient descent to train neural networks.
Adam
Adam has 4 parameters, but only alpha usually needs to be tuned.
Alpha – This is essentially the learning rate.
Beta1 – The rate of exponential moving average of the derivative (First Moment). Default is 0.9.
Beta2 – The same for the derivative squared (Second Moment). Default is 0.999.
Epsilon – a value to prevent division by zero. Default is 1e-8.
Adam works by keeping an exponential moving average of the derivative (the first moment of the derivative), as well as a moving average of the derivative squared (the second moment of the derivative), each with their own smoothing factor. In this way, this gives Adam an imperfect memory of the derivatives it has seen, tending to forget older derivative values, and weight newer derivative values more highly. The squared derivative moving average is also more sensitive to large outliers.
The code for doing this is straight forward:
static const float c_beta1 = 0.9f;
static const float c_beta2 = 0.999f;
m = c_beta1 * m + (1.0f - c_beta1) * derivative;
v = c_beta2 * v + (1.0f - c_beta2) * derivative * derivative;
Interestingly, the m calculation is the same as doing a lerp from m to derivative with a t value of 0.1. If you work in real time rendering, that should look familiar, as that is how TAA (Temporal Anti Aliasing) works as well, also often using a value of 0.1. v works similarly, but uses a t value in the lerp of 0.001.
So, m and v are a moving average of recent derivative and derivative squared values respectively.
The learning rate alpha is then multiplied by m and divided by the square root of v, to calculate an adjusted derivative to use for gradient descent.
float adjustedDerivative = alpha * m / sqrt(v);
if the derivative was a constant, m would be that constant value, and so would sqrt(v), which means alpha would be the amount to adjust the parameter by. if m was bigger than sqrt(v), it would increase the learning rate, else if m is smaller than sqrt(v), it would decrease the learning rate. Through this simple operation, Adam gives both momentum to escape local minima, as well as the ability to slow down when there are more details to explore on the surface of a function.
We aren’t quite done though. If you work in graphics, you likely have noticed that when using TAA, the first several frames rendered are darker than they should be, before enough frames have been processed. This same problem occurs in Adam, meaning that when it’s first starting out, both m and v are biased towards zero. Adam does bias correction to account for this, essentially making the numbers larger (or for TAA, it’d make the pixels brighter). It calculates an “m hat” and a “v hat”, and that is what is used to calculate the learning rate instead of the raw m and v. Since v hat could possibly be zero, we have to account for that in the division.
Putting it all together, here is a small struct you can use to put a derivative through Adam to get an adjusted derivative. You would have one of these per parameter to your function, so that Adam was able to adjust the learning rate of each parameter individually.
// Note: alpha needs to be tuned, but beta1, beta2, epsilon as usually fine as is
struct Adam
{
// Internal state
float m = 0.0f;
float v = 0.0f;
// Internal state calculated for convenience
// If you have a bunch of derivatives, you would probably want to store / calculate these once
// for the entire gradient, instead of each derivative like this is doing.
float beta1Decayed = 1.0f;
float beta2Decayed = 1.0f;
float GetAdjustedDerivative(float derivative, float alpha)
{
// Adam parameters
static const float c_beta1 = 0.9f;
static const float c_beta2 = 0.999f;
static const float c_epsilon = 1e-8f;
// exponential moving average of first and second moment
m = c_beta1 * m + (1.0f - c_beta1) * derivative;
v = c_beta2 * v + (1.0f - c_beta2) * derivative * derivative;
// bias correction
beta1Decayed *= c_beta1;
beta2Decayed *= c_beta2;
float mhat = m / (1.0f - beta1Decayed);
float vhat = v / (1.0f - beta2Decayed);
// Adam adjusted derivative
return alpha * mhat / (std::sqrt(vhat) + c_epsilon);
}
};
An interesting aspect of Adam is that you can see that it adjusts the step size (alpha) by saying “be bigger” or “be smaller” but it never gives a specific value that is an optimal step size, and you still have to tune the learning rate value by hand. To me, that looks like something we’ll likely have a better answer to in the future.
I also find it interesting that adam calculates an adjusted learning rate (alpha) and doesn’t multiply the derivative by that, but just uses that for the derivative instead. That makes it so while the length of a function’s gradient may change from location to location, this actual step size is more fixed, and is just affected by how the gradient changes over time.
Another thing people do with gradient descent is start with a larger learning rate, and decrease it over time. This helps the gradient descent move quickly in the beginning to get closer to the global minimum, and then as it slows down, it helps it refine the search. Interestingly, some people do this ALONG SIDE of Adam, which to me makes some sense. Since Adam can only slow down or speed up a learning rate, but not set it to a specific value, it seems like it could be a good idea to decrease the learning rate over time as well. But, then you have another hyper parameter to tune – how much should alpha decrease each iteration?
Results
As a test, I’ve compared Adam to plain gradient descent, on finding the minimum height location of a 2D terrain made of randomized Gaussians. The code that made these diagrams and data can be found at https://github.com/Atrix256/Adam
The difference between the two methods is not as big as I’d hoped, but I think Adam does better in higher dimensions (more than the 2 parameters of x and y), where the per parameter (per dimension) adjustable training weight means Adam becomes more maneuverable. In this case for only 2 dimensions, I’m not real impressed. Here’s a relevant quote from Andrej Karpathy (https://karpathy.github.io/2019/04/25/recipe/) though:
Below are graphs to show how gradient descent (GD) with different learning rates compares to Adam with different alpha parameters, and each to themselves. Also below are animated gifs showing several points of each type searching for the minimum. Gradient descent is on the left, with Adam on the right. The colored bars in the center show the relative average heights of each particle type.
In the animated images, I used only 16 greys to show the Gaussians, to make it easier to read as a topo map, but the actual heights being optimized against are continuous.
Seed = 3684993765
Seed =181763002
Seed = 1730885985
Links
The paper that introduced Adam is surprisingly easy to read. It’s called “Adam: A Method for Stochastic Optimization” https://arxiv.org/abs/1412.6980
Here are some other resources relating to Adam, and other gradient descent methods.
This post explains how to use sliced optimal transport to make blue noise point sets. The plain, well commented C++ code that goes along with this post, which made the point sets and diagrams, is at https://github.com/Atrix256/SOTPointSets.
Let’s say we wanted a set of points randomly placed in 2D, but with even density – aka we wanted 2D blue noise points in a square.
We could start by generating 1000 white noise points, then using sliced optimal transport to make them evenly spaced:
Project all points onto a random unit vector. Calculate how much to move each point to make them be evenly spaced on that 1D line, in the same order.
Calculate the average of that process done 64 times, then move the points that amount.
Repeat this process 1000 times.
Doing that, we start with the points on the left and end up with the points on the right.
That looks like good blue noise and only took 0.56 seconds to generate, but confusingly, the points are on a disk and are denser near the edges. We’ll make the density uniform in this section, and will make the points be in a square in the next section.
The reason we are getting a disk is because we are projecting the points onto random directions and making the points be on that line, up to a maximum distance away from the origin. That is forcing them to be inside of a disk.
The reason the points are denser near the edges is because we are making the points evenly spaced on the 1D lines, but there is less room vertically on the disk near the edges. That means the points have less space to occupy at the edges, causing them to bunch up.
To account for this, we need to make there be more points in the center, and fewer at the edges. More specifically, we need each point to claim an even amount of disk area, not an even amount of line width.
Below shows a circle divided into evenly spaced slices on the x axis (top), and slices of equal area (bottom). (diagram made at https://www.geogebra.org/geometry)
We can do this in a couple of steps:
Get the formula for the height of the disk has at a given x position. We’ll call this y=f(x).
Integrate that function to get a y=g(x) function that tells you how much area the disk has at, and to the left of, a given x position.
Divide g(x) by the area of the disk to get a function h(x) that gives a value between 0 and 1.
Invert h(x) by changing it from y=h(x) to x=h(y) and solving for y. That gives us a function y=i(x).
Plug the evenly spaced values we were using on the line into the function i, to get positions on the line that give us equal values of disk area.
This might look more familiar from a statistics point of view. f(x) is an unnormalized PDF, g(x) is an unnormalized CDF, h(x) is a CDF (normalized), and i(x) is an inverse CDF.
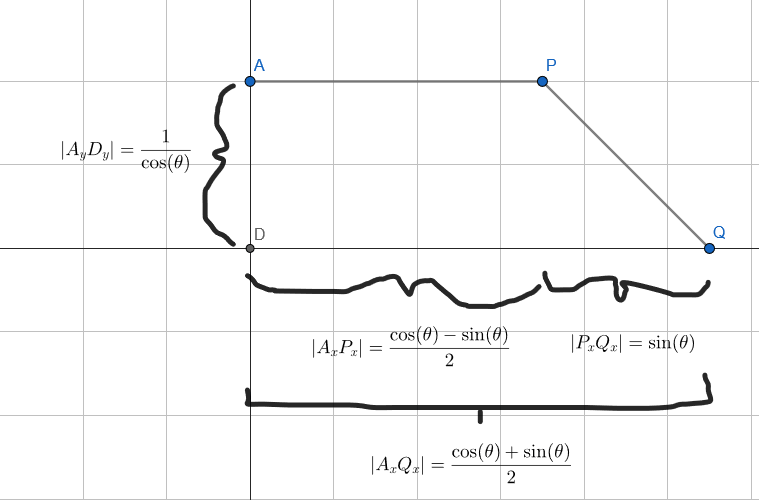
If we have a disk centered at (0,0) with radius 0.5, the height of the disk at location x can be found using the Pythagorean theorem. We know x, and the hypotenuse is the radius 0.5, so . That only gives us the top half of the disk height, but we can double it to get the bottom half as well: .
We can take the integral of that to get . Dividing that by the area of the disk, we get
Instead of inverting that function, I made a table with 1000 (x,y) pairs of x and y=h(x). In the table, x is between -0.5 and +0.5, but I also made y be between -0.5 and +0.5. That is a bit different than a CDF where y goes from 0 to 1, but this is just a convention I’m choosing; a standard CDF would work as well. To evaluate i(x), i find the location where the given value shows up in the table as a y value, and give back the x that gave that y value, using linear interpolation.
The sliced optimal transport sampling paper also used a numerical inversion of the CDF, but they did it differently, involving gradient descent. I am happy with the results I got, so think the table is good enough.
Doing that, we get blue noise points nicely distributed on a disk, and it only took 0.73 seconds to generate.
Blue noise points on a disk are useful for a couple things. If you want to select points to sample on a disk light source (such as the sun, perhaps), you can use blue noise points to get good coverage over the sampling domain, and without aliasing problems from a low sample count. You can also take the (x,y) values of these 2D points and add a Z component with the positive value that makes it a normalized vector () and that gives you blue noise distributed cosine weighted hemispherical samples, useful for importance sampling the term in lighting calculations.
Fun fact: this projection of a density function (PDF) onto a line is actually a partial Radon transform, which is from Tomography, and relates to how we are able to make images from xrays.
Generating Points in a Square
While points in a disk are useful, we started by trying to make points in a square. To do that, we’ll need to project the area of the square down onto each 1D line, like we did the circle, and use that area to drive where the points go, to make each point have equal area of the square. This is more challenging than the circle case, because a circle is rotationally symmetric, but a square isn’t, so the function to give us evenly spaced points also has to take the projection direction into account.
We ultimately want to project the area of a rotated square onto a 1d line, and use that to give an equal amount of area to each point we distribute along that line.
My mathematically talented friend William Donnelly came up with this function (which is in squaredcdf.h in the repo). The value u should be between -0.5 and +0.5, and will return the x value of where the point should go on the line defined by direction d. The square has width of 1, and is centered at the origin, so the unrotated square corners are at (+/- 0.5, +/- 0.5). A sketch of the derivation can be found at https://blog.demofox.org/2023/12/24/deriving-the-inverse-cdf-of-a-rotated-square-projected-onto-a-line/.
inline float InverseCDF(float u, float2 d)
{
float c = std::max(std::abs(d.x), std::abs(d.y));
float s = std::min(std::abs(d.x), std::abs(d.y));
if (2 * c * std::abs(u) < c - s)
{
return c * u;
}
else
{
float t = 0.5f * (c + s) - sqrtf(2.0f * s * c * (0.5f - std::abs(u)));
return (u < 0) ? -t : t;
}
}
If we use that to space the points along each line, again doing a batch size of 64, and doing 1000 batches, we end up with this, which took 0.89 seconds to generate.
The first image is the starting state, the 2nd and 3rd are the ending states, and last is the DFT to show the characteristic looking blue noise spectrum with a dark circle in the center of suppressed low frequencies.
Regarding the third image, if you think through what’s happening with random projections, and distributing points according to those 1D projections, there is nothing explicitly keeping the points in the square. It’s surprising to me they stay in there so well. The third image shows how well they are constrained to that square.
The blue noise points don’t look that great though. There are some bent line type patterns near the edges, and especially the corners of the square. Unfortunately, these points seem to have reached a point of “overconvergence” where they start losing their randomization. You can see the same thing in the sliced optimal transport paper. One solution to this problem is to just not do as many iterations. Below is what the point set looks like after one tenth of the iterations, or 100 batches. The DFT shows stronger lower frequencies, but the visible patterns in the point sets are gone. As we’ll see further down, adjusting the batch size may also help.
Comparison To Other Blue Noise Point Sets
Below are shown three types of blue noise point sets, each having 1000 points. Points are on the left, and DFT is on the right to show frequency characteristics.
Dart Throwing – Points are placed in a square going from [0,1]. Each point is generated using white noise and is accepted if the distance to any existing point is greater than 0.022. I had to tune that distance threshold by hand to make it as large as possible, but not so large that it couldn’t be solved for 1000 points. Wrap around / toroidal distance is used: (https://blog.demofox.org/2017/10/01/calculating-the-distance-between-points-in-wrap-around-toroidal-space/)
Sliced Optimal Transport aka SOT – The method in this post, using a batch size of 64, and 100 iterations.
I’d say dart throwing is the worst, with a less pronounced dark ring in the frequency domain. For the best, I think it’s a toss up between SOT and MBC. MBC suppresses more of the low frequencies, but SOT more strongly suppresses the frequencies it does suppress. We saw earlier that doing more iterations can increase the size of the dark circle in the DFT, but that it makes the point set too ordered. It may be situational which of these you want. There is a big difference between using blue noise point sets for organic looking object placement in a game, and using blue noise point sets for sparse sampling meant to then be filtered by a matching gaussian filter. The first is an artistic choice and the second is a mathematical one.
There other methods for generating blue noise point sets. “Gaussian Blue Noise” by Ahmed et al. is the state of the art, I believe: https://arxiv.org/abs/2206.07798
Algorithm parameters
A batch size of 64 is used in generating all the point sets so far. Here’s what other batch sizes look like, at 1000 iterations.
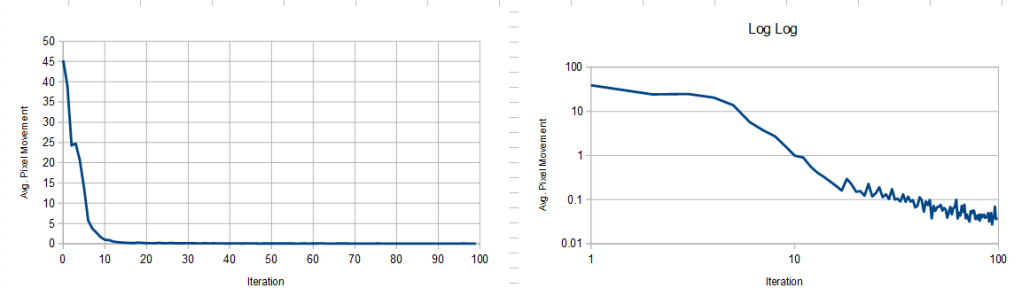
it looks like increasing batch may also be a way to get rid of the regularity we saw before at a batch size of 64, after 1000 iterations. More investigation needed here, but being able to run an algorithm to completion, instead of having to stop it early at some unknown point, is a much better way to run an algorithm.
Here is a log/log convergence graph that shows average pixel movement each batch. The x axis is the total number of random lines projected, which is constant across all batch sizes. The number of iterations is increased for smaller batch sizes and decreased for larger batch sizes to give an “equal computation done” comparison. This isn’t necessarily a graph of quality though, it just shows each batch size reaching the final state, whatever quality that may be. More investigation is needed.
We’ve been using white noise for generating the random directions to project onto. What if we instead used the golden ratio low discrepancy sequence to generate pseudorandom rotations that were more evenly spaced over the circle? Below is a graph that shows that for both square and circle, 1000 iterations of a batch size of 64. The golden ratio variants move slightly less, and move less erratically, but the difference seems pretty small.
I can’t tell much of a difference in the disk points:
And the square points look real similar too. The DFT does seem smoother for the golden ratio points though, and the light circle around the dark center seems to be less lumpy. This might be worth looking into more later on, but it seems like a minor improvement.
I think it could also be interesting to try starting with a stratified point set, or a low discrepancy point set, instead of white noise, before running the SOT algorithm. That might help find a better minimum, or find it faster, by starting with a point set that was already pretty well evenly spaced. Perhaps more generally, this algorithm could start with any other blue noise point set generation method and refine the results, assuming that the points created were lower quality than this algorithm can provide.
Using Density Maps
Generating these sample points using sliced optimal transport involves projecting the area of where we want our points to be down onto a 1D line, and using that projected area as a PDF for where points should go to get equal amounts of that projected area.
What if instead of projecting down a shape, which projects a boolean “in shape” or “not in shape” onto the line, what if we instead used a greyscale image as a density map and projected the pixel values down onto the line to make a PDF?
I did that, projecting each pixel of a 512×512 image down onto 1000 buckets along the line, adding the pixel value into each bucket it touches, but multiplying the pixel value by how much of the bucket it takes up. The pixel values are also inverted so that bright pixels are places where dots should be less dense, because I’m doing black dots on a white background.
Below right is the image used as the density map. Below left is the starting point and below middle is the final result, using 20,000 points, 1,000 iterations and a batch size of 64. It took 50 seconds to generate, and I think it looks pretty nice! I’m amazed that doing random 1d projections of an image onto a line results in such a clean image with such sharp details.
The reason this takes so much longer to generate that the other point sets seen so far is the looping through all 512×512=262,144 pixels and projecting them down onto the 1d line for each random projection vector. I’ve heard that there are ways to make this faster by working in frequency space, but don’t know the details of that.
In game development, perhaps this could be used to place trees in a forest, where a greyscale density texture controlled the density of the trees on the map.
I haven’t ever seen it before, but you could probably use a density map with both dart throwing and Mitchell’s best candidate as well. Both of those algorithms calculate distance between points. You could get the density value for each point, convert that density to a radius value, and subtract the two radius values from the distance between the points. It would be interesting to compare their quality vs these results.
Generating Multiclass Samples
Multiclass blue noise point sets are blue noise point sets where each point belongs to a class. Each class of points should independently be blue noise, but combined combinations of classes should also be blue noise.
The “Sliced Optimal Transport Sampling” paper that this post is exploring has support for this. Every other iteration, after projecting the points onto the line and sorting them, they then make sure the classes are interleaved on that line. They show it for 2 and 3 classes with equal point counts.
If using this for placing objects on a map, you might have one class for trees, another class for bushes, and another class for boulders. However, you might not want an equal number of these objects, or equivalently, you may want more space between trees, than you want space between bushes. To do that, you’d need to have different point counts per class.
Luckily that ends up being pretty easy to do. Let’s say we have three classes with weights 1, 4 and 16. Those sum up to 21. When generating your random points, you can use the point index to calculate which class it is:
int class = 2;
if (index % 21 == 0)
class = 0;
else if (index % 21 < 5)
class = 1;
Then, when doing the “interleave” step that is done every other iteration, after sorting the points, we make sure that there is a class 0, then four class 1s, then sixteen class 2s, repeating that pattern over and over.
Doing that in a square, with 1000 points, 1000 iterations, and a batch size of 64 gives us this, which took 0.57 seconds to generate. Click the image to see it full sized in another window. The top row shows the classes as colors RGB. The middle shows the combined point set, and bottom shows the DFT.
This works just fine with density maps too, generating this in 49 seconds:
Optimal Transport
Generating multi class and uneven density blue noise point sets works well using sliced optimal transport, but where is the actual optimal transport of this, and what exactly is being transported?
Going back to the last post’s explanation of optimal transport being about finding which bakeries should deliver to which cafe’s to minimize the total distance traveled, the initial point sets are the bakeries, and instead of there being discrete cafe’s, the PDF / density maps define a fuzzy “general desire for baked goods in an area”.
The optimal transport here is finding where to deliver baked goods to most evenly match demand for baked goods, and doing so, such that the sum of the distance traveled by all baked goods is minimized.
When we run the sliced optimal transport algorithm, we do eventually end up with the points being in the “optimal transport” position at the end, but the path that the points traveled to get there are not the optimal transport solution.
The optimal transport solution is the line from the initial point locations to their ending locations. That optimal transport solution will be a straight line, while the path the points took in SEARCH of the optimal transport solution may not be straight lines.
Below is the evolution of 20,000 points as they search for the optimal transport solution, over 100 iterations, with a batch size of 64. The points are not taking the path of optimal transport, the points are searching for their final position for the optimal transport solution.
Below is an animation that interpolates from the starting point set, to the ending point set, over the same amount of time (100 frames). This is the points taking the path of the optimal transport solution!
Closing
The paper which introduced dart throwing was “Stochastic sampling in computer graphics”, Cook 1986. That paper explains how in human eyes and some animals, the fovea (the place where vision is the sharpest) places photoreceptors in a hexagonal packing. This is interesting because a hexagonal grid is more evenly distributed than a regular grid, which has diagonal distances 50% longer than cardinal distances. Outside of the fovea, where the photoreceptors are sparser, a blue noise pattern is used, which is known to be roughly evenly spaced, but randomized which avoids aliasing.
To me, this is nature giving us a hint for how to do sampling or rendering. For best quality and higher sample counts, a hex grid (or more generally, a uniform grid) is best, and for lower / sparser sample counts, blue noise is best.
I hope you enjoyed this. Next up will be a post looking more deeply at an interesting 2022 paper “Scalable multi-class sampling via filtered sliced optimal transport” (https://www.iliyan.com/publications/ScalableMultiClassSampling). That paper is what convinced me I needed to learn optimal transport, and is what led to this series of blog posts.
I tried deriving this a few times, but kept getting a PDF that was more complex than I’d like. It turned out my mathematically inclined friend, and frequent co-author William Donnelly (such as in https://www.ea.com/seed/news/constant-time-stateless-shuffling), had already worked this out previously, so he shared how he did it, which I explain below more as a sketch than a proof. Treat the code as the source of truth here 🙂
The PDF
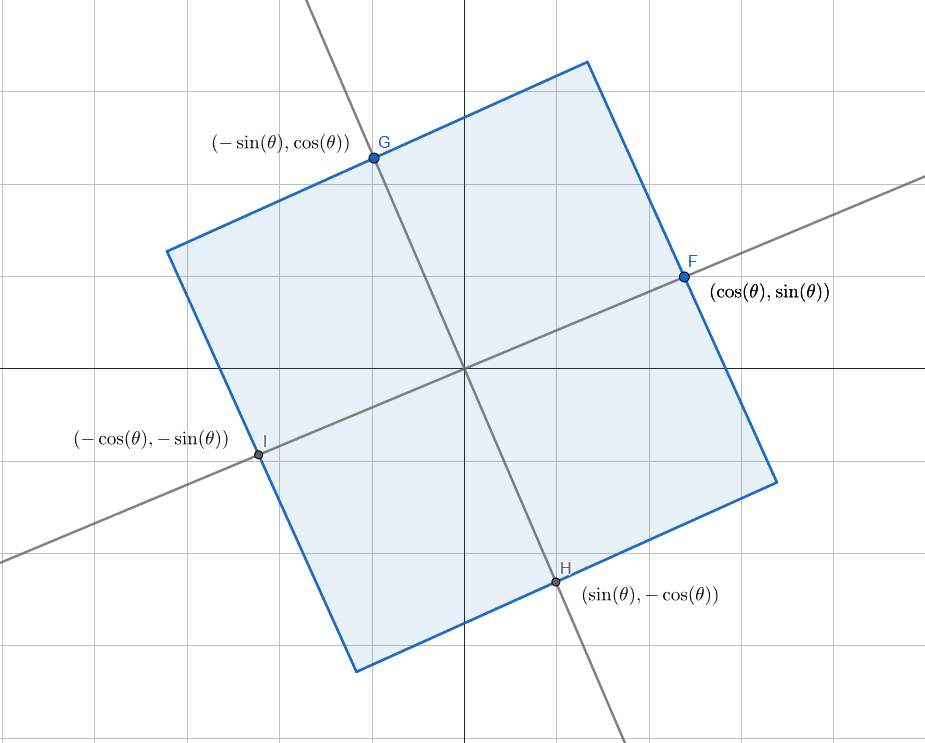
Let’s start out with a square centered at (0,0) with a width and height of 1.
Now we rotate it. This is 25 degrees, but the specific angle doesn’t matter.
We want to find the height of the shaded region at a given point x. For now we’ll stick to the right half of the rotated square. In the diagram below, we are trying to find the length of the line segment EF. This is also the hypotenuse of the right triangle EFG.
The definition of cosine of theta is that it’s “adjacent over hypotenuse”, or the length of EG over the length of EF. We know that the length of EG is 1 because that is the height of the square, so we have:
We can re-arrange that to get:
Theta () is the angle that our square is rotated by.
That is our formula for the height of the rotated square at a point x, and it is a constant value from x=0 to the x value of P.
The value of P before rotation is (0.5, 0.5). The 2d rotation formula is:
So, the x value of P after rotation is . This is the point at which our height equation needs to change to a different formula.
While we are rotating points, we can also rotate the point Q (0.5, -0.5) and get an x value of .
That x value of Q is where our projected height goes to 0, and at the x value of P, we know the projected height is . We also know that the area is a linear function (it’s the top line minus the bottom line). So, to get the 2nd part of our height function, we are trying to find the formula of the second between P and Q below:
We know that the distance from P to Q on the x axis is the x axis point of Q minus the x axis point of P.
We know the height already because it’s the same as the distance for AD, so the slope of the line from P to Q is rise over run, or:
instead of making a formula from P and subtracting the slope, we can instead subtract x from the maximum value x can take, and multiple the slope in. We know that Q is 0, so that is our formula:
We now have a piecewise height function, for the right side of the x axis, for a rotated square:
The sines and cosines make the formula look complex, but f your equation is passed the normalized vector that the points are being projected onto, the x axis is cosine of theta and the y axis is the sine of theta. That is point F below.
Due to vertical and horizontal symmetry of the rotated square, we can take the absolute value of that vector’s components to bring it to the 1st quadrant. We can go further and set cosine to the maximum of x and y, and sine to the minimum of x and y, and bring the solution to 0 to 45 degrees.
Doing that, our height function handles all possible angles. Also, because the area of our square is 1 – it is centered at (0,0) with a width and height of 1 – our height function is a normalized PDF!
The CDF
Next we need to integrate the PDF into a CDF. The first section of the piecewise PDF is constant so when integrated will become linear. The second section is linear so will become quadratic.
That gives us:
Will has the CDF’s values centered at 0, so subtracts the second case from 0.5 and returns the negated version of it if x < 0, else returns the positive version.
The Inverse CDF
The linear section of the CDF is easy enough to invert:
We need to know what y value switches from this linear section to the quadratic section though. For that, we can plug the maximum value of that PDF section into that section of the PDF to get that y value.
So, we have the first section of our inverse CDF. For the second half, I’ll wave my hands here a bit and give the answer. Keep in mind, this is for a “CDF” with y values ranging between -0.5 and 0.5. You can shift the result if you need a more traditional CDF.
The Code
It’s on github, but also pasted here in case that link is dead in the future for some reason.
// Derived By William Donnelly
struct float2
{
float x, y;
};
// The square is centered at (0,0) and has width and height of 1.
// So, the square is (x,y) in (-0.5,0.5)^2
// The CDF / ICDF are then shiften to be between -0.5 and 0.5, instead of being from 0 to 1.
namespace Square
{
inline float InverseCDF(float u, float2 d)
{
float c = std::max(std::abs(d.x), std::abs(d.y));
float s = std::min(std::abs(d.x), std::abs(d.y));
if (2 * c * std::abs(u) < c - s)
{
return c * u;
}
else
{
float t = 0.5f * (c + s) - sqrtf(2.0f * s * c * (0.5f - std::abs(u)));
return (u < 0) ? -t : t;
}
}
inline float CDF(float x, float2 d)
{
float c = std::max(std::abs(d.x), std::abs(d.y));
float s = std::min(std::abs(d.x), std::abs(d.y));
if (std::abs(x) > 0.5 * (c + s))
{
return (x < 0.0f) ? -0.5f : 0.5f;
}
else if (std::abs(x) < 0.5f * (c - s))
{
return x / c;
}
else
{
float fromEnd = (0.5f * (c + s) - std::abs(x));
float u = 0.5f - 0.5f * fromEnd * fromEnd / (c * s);
return (x < 0.0f) ? -u : u;
}
}
inline float PDF(float x, float2 d)
{
float c = std::max(std::abs(d.x), std::abs(d.y));
float s = std::min(std::abs(d.x), std::abs(d.y));
if (abs(x) < 0.5f * (c - s))
{
return 1 / c;
}
else if (abs(x) < 0.5f * (c + s))
{
float fromEnd = (0.5f * (c + s) - std::abs(x));
return fromEnd / (c * s);
}
else
{
return 0.0f;
}
}
};
This post goes through a common exercise in applying optimal transport to graphics, using informal language and simple, standalone C++ to implement it. The post uses sliced optimal transport which compared to standard optimal transport solvers is more intuitive, more efficient, and makes for a simpler implementation.
The code that goes with this post is ~300 lines of c++ code that uses STB for image reading and writing, but is otherwise standalone, and can be found at https://github.com/Atrix256/SOTImageColors.
Optimal Transport
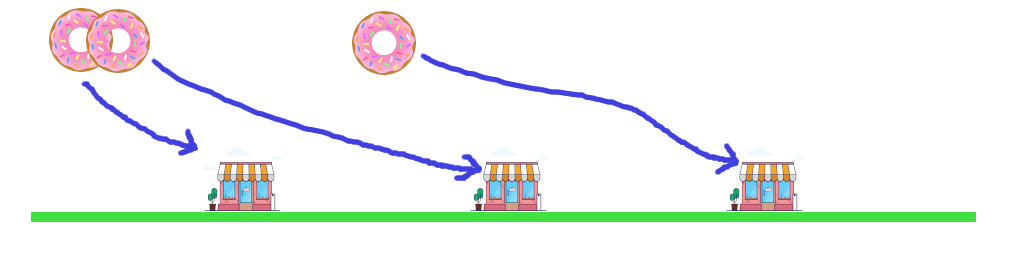
The diagram below shows a number of doughnuts at 3 bakeries, that need to go to 5 cafes. The supply (blue numbers) equals the demand (green numbers), for 13 doughnuts total that need to be transported from bakeries to cafes.
Optimal transport is the answer to the question “How many baked goods should each bakery send to each restaurant to minimize the delivery distance (cost)?”.
The problem becomes a lot simpler in 1 dimension though. You sort the bakeries by x, and the cafes by x, then assign deliveries by matching index. The first bakery delivers to the first cafe, the second bakery delivers to the second cafe and so on.
In this diagram, each bakery only has 1 doughnut, and each cafe only wants 1 doughnut. To make a bakery have more than 1 doughnut, you would just duplicate the bakery to make N in the same location, for the N doughnuts produced. To make a cafe want more than 1 doughnut, you would similarly duplicate the cafe to make M in the same location, for the M doughnuts required. The algorithm is the same and is solved by just sorting both lists!
Sliced Optimal Transport
Sliced optimal transport is a magical algorithm that it lets you solve higher dimensional optimal transport problems by solving several one dimensional optimal transport problems instead.
More specifically, you generate a uniform random unit vector, project your source and target data onto that vector using dot product, and sort, which makes the points equally spaced along the line.
Doing that once isn’t going to be enough to solve for the optimal transport, so you do that several times with different uniform random vectors, in a batch, and keep an average of the full N dimensional vector that each projection moved each point. At the end of the batch, you move the source towards the destination by that amount.
Doing one batch isn’t going to be enough to solve for the optimal transport either, so you do several batches, until it converges to an answer.
The number of vector projections per batch, and the number of batches, are hyperparameters that you need to tune for your particular optimal transport problem. You could also set up heuristics, like ending the program when the total amount of movement was below a certain threshold.
If you sat down to implement this, you might wonder how to generate an N dimensional uniform random unit vector, where N is any number of dimensions. Luckily there is a really nice and simple way. You generate an N dimensional vector using a normal distribution for each vector component, then normalize it! std::normal_distribution is your friend, in C++.
Interpolating Color Image Histograms
The goal of this post is to have one image take the colors of another image, which you may know as “Color Grading” if you work in games or graphics.
How does this relate to optimal transport, and our bakeries and cafes?
Each pixel in our source image is a bakery with one doughnut. The RGB value of the pixel is the location of that bakery in a 3D space, if we treat RGB as XYZ for a 3 dimensional vector.
Each pixel in the image we want to take the colors of is a cafe that wants one doughnut. The RGB value of the pixel is the location of that cafe in a 3D space as well.
Our goal is to move each source image pixel RGB value (each doughnut) to a target color image pixel RGB value (a cafe). In the end, there will only be the colors from the target color image.
We could just do this randomly, and set each source color image pixel to a randomly selected target color image pixel, but the source image would look like random noise.
If we do this using optimal transport instead, it means that we assign target color image pixel colors to source image pixels such that we’ve modified the source image pixels the least. That means the relationship between pixels will largely stay the same and we will end up with something that still looks like our source image, but uses only the colors from the target color image.
Note: the source image and the target color image need to be the same size, so that the number of doughnuts available from the bakeries match the number of doughnuts desired at the cafes.
Algorithmic Details
I didn’t spend very long tuning the batch size and number of iterations, but I found good results with a batch size of 16 and 100 iterations.
The sorting is the bottleneck by far, but I found that each batch could be done in parallel, which helped performance a lot on my machine.
The images I used were 792×516 and I am able to calculate optimal transport for color histograms in about 16 seconds on my machine.
I had the algorithm spit out the average movement per pixel to a csv after every step, with the assumption that smaller steps mean it is closer to convergence. Below is the graph of “big cat”, but the other two were very similar.
Images
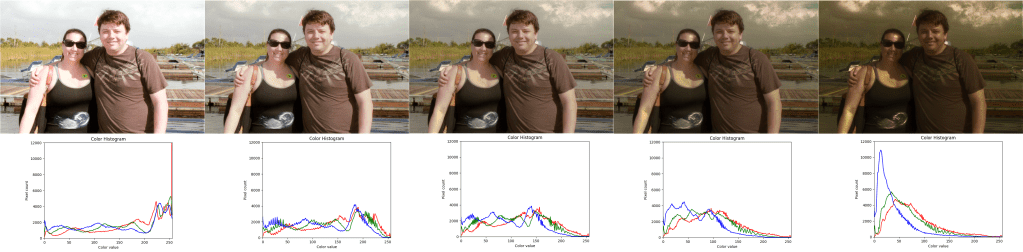
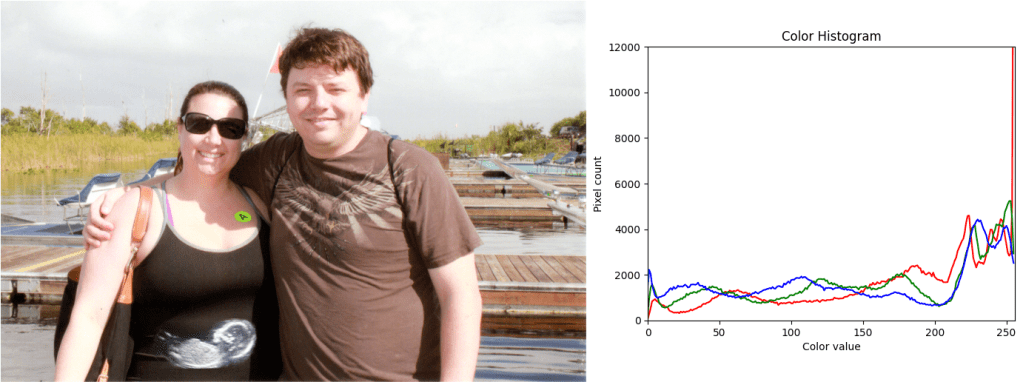
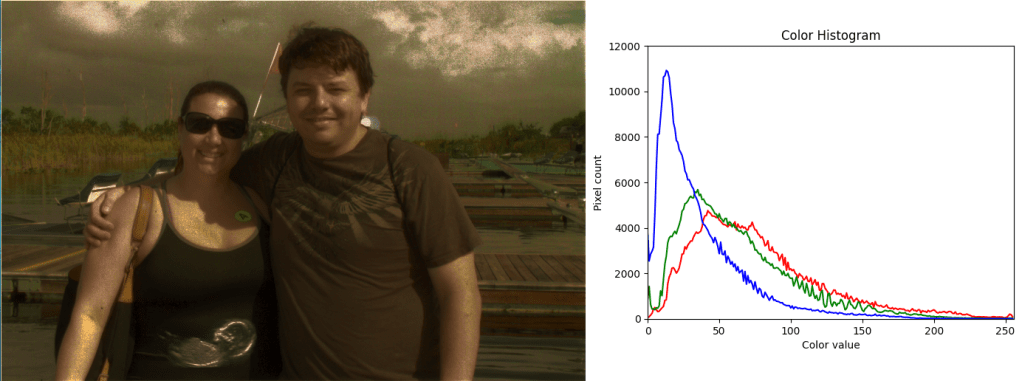
Here is the source image I used (florida), and it’s histogram.
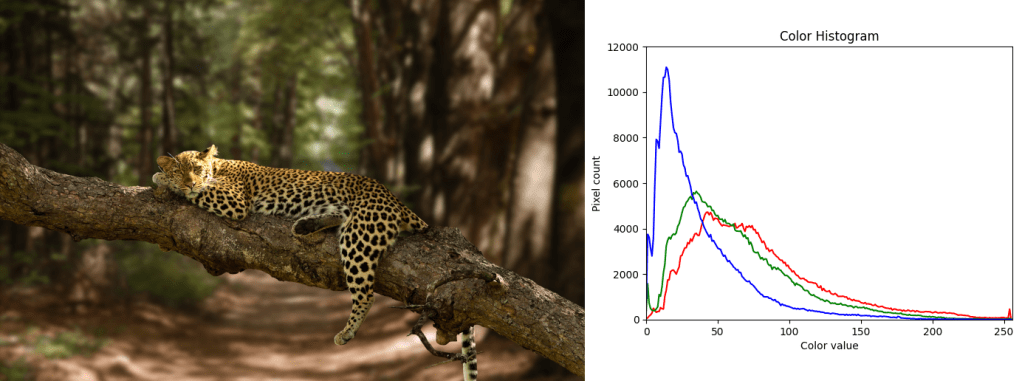
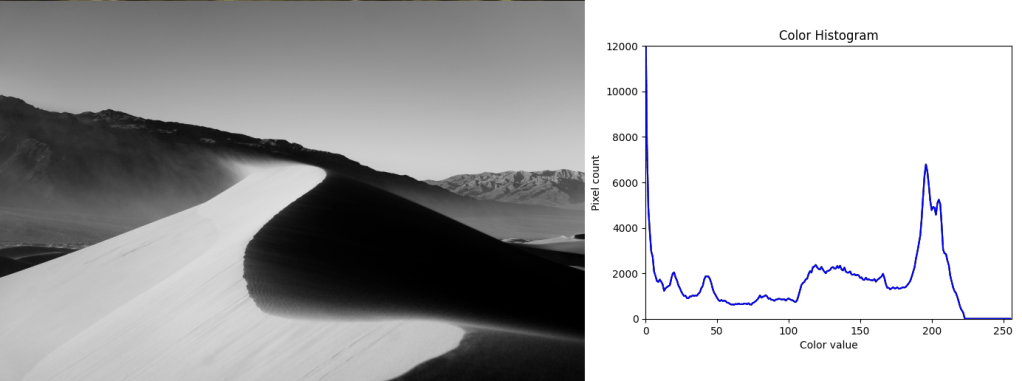
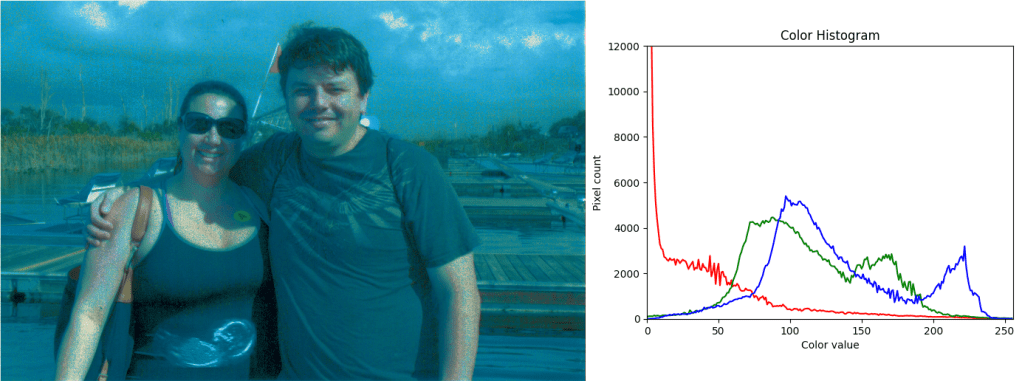
Here are the 3 images i used as targets, along with their histograms: bigcat, dunes, turtle.
Results
Florida remapped to big cat
Florida remapped to dunes
Florida remapped to turtle
If you compare the histograms closely, you’ll see that while they are not a 100% match, they are extremely close. Below shows the difference between the big cat histogram and the florida remapped to big cat histogram.
This is also noticeable in the dunes result, where the histogram shows that the colors are not all perfectly grey. An easy way to compare is to open one of the source image/histograms in the last section in one browser tab, and the corresponding result below in another tab, and flip back and forth.
Interpolation
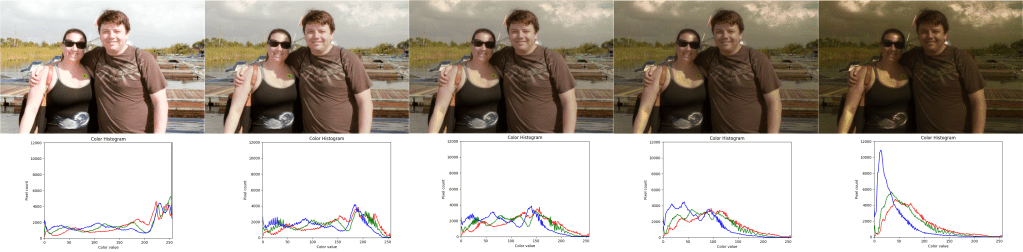
Solving the optimal transport problem tells you where to move each source image pixel to make the color histogram match a target. Instead of moving the pixels all the way in the RGB 3d cube to the correct location, you can move the pixels part of the way there, thus interpolating the source image histogram to the target image histogram. Below shows an interpolation from florida to big cat, at 0%, 25%, 50%, 75% and then 100%.
When you interpolate from A to B by 25%, you are really doing barycentric interpolation along a line (a 1D simplex) with barycentric coordinates (u,v) = (0.75, 0.25). To get the result, you are multiplying the original image by 0.75, the target image by 0.25, and adding the results together.
Barycentric interpolation generalizes to any dimension. In 2D, you get three barycentric coordinates and are interpolating on a triangle.
Also, while barycentric coordinates are meant for doing interpolation, but having all coordinates sum up to 1, and all be between 0 and 1, you can break those assumptions. When a coordinate is less than 0 or greater than 1, then you are doing barycentric extrapolation. You could do the same here, if you for instance just wanted a photo to be LESS like another photo, as far as the color histogram was concerned.
I’ll leave that to you to experiment with though, if that sounds interesting 🙂
Lastly, the code uses white noise uniform random lines to project onto. White noise is good “at the limit” but for smaller numbers of samples, it tends to clump up and leave holes. I’m betting that using a low discrepancy sequence to generate the lines would give better results that converge faster. I’m leaving that as a teaser for you again, but also think I will give that a try in the future.
The 1990s! They felt like a wasteland of culture at the time, but looking back, there was hyper color t-shirts, the beginning of mainstream computing and the internet, the height of alternative rock, and of course magic eye pictures.
Unfocus your eyes such that the two dots overlap. A 3D image should emerge!
Quick PSA if you can’t see it!
To make an autostereogram, you need two things: 1. Color Image: A tileable repeating pattern. This can also just be “white noise”. 2. Depth Image: A grey scale depth map, or a black and white mask. This defines the 3D shape. Brighter pixel values are closer in depth.
For the above, I snagged these two from pintrest.
The image you are making is going to be the width and height of the depth image, but is going to have as many color channels as the color image.
You build the output image row by row, from left to right. To start out, we can just tile the output image with the color image. The Output Image pixel at (x,y) is the Color Image pixel at (x % ColorWidth, y % ColorHeight). That makes a tiled image, which does not have any 3d effect whatsoever:
To get a 3D effect we need to modify our algorithm. We need to read the Depth Image at pixel (x,y) to get a value from 0 to 255. We divide that by 255 to get a fractional value between 0 and 1. We then multiply that value by the “maximum offset amount”, which is a tuneable parameter (i set it to 20), to get an offset amount. This offset is how much we should move ahead in the pattern.
So, instead of Output Image pixel (x,y) using the Color Image pixel (x % ColorWidth, y % ColorHeight), we are calculating an offset from the Depth Image and using the Color Image pixel ((x + offset) % ColorWidth, y % ColorHeight).
Doing that, we aren’t quite there. Some 3D effects are starting to pop out, but it doesn’t look quite right.
In fact, if you use the simpler depth map of the rectangles shown below, you can see the rectangles just fine, but there seems to be holes to the right of them.
What we need to do is not just look into the Color Image at an offset location, but that we need to look at the Output Image we are building, at an offset location. Specifically, we need to look at it in the previous color tile repetition. We use the Output Image pixel at ((x + offset – ColorWidth), y).
A problem with that though, is that when x is less than ColorWidth, we’ll be looking at a pixel x value that is less than 0 aka out of bounds. When x < ColorWidth, we should use the Color Image pixel instead, using the same formula we had before ((x + offset) % ColorWidth, y % ColorHeight).
That fixes our problem with the simpler squares depth map. The holes to the right are gone.
And it also mostly fixes our “grave” image:
There is one problem remaining with the grave image though. How these images work is that your left eye needs to lined up with an unmodified tile on the left, and your right eye needs to be lined up with a modified tile on the right. The grave image has depth information very close to the left side, which makes that not be possible. To fix this, you can add an extra “empty color tile” on the left. That makes our image a little bit wider but it makes it work. This also has the added benefit of centering the depth map, where it previously was shifted to the left a bit.
There we are, we are done!
Other Details
I found it useful to normalize the greyscale depth map. Some of them don’t use the full 0 to 1 range, which means they aren’t making the most use of the depth available. Remapping them to 0 to 1 helps that.
Some masks were meant to be binary black or white, but the images i downloaded form the internet had some grey in them (they were .jpg which is part of the problem – lossy compression). Having an option to binarize these masks was useful, forcing each pixel value or 0 or 1, whichever was closer.
The binary masks i downloaded had the part i was interested in being black, with a white background. I made the code able to invert this, so the interest part would pop out instead of receeding in.
The distance between the helper dots on the images are the width of the Color Image. A wider color image means a person has to work harder to get those dots to overlap, and it may not even be possible for some people (I’m unsure of details there hehe). I used tile sizes of 128.
It’s hard to make out fine detail from the depth maps. It seems like larger, coarse features are the way to go, instead of fine details.
More Pictures
Here is the grave, with a different color texture. I find this one harder to see.
And another, using RGB white noise (random numbers). I can see this one pretty easily, but it isn’t as fun themed as the pumpkin image 🙂
And here is greyscale white noise (random numbers) used for the color image. I can see this just fine too.
I also tried using blue noise as a Color Image but I can’t see the 3d at all, and it isn’t a mystery what the 3d image is. You can see the repetition of the depth map object from the feedback. I think it’s interesting that the repetition is needed to make it look right. I have no understanding of why that is, but if you do, please leave a comment!
Here are some images that are not the grave. I find the pumpkin color texture works pretty nicely 🙂
Lastly, I think it would be really neat to make a game that used this technique to render 3d. It could be something simple like a brick breaking game, or as complex as a first person shooter. A challenge with this is that you need to process the image from left to right, due to the feedback loop needed. That won’t be the fastest operation on the GPU, forcing it to serialize pixel processing unless anyone has any clever ideas to help that. Still, it would be pretty neat as a tech demo!
This post is also about reducing the number of experiments needed, but uses orthogonal arrays, and is based on work by Genichi Taguchi (https://en.wikipedia.org/wiki/Genichi_Taguchi).
Let’s motivate this with a tangible situation. Imagine we are trying to find the best brownie recipe and we have three binary (yes/no) parameters. The first parameter “A” determines whether or not to add an extra egg. A value of 1 in a test means to add the egg, a value of 0 means don’t add the egg. The second parameter “B” determines whether to double the butter. The third option “C” determines whether we put nots on top.
Here are the 8 combinations of options, which you may recognize as counting to 7 in binary.
A (extra egg)
B (double butter)
C (add nuts)
Test 0
0
0
0
Test 1
0
0
1
Test 2
0
1
0
Test 3
0
1
1
Test 4
1
0
0
Test 5
1
0
1
Test 6
1
1
0
Test 7
1
1
1
Now we want to reduce the number of experiments down to 4, because we only have 4 brownie pans and also don’t want to get too fat trying to figure this out. Here are the 4 experiments we are going to do, along with a “result” column where we had our friends come over and rate the brownies from 1-10, and we took the average for each version of the recipe.
A
B
C
Result
Test 0
0
0
0
8
Test 1
0
1
1
6
Test 2
1
0
1
9
Test 3
1
1
0
7
At first glance the tests done seem arbitrary, and the results seem to not give us much information, but there is hidden structure here. Let’s highlight option A being false as bold, and true as being left alone.
A
B
C
Result
Test 0
0
0
0
8
Test 1
0
1
1
6
Test 2
1
0
1
9
Test 3
1
1
0
7
If you notice, we are doing two tests for A being false, and in those two tests, we have a version where B is true, and a version where B is false. The same is true for C; it’s true in one test and false in the other. This essentially makes the effects of the B and C options cancel out in these two tests, if we average the results.
Looking at the two tests for when A is true, the same thing happens. One test has B being true, the other false. One test has C being true, the other false. Once again this makes the effects of B and C cancel out, if we average the results.
Averaging the results when A is false gives us 7. Averaging the results when A is true gives us 8. This seems to indicate that adding an extra egg gives a small boost to the tastiness of our brownies. In our tests, due to the effects of B and C canceling out, we can be more confident that we really are seeing the results of the primary effect “A” (Adding an extra egg), and not some secondary or tertiary effect.
More amazingly, we can highlight the tests where B is false and see that once again, in the two tests for B being false, A and C have both possible values represented, and cancel out again. Same for when B is true.
A
B
C
Result
Test 0
0
0
0
8
Test 1
0
1
1
6
Test 2
1
0
1
9
Test 3
1
1
0
7
The same is true if we were to highlight where C is false. Every parameter is “isolated” from the others by having this property where the other parameters cancel out in the tests.
Let’s make a table showing the average scores for when A,B and C are false vs true.
No
Yes
A (extra egg)
7
8
B (double butter)
6.5
8.5
C (nuts on top)
7.5
7.5
From this table we can see that doubling the butter gives the biggest increase in score to our brownies. Adding another egg helps, but not as much. Lastly, people don’t seem to care whether there are nuts on top of the brownies or not.
It’s pretty neat that we were able to do this analysis and make these conclusions by only testing 4 out of the 8 possibilities, but we also have missing information still – what we called aliases in the last blog post. Software that deals with fractional factorial experiment design (there’s one called minitab) are able to show the aliasing structure of these “Taguchi Orthogonal Arrays”, but I wasn’t able to find how to calculate what the aliases are exactly. If someone figures that out, leave a comment!
I just spilled the beans, in that the table of tests to do is called an “Orthogonal Array”. More specifically it’s an orthogonal array of strength 2.
For an orthogonal array of strength 2, you can take any 2 columns, and find all possible combinations of the parameter values an equal number of times. Here is the testing table again, along with the values of “AB”, “AC”, and “BC” to show how they each have all possible values (00, 01, 10, 11) exactly once.
A
B
C
AB
AC
BC
Test 0
0
0
0
00
00
00
Test 1
0
1
1
01
01
11
Test 2
1
0
1
10
11
01
Test 3
1
1
0
11
10
10
Orthogonal arrays give this isolation / cancellation property that allows you to do a reduced number of tests, and still make well founded conclusions from the results.
A higher strength orthogonal array means that a larger number of columns can be taken, and the same will be true. This table isn’t a strength 3 orthogonal array, because it is missing some values. The full factorial test on these three binary parameters would be a strength 3 orthogonal array, which gives better results, but is full factorial, so doesn’t save us any time.
Unlike the last blog post, parameters don’t have to be limited to binary (2 level) values with these arrays. We could turn parameter A (add an extra egg) into something that had three values: 0 = regular amount of eggs, 1 = an extra egg, 2 = two extra eggs.
The full factorial number of tests would then become 12 instead of 8:
A (3 level)
B (2 level)
C (2 level)
Test 0
0
0
0
Test 1
0
0
1
Test 2
0
1
0
Test 3
0
1
1
Test 4
1
0
0
Test 5
1
0
1
Test 6
1
1
0
Test 7
1
1
1
Test 8
2
0
0
Test 9
2
0
1
Test 10
2
1
0
Test 11
2
1
1
Unfortunately in this case, there is no strength 2 orthogonal array that is smaller than the full 12 tests. The reason for this is because an orthogonal array needs pairs of columns to have an equal number of each possible value, for that pairs of columns. The column pairs of AB and AC both have 6 values, while the column pair BC has 4 values. If we did only 4 tests, the AB and AC column pairs would be missing 2 out of the 6 possible values. If we did 6 tests, the column pair BC would have 2 extra values, which can also be seen as missing 2 values to make it have all values twice.
To formalize this, the minimum number of tests you can do is the least common multiple of the column pair value combinations. In this example again, AB and AC have 6, while BC has 4. The least common multiple between 6 and 4 is 12. So, you need to do a multiple of 12 experiments with this setup to make an orthogonal array. The full factorial array is size 12, and in fact is the orthogonal array that we are talking about.
If you add another 2 level factor (binary parameter), the minimum number of experiments stays at 12, but the full factorial becomes 24, so we are able to beat the full factorial in that case.
A (3 level)
B (2 level)
C (2 level)
D (2 level)
Test 0
0
0
0
1
Test 1
0
0
1
0
Test 2
0
1
0
1
Test 3
0
1
1
0
Test 4
1
0
0
1
Test 5
1
0
1
0
Test 6
1
1
0
0
Test 7
1
1
1
1
Test 8
2
0
0
0
Test 9
2
0
1
1
Test 10
2
1
0
0
Test 11
2
1
1
1
Robustness Against Uncontrolled Variables
I’ve only read a little about Taguchi but what I have read has really impressed me. One thing that really stood out to me is nearly a social issue. Taguchi believed making precise results was the correct ultimate goal of a factory. He believed erratic and low quality results affected the consumer and the company, and demonstrated how both ultimately affected the company. From wikipedia:
Taguchi has made a very influential contribution to industrial statistics. Key elements of his quality philosophy include the following:
Taguchi loss function, used to measure financial loss to society resulting from poor quality;
The philosophy of off-line quality control, designing products and processes so that they are insensitive (“robust”) to parameters outside the design engineer’s control.
Innovations in the statistical design of experiments, notably the use of an outer array for factors that are uncontrollable in real life, but are systematically varied in the experiment.
I’d like to highlight his work in making processes robust against uncontrolled variables.
What you do is run the tests when the uncontrolled variable is a certain way, then when it’s another way, you run the tests again. You might do this several times.
Then, for each combination of settings you do have control over, you take the standard deviation for when the uncontrolled variable varies. Whichever combination of controllable settings gives you the lowest standard deviation (square root of variance), means that setting of variables is least affected by the uncontrolled variable.
It may not be the BEST result, but it lets you have a CONSISTENT result, in uncontrollable conditions. Sometimes consistency is more important than getting the best score possible. FPS in a video game is an example of this. A smooth frame rate feels and appears a lot better perceptually than a faster, but erratic frame rate.
Note that you can use this technique with CONTROLLABLE variables too, to see if there are any variables that don’t have a strong impact on the result. You can use this knowledge to your advantage by removing it from future tests as a variable for example.
Here is another example of where that could be useful. Imagine you were making a video game, and you provided the end user with a set of graphics options to help them control the game’s performance on their machine. If you run tests of different performance, for different graphics settings, on different machines, you might find that certain settings don’t help performance much AT ALL for your specific game. If this is the case, you can remove the graphics setting from the UI, and set it to a constant value. Simplifying the settings helps you the developer, by having fewer code paths to maintain, it helps QA by having fewer code paths to test, and it helps the user, by only presenting meaningful graphics options.
An Algorithm For Orthogonal Array Generation
I couldn’t find a singular orthogonal array generation algorithm on the net. From what I read, there are different ways of constructing different types of orthogonal arrays, but no generalized one. However, it’s easy enough to craft a “greedy algorithm with backtracking” algorithm, and I did just that. The source code can be found at https://github.com/Atrix256/OrthogonalArray.
Let’s think of the orthogonal array as a matrix where each row is an experiment, and each column lists the values for a parameter across all of the experiments. The goal we are after is to have each column pair have each possible value show up once.
Assuming that all columns have the same number of possible values for a moment (like, they are all binary and can either have a 0 or 1), we can see that when filling up any single column pair with options, we will also fill up all of the other column pairs. As a concrete example, if we have 3 binary columns A,B,C, we know that by filling AB with all the values 00, 01, 10, 11 by choosing experiments from the “full factorial list”, that there will also be four values in the columns AC and BC. So, we only need to find 4 rows (specific experiments) in that case. We can just fill up the first column pair, and the other column pairs will get filled up too.
We can do this by choosing any experiment that has 00 in AB, then 01, 10, and finally 11.
However, the values that fill up the other columns may not end up in the full set of values, and there may be repeats, even if we disallow repeats of specific experiments.. Column AC may end up being 00, 00, 11, 10 for instance which has 00 showing up twice, and 01 doesn’t show up at all.
So, when we choose an experiment (row) to use that matches the value we want from the AB column, we also have to make sure it isn’t a duplicate value in any of the other columns.
Doing this, we may end up in a spot where we have values left to fill in, but none of our options are valid. At this point, we take a step back, remove the last row we added, and try a new one. This is the backtracking. We may have to backtrack several steps before we find the right solution. We may also exhaustively try all solutions and find no solution at all!
Generalizing this further, our columns may not all have the same number of possible values – like in our examples where we mixed 3 level and 2 level variables. As I mentioned before, some column pairs will have 6 possible values, while others will have 4 possible values. The only way you can make an orthogonal array in that situation is by making a number of rows that are a multiple of the least common multiple of 6 and 4, which is 12. The 6 value column pairs will have all values twice, and the 4 value column pairs will have each value three times.
Lastly, there are situations where no solution can be found by repeating the values this minimal number of times, but if you do twice as many (or more), a solution can be found, and still be smaller than the full factorial set of experiments. An example of this is if you have five 3 level factors. You cant make an orthogonal array that is only 9 rows long, but you can make one that is 18 rows long. That is still a lot smaller than the full factorial number of experiments which is 3^5 or 243 experiments.
Closing and Links
From the number of reads of the previous blog post, this seems to be a topic that really resonates with people. Who doesn’t want to do less work and still get great results? (Tangent: That is also the main value of blue noise in real time rendering!)
In these two posts, we’ve only scratched the surface. Apparently there is still researching coming out about this family of techniques – doing a smaller number of tests and gleaming the most relevant data you can from them.
When starting on this journey, I thought it must surely have applications to sampling in monte carlo integration, and indeed it does! There is a paper from 2019 i saw, but didn’t understand at the time, which uses orthogonal arrays for sampling (https://cs.dartmouth.edu/~wjarosz/publications/jarosz19orthogonal.html).
The rabbit hole has become quite deep, so I think I’m going to stop here for now. If you have more to contribute here, please leave a comment! Thanks for reading!
Have you ever found yourself in a situation where you had a bunch of parameters to tune for a better result, but there were just too many to exhaustively search all possibilities?
I recently saw a video that talked about how to reduce the number of experiments in these situations, such that it formalizes what conclusions you can and cannot make from those experiments. Even better, the number of experiments can be a sliding scale to either be fewer experiments (faster), or more information from the results (higher quality).
We are going to explore a method for doing that in this post, but you should also give the video a watch before or after reading, as it talks about a different method than we will! https://www.youtube.com/watch?v=5oULEuOoRd0
Fractional Factorial Design Terminology
The term “fractional factorial” is in contrast to the term “full factorial”.
To have some solid context, let’s pretend that we want to figure out how to make the best brownies, and we have 3 options A, B, C. Option “A” may be “add an extra egg”, “B” may be “double the butter” and “C” may be “put nuts on top”, where 1 means do it, and -1 means don’t do it.
Three parameters with two choices each means we have 8 possibilities total:
A
B
C
Test 0
-1
-1
-1
Test 1
-1
-1
1
Test 2
-1
1
-1
Test 3
-1
1
1
Test 4
1
-1
-1
Test 5
1
-1
1
Test 6
1
1
-1
Test 7
1
1
1
We’ve essentially counted in binary, doing all 8 tests for all 8 possibilities of the three binary parameters.
If you’ve noticed that the number of tests are 2^3, and not a factorial, you are correct. The term “factorial” refers to “factors” which is another name for a parameter. We have 3 factors in our experiment to make the best brownies.
Each factor has two possible values. In the literature, the number of values a parameter can take is called a level. So, our brownie experiment has 3 two level factors.
If we didn’t have enough pans to bake all 8 types of brownies, we may instead opt to do a smaller amount. We may only do 1/2 of the tests for instance, which means that we would be doing a fractional amount of the full factorial experiment. We’d be doing a fractional factorial experiment. We could even do 1/4 of the experiments. The fewer experiments we do, the less information we get.
Choosing which four experiments to do, and knowing what conclusions we can draw form the results is where the magic happens.
Fractional Factorial Design
Going back to our brownie recipe, let’s say that we want to do 4 bakes, instead of 8.
We start by making a full experiment table for A and B, but leave C blank
A
B
C
Test 0
-1
-1
Test 1
-1
1
Test 2
1
-1
Test 3
1
1
We now have to decide on a formula for how to set C’s value, based on the value of A and B. This is called a generator and to test things out, lets set C to the same value as A, so our generator for C is “C = A”
A
B
C=A
Test 0
-1
-1
-1
Test 1
-1
1
-1
Test 2
1
-1
1
Test 3
1
1
1
We have 4 experiments to do now, instead of 8, but it isn’t obvious what information we can get from the results. Luckily some algebra can help us sort that out. This algebra is a bit weird in that any letter squared becomes “I”, or identity. Our ultimate goal is to find the “Aliasing Structure” of our experiments, which is made up of “words”. Words are combinations of the parameter letters, as well as identity “I”. The aliasing structure lets you use algebra to find what testing parameters alias with other testing parameters. An alias means you can’t tell one from the other, with the limited number of tests you’ve done.
That is quite a lot of explaining, so lets actually do these things.
First up we have C = A. If we multiply both sides by C we get CC = AC. Any value multiplied by itself is identity, so we get I = AC as a result. Believe it or not, that is our full aliasing structure and we are done! We’ll have more complex aliasing structures later but we can keep it simple for now.
Now that we have our aliasing structure, if we want to know what something is aliased by, we just multiply both sides by our query to get the result. Here’s a table to show what I mean.
Alias Query
Result
I
I = AC
A
A = AAC = C
B
B = ABC
C
C = ACC = A
AB
AB = AABC = BC
AC
AC = AACC = I
BC
BC = ABCC = AB
ABC
ABC = AABCC = B
Looking at the table above, we see that B = ABC. This means that B aliases ABC. More plainly, this means that from our experiments, if the brownies were rated from 1 to 10 for tastyness, we wouldn’t be able to tell the difference in results between only doing option B (doubling the butter) and doing all three options: adding an egg, doubling the butter, and adding nuts on top.
Another thing we can see in the table is that A = C. That means that we cannot tell the difference between adding an egg, or adding nuts on top.
Lastly, I = AC means that we can’t tell the difference between doing nothing at all, compared to adding an egg and adding nuts on top.
If we care to be able to distinguish any of these things, we’d have to change our experiment design. Specifically, we would need to change the generator for C.
We can do that, and in fact there is a better choice for a generator for C. Let’s make it so that value of C is the value of A and B multiplied together. C = AB.
A
B
C=AB
Test 0
-1
-1
1
Test 1
-1
1
-1
Test 2
1
-1
-1
Test 3
1
1
1
It doesn’t look like much has changed, but lets do the same analysis as before.
We can get our aliasing structure by starting with C=AB and multiplying both sides by C to get CC=ABC, which simplifies to I = ABC. Let’s find all of our aliases again.
Alias Query
Result
I
I = ABC
A
A = BC
B
B = AC
C
C = AB
AB
AB = C
AC
AC = B
BC
BC = A
ABC
ABC = I
Something interesting has happened with this design of experiments (D.O.E.). All of the single letters alias with double letters. This means that we can distinguish all primary effects from each other, but that primary effects are aliased (or get “confounded”) with secondary effects. In many situations, the primary effects are more prominent than secondary effects (adding butter or adding nuts is more impactful individually, than when combined). In these situations, you can assume that if there’s a big difference noticed, that it is the primary effect causing it. If there’s any doubt, you can also do more focused experiment(s) to make sure your assumptions are correct.
Resolution
So why is it that our first generator C=A wasn’t able to differentiate primary effects, while our second generator C=AB could? For such a simple example, it might be obvious when looking at C=A, but this has to do with something called “Resolution”, which is equal to the length of shortest word in the aliasing structure (not counting I).
With I=CA, that is two letters, so it is a resolution II D.O.E. Resolution II D.O.E.s have at least some primary effects aliased (or confounded) with other primary effects. Resolution II D.O.E.s are usually not very useful.
With I=ABC, that is three letters, so is a resolution III D.O.E. Resolution III D.O.E.s have primary effects aliased with secondary effects. These are more useful, as we explained above.
As you add more factors, you can get even higher resolution D.O.E.s. A resolution IV has primary effects aliased with tertiary effects, and secondary effects are aliased with each other. A resolution V has primary effects aliased with quaternary effects, and secondary effects are aliased with tertiary effects. If you are noticing the pattern that the aliasing effect classes add up to the resolution, you are correct, and that pattern holds for all resolutions.
Getting a higher resolution D.O.E. is usually better, so you want your generators to contain more letters. You have to be careful to make them unique enough though. If you had four factors A,B,C,D and generators C=AB, D=AB, you can see that you’ve introduced an alias C=D.
If you work out the aliasing structure, this problem becomes apparent that you’ve made a resolution II D.O.E. Aliasing structures always need 2^p words, where p is the number of parameters that have generators. In this case, p is 2, so you need 2^2 or 4 words in the aliasing structure.
The first word comes from C=AB, which can be rewritten as I=ABC. Actually that’s the first two words.
The second word comes from D=AB, which can be rewritten as I=ABD. That gives us three words:
I = ABC = ABD
To get the fourth word, we can see that both ABC and ABD are equal to each other. Remembering that when we multiply the same thing against itself we get identity, we can make our fourth word by multiplying them together to get something equal to identity for our aliasing structure.
ABC*ABD = AABBCD = CD.
So, our four words all together are:
I = ABC = ABD = CD
Since “CD” is the shortest word that is not identity, and is 2 letters, we can conclude that we have a resolution II D.O.E.
We can multiply the aliasing structure by C to get all the things that C is aliased with.
C = AB = ABCD = D
This shows we cannot tell the difference between C and D, because they are aliased, or confounded, and confirms that we have a resolution II D.O.E.
What’s With The Weird Algebra?
When we said C=AB, where A and B were either -1 or +1 in each column, it was pretty easy to just multiply the values together to get the result.
What probably made less sense is when working with the generators and aliasing structures, why a letter times itself would become identity. The reason for this is that the multiplication is a component wise vector product. If the original value was -1, then we get -1*-1 or +1. If the original value was +1, then we get 1*1 or +1. The result of a component wise vector product between a vector and itself will have a 1 in every component, which is identity.
To help cement these ideas, we’ll do one more example with 8 experiment and 5 factors. That means we’ll only do 1/4 of the experiments we would if doing the full factorial, doing 8 experiments instead of 32.
8 experiments mean that the first three factors will be full factorial, and the last two parameters will need generators. We’ll use D = AB and E=BC as our generators.
We can make our experiment table to start.
A
B
C
D=AB
E=BC
Test 0
-1
-1
-1
1
1
Test 1
-1
-1
1
1
-1
Test 2
-1
1
-1
-1
-1
Test 3
-1
1
1
-1
1
Test 4
1
-1
-1
-1
1
Test 5
1
-1
1
-1
-1
Test 6
1
1
-1
1
-1
Test 7
1
1
1
1
1
Let’s also make our aliasing structure. Since we are using generators on 2 parameters, that means p=2, and so we have 2^p = 2^2 = 4 words in our aliasing structure. The first 3 are easy, since they come from our generators directly.
D = AB : I = ABD E = BC : I = BCE so: I = ABD = BCE
For the fourth word, we again know that ABD and BCE are equal since they are both equal to identity. We also know that multiplying anything by itself is identity, so we can multiply them together to get the fourth word:
ABD*BCE = ABBCDE = ACDE
Our full aliasing structure is then the below, which shows that we have a resolution III D.O.E, meaning primary effects are only aliased with secondary effects.
I = ABD = BCE = ACDE
Lastly, let’s make the full 32 entry table showing all aliases to understand the things we can, and cannot differentiate from our experiment results.
Alias Query
Result
I
I = ABD = BCE = ACDE
A
A = BD = ABCE = CDE
B
B = AD = CE = ABCDE
C
C = ABCD = BE = ADE
D
D = AB = BCDE = ACE
E
E = ABDE = BC = ACD
AB
AB = D = ACE = BCDE
AC
AC = BCD = ABE = DE
AD
AD = B = ABCDE = CE
AE
AE = BDE = ABC = CD
BC
BC = ACD = E = ABDE
BD
BD = A = CDE = ABCE
BE
BE = ADE = C = ABCD
CD
CD = ABC = BDE = AE
CE
CE = ABCDE = B = AD
DE
DE = ABE = BCD = AC
ABC
ABC = CD = AE = BDE
ABD
ABD = I = ACDE = BCE
ABE
ABE = DE = AC = BCD
ACD
ACD = BC = ABDE = E
ACE
ACE = BCDE = AB = D
ADE
ADE = BE = ABCD = C
BCD
BCD = AC = DE = ABE
BCE
BCE = ACDE = I = ABD
BDE
BDE = AE = CD = ABC
CDE
CDE = ABCE = BD = A
ABCD
ABCD = C = ADE = BE
ABCE
ABCE = CDE = A = BDE
ABDE
ABDE = E = ACD = BC
ACDE
ACDE = BCE = ABD = I
BCDE
BCDE = ACE = D = AB
ABCDE
ABCDE = CE = AD = B
Closing
A limitation you may have noticed in this article is that it only works with binary parameters (2 level factors). Part 2 of this blog post will show how to overcome that limitation using a different technique for fractional factorial experimental design.
Until then, there is a way to extend this method to factors which have a multiple of 4 levels. If you are interested in that, google Plackett-Burman.


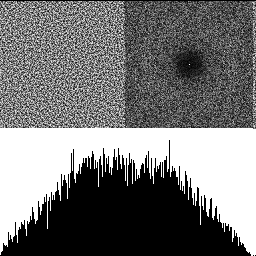
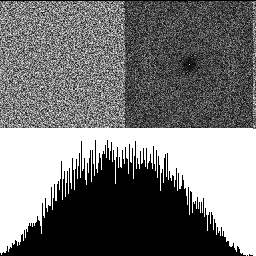
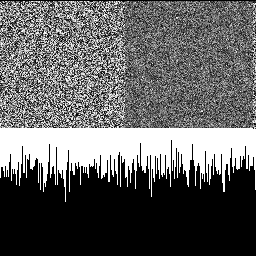
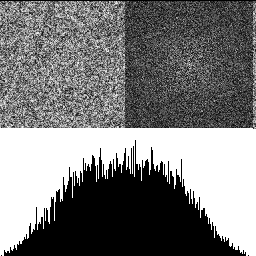

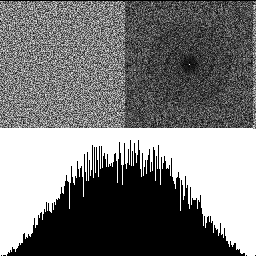

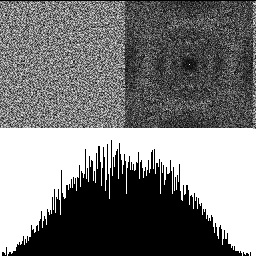

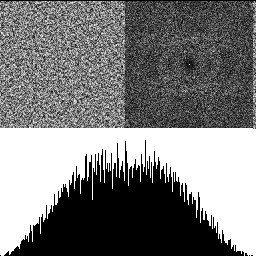
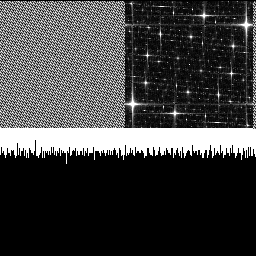
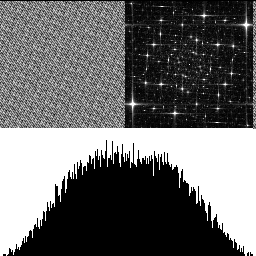
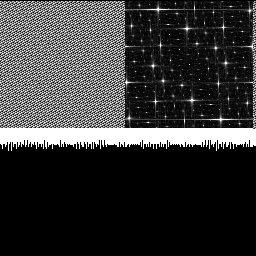
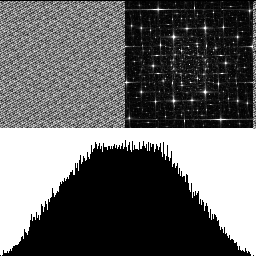
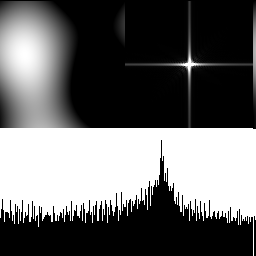
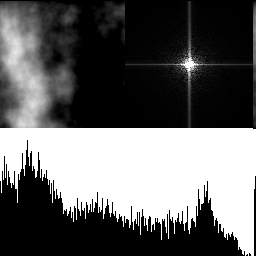
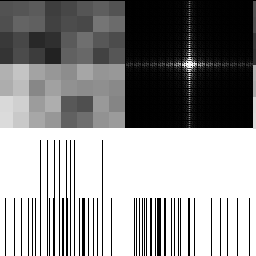
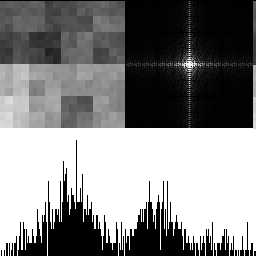
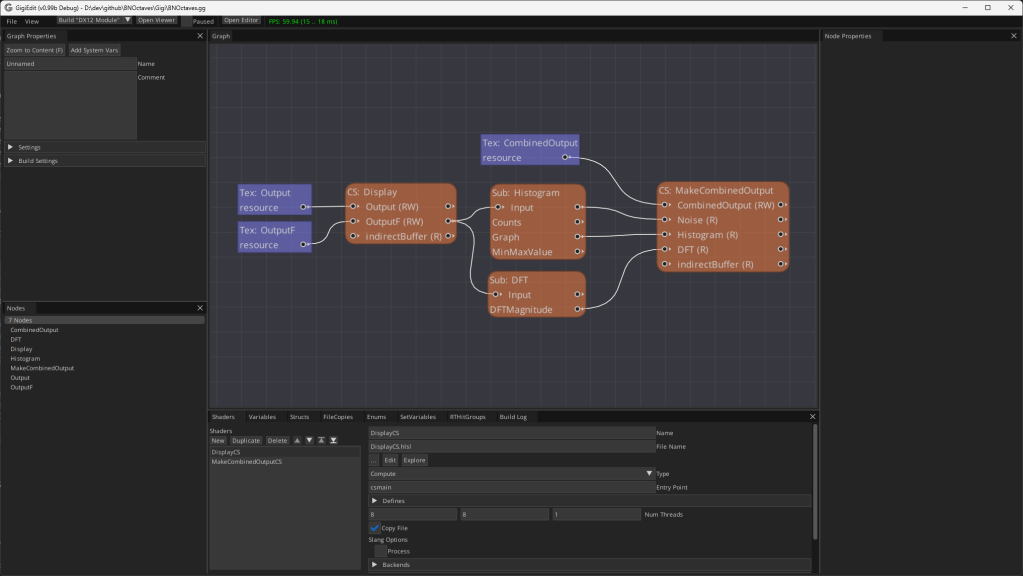
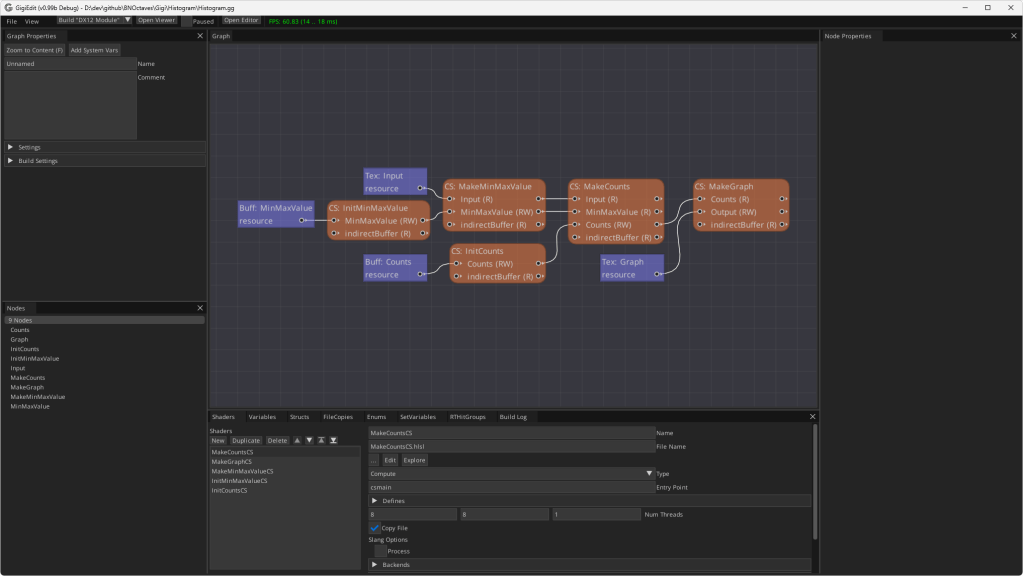
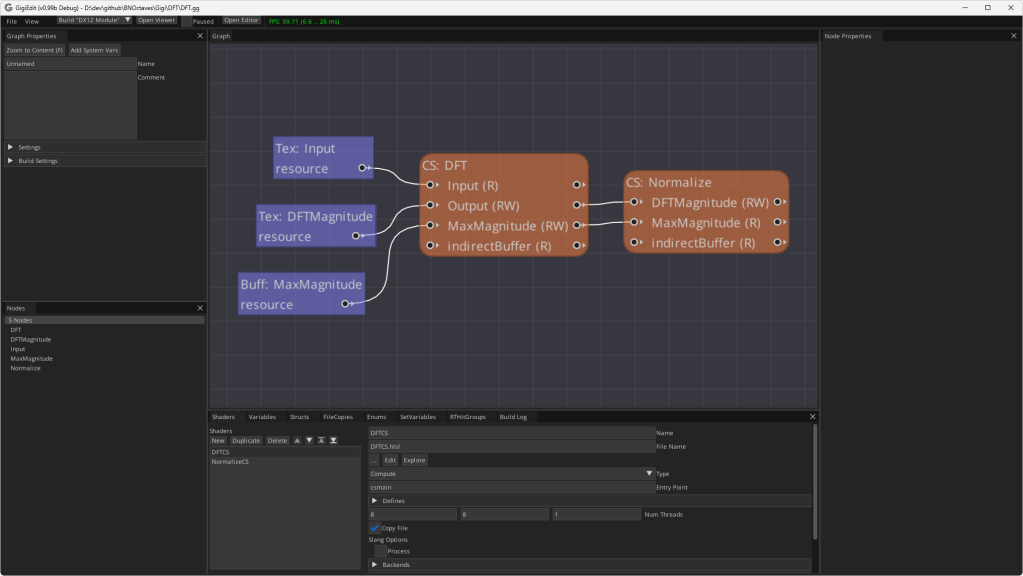
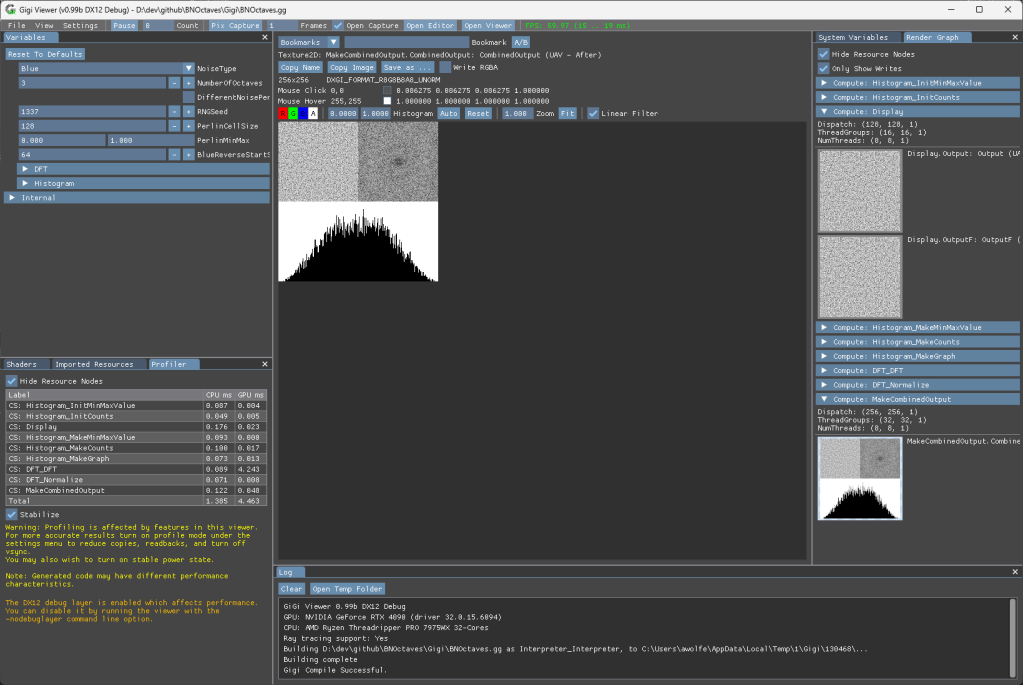
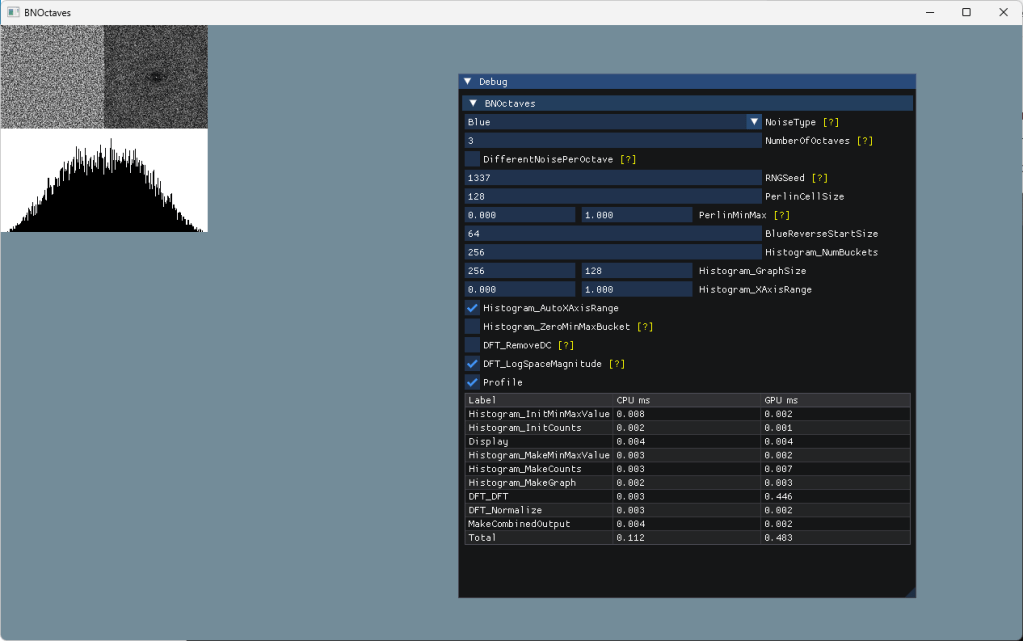




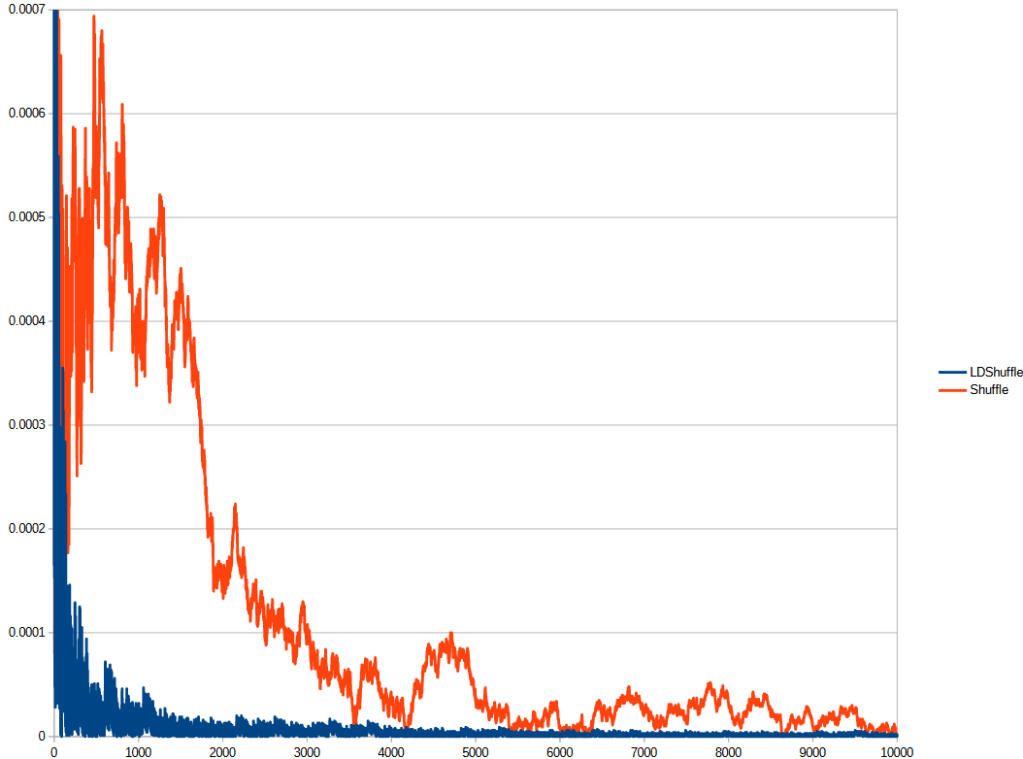
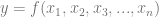

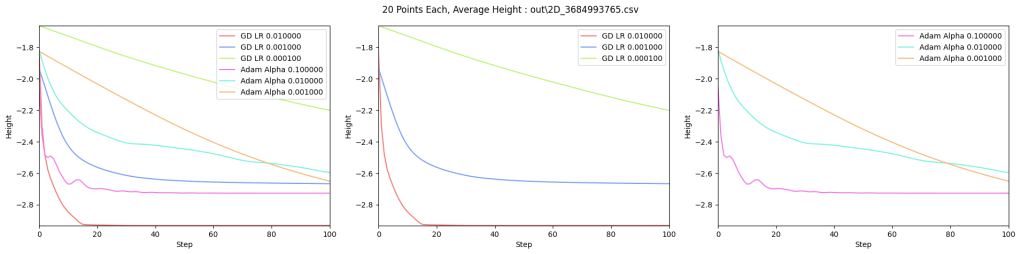
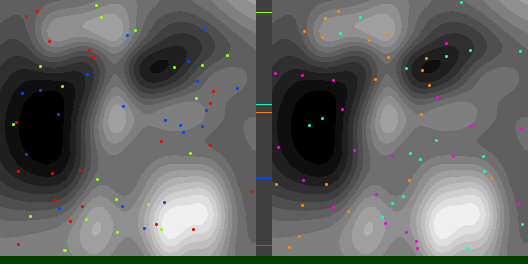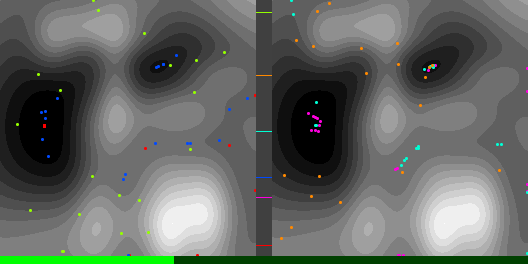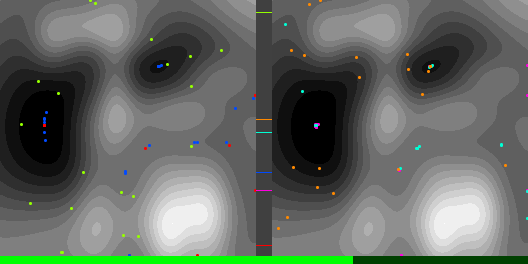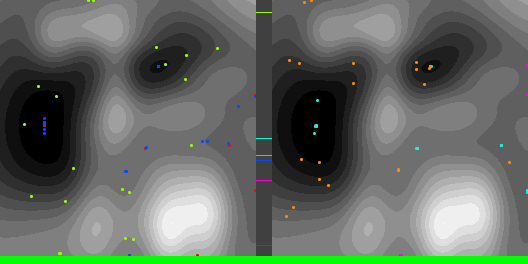
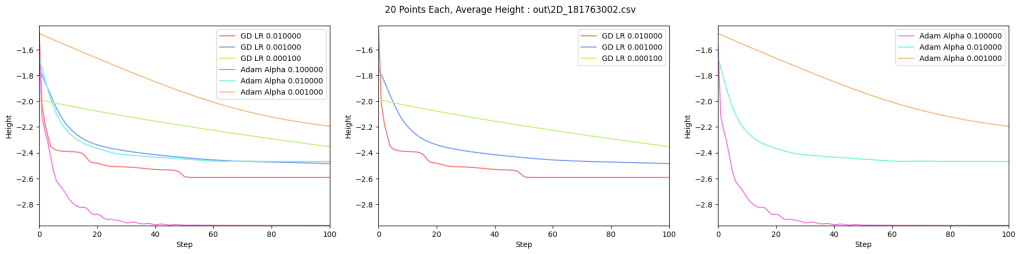
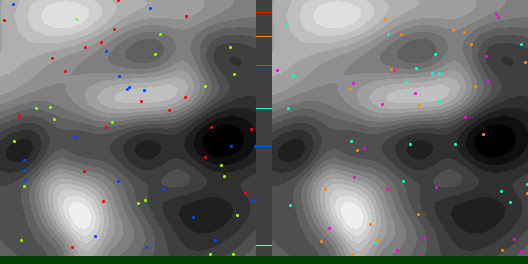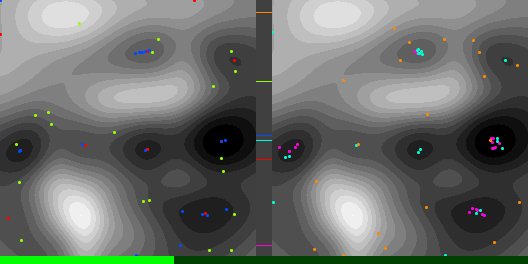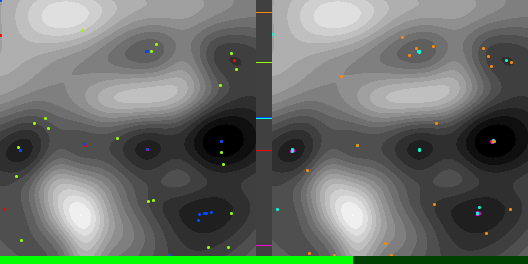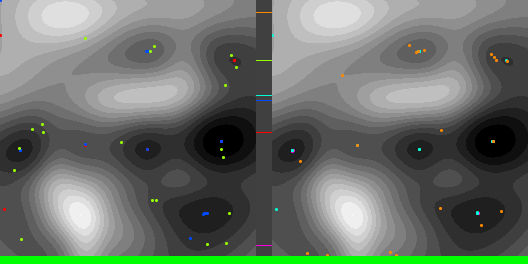
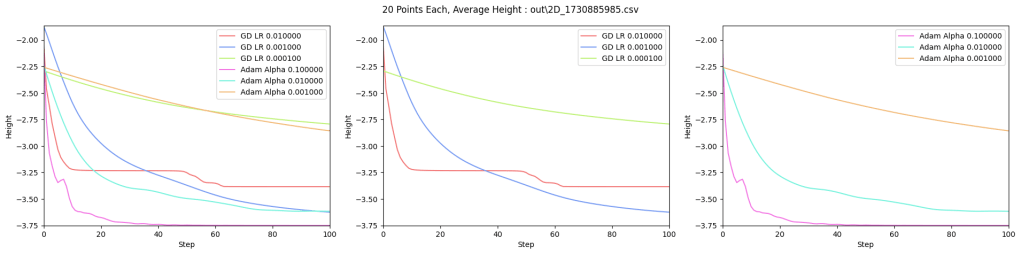
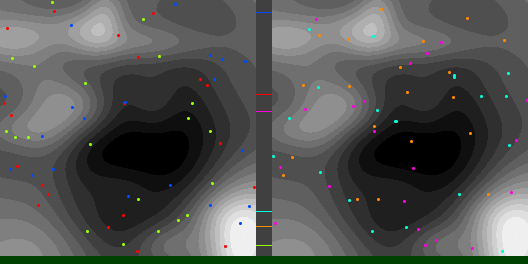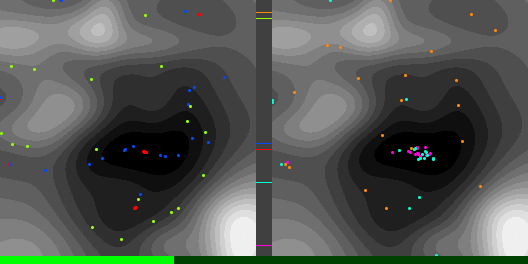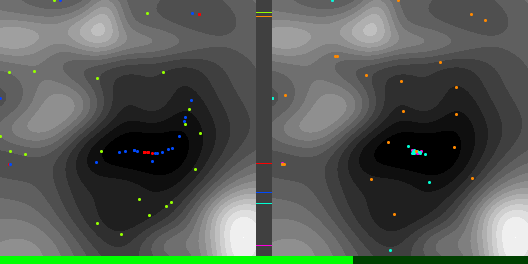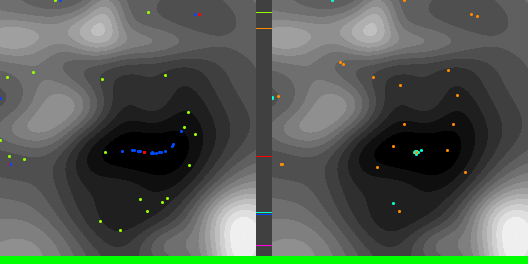



 . That only gives us the top half of the disk height, but we can double it to get the bottom half as well:
. That only gives us the top half of the disk height, but we can double it to get the bottom half as well:  .
.
 . Dividing that by the area of the disk, we get
. Dividing that by the area of the disk, we get 

 ) and that gives you blue noise distributed cosine weighted hemispherical samples, useful for importance sampling the
) and that gives you blue noise distributed cosine weighted hemispherical samples, useful for importance sampling the  term in lighting calculations.
term in lighting calculations.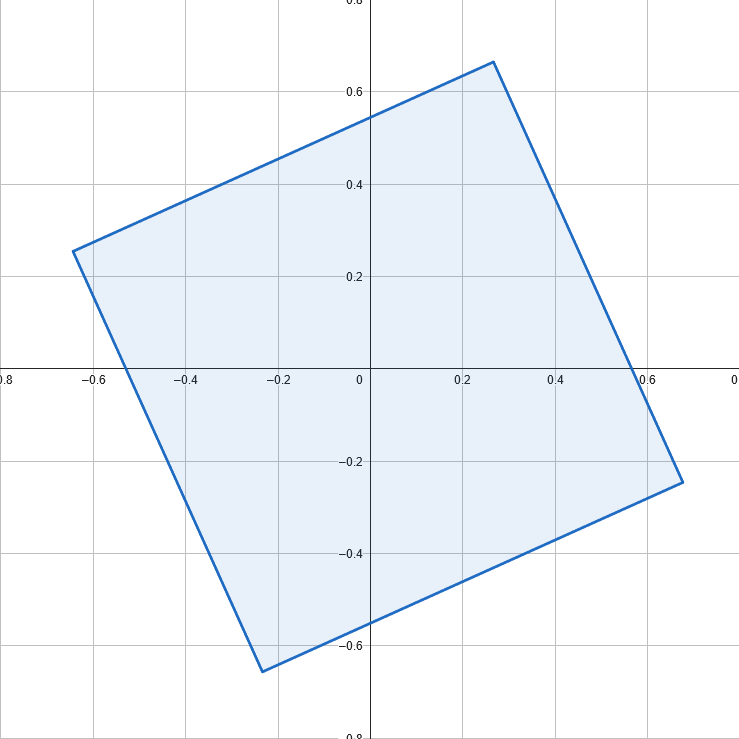




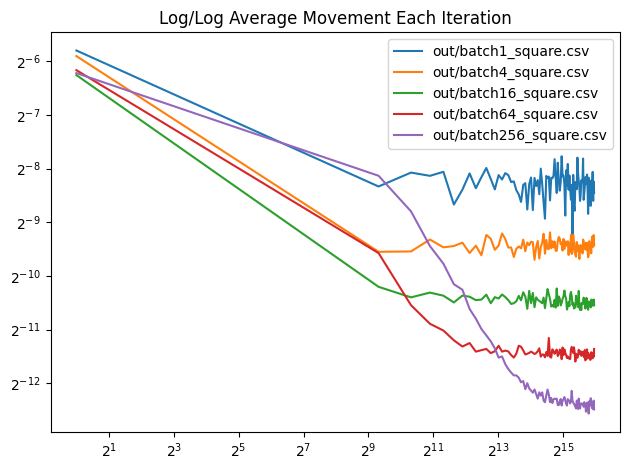
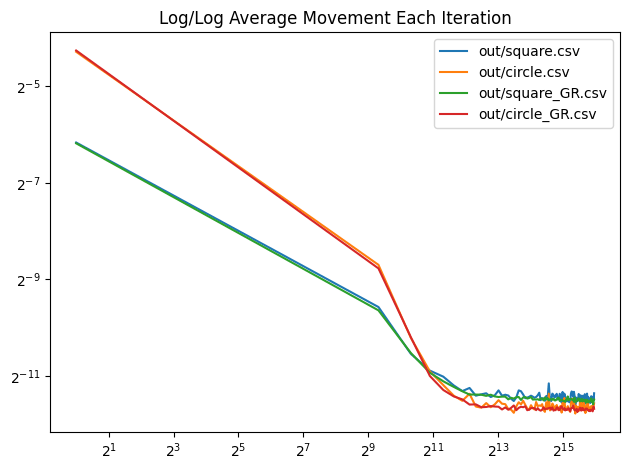











 ) is the angle that our square is rotated by.
) is the angle that our square is rotated by.
 . This is the point at which our height equation needs to change to a different formula.
. This is the point at which our height equation needs to change to a different formula. .
. . We also know that the area is a linear function (it’s the top line minus the bottom line). So, to get the 2nd part of our height function, we are trying to find the formula of the second between P and Q below:
. We also know that the area is a linear function (it’s the top line minus the bottom line). So, to get the 2nd part of our height function, we are trying to find the formula of the second between P and Q below: