
The last post showed a super simple encryption algorithm that let an untrusted person perform calculations with encrypted data such that when they gave the results back to you, you could decrypt them and get the results of the calculation as if they were done on the unencrypted values. The best part was that this untrusted party had no knowledge of the data it was doing the calculations on.
While it was (hopefully) easy to understand, there were a lot of problems with it’s security. The biggest of which probably was the fact that the encryption of a false bit was the secret key itself!
This post is going to slightly increase the complexity of the encryption operation to match what the paper that I’m getting this stuff from says to do (Fully Homomorphic Encryption over the Integers).
All of the other operations – like XOR, AND, Decryption, use of constants – remain the same. It’s just the process of turning a plain text bit into a cipher text bit that is going to change.
Disclaimer: I am a game programmer, not a cryptographer, and you should REALLY do your own investigation and consult experts before actually rolling anything out to production or trusting that what I say is correct!
Improvement #1 – Multiply Key By Random Number
The scheme to encrypt a plaintext bit from the last blog post was this:
encryptedBit = key + value ? 1 : 0;
A major problem with that scheme is that if you encrypt a false bit, you get the key itself.
Another problem that we touched on was that the parity of the plain text bit (whether it was odd or even, aka a 1 or a 0) was always opposite of the parity of the cipher text.
Yet another problem was that for the same key, 0 always encrypted to the same value, and 1 always encrypted to the same value, which was the “0” encrypted value, plus 1.
We are going to address all of these problems by adding a simple operation to encryption. We are just going to multiply the key by a random number before adding the plain text bit in. That gives us the following:
encryptedBit = key*randomNumber + value ? 1 : 0;
Where randomNumber is at least 1.
This above helps in the following ways:
- Encrypting false doesn’t always just give you the key anymore!
- Since the cipherBit divided by the key is now a random number (and since the key is an odd number), it will be random whether the parity of the cipher text matches or mismatches the plain text. You can no longer use that information to figure out the value of the encrypted bit!
- If you encrypt a false value, you will get different values each time. Same when encrypting a true value. When looking at two ciphertexts that have the same underlying plaintext value, you will no longer be able to tell that they are equal just by looking at them, or be able to tell that one is larger than the other so must be the true bit!
That is a pretty good improvement, but we can do a little better.
Improvement #2 – Add Random Noise
The second improvement we are going to do is add random noise to our encrypted value. This will make it so encrypting a false bit will not result in a multiple of the key, but will instead result in NEARLY a multiple of the key, which is a harder problem to figure out as an attacker.
You might ask how we are going to preserve our encrypted value if we are adding random noise into the result. Well, in actuality, all we really need to preserve is the lowest bit, so we are going to add an EVEN NUMBERED amount of noise.
That makes our encryption scheme become this:
encryptedBit = key*randomNumber1 + 2*randomNumber2 + value ? 1 : 0;
While this increases our security, it also increases the noise (error) in our encrypted data, which makes it so we can do fewer operations before the error gets too large and we start getting wrong answers.
There we are, our encryption scheme now matches the one described in the paper. All the rest of our operations remain unchanged.
Security
The above looks good, but what range of values should be we use for randomNumber1 and randomNumber2 and the actual size of the key?
The paper refers to a security parameter lambda (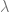
It says that the size of the key (N) should be (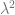




It also says that the best known attack against this algorithm takes about 
Let’s look at some example values for lambda!
| Lambda | Key Size | RN1 Size | RN2 Size | Attack Time |
| 80 | 800B | 30.5GB | 10B | 38 million years |
| 60 | 450B | 5.4GB | 8B | 36 years |
| 40 | 200B | 488MB | 5B | 17 minutes |
| 20 | 50B | 7.6MB | 3B | < 1 second |
Ouch! RandomNumber1 sure is huge isn’t it? I’ve double and tripple checked and that really does seem to be correct. Encrypting a single bit is essentially going to be as large as RandomNumber1. That is so unwieldy it’s ridiculous. I’m going to quadruple check that I think because that is just insane…
BTW quick tangent. An interesting thing to note is that if your key is an even number, instead of an odd number, noise/error can grow as much as it wants, and will never give you the wrong result! That means that by using an even numbered key, this scheme is fully homomorphic. However, using an even key, encryptedBit % 2 == decryptedBit, so it’s super insecure.
I’ve been thinking about it quite a bit, but I can’t think of any avenues to use an even numbered key but still have any semblance of real security. If you can think of a way, go publish a paper about it and become famous! 😛
Example Code
Here is some sample code from last post with the new encryption routine. I had to decrease the number of bits in the addition tests, and I had to tone down the security quite a bit to make it fit within 64 bits.
#include <stdio.h>
#include <stdint.h>
#include <random>
#include <array>
#include <inttypes.h>
typedef uint64_t uint64;
// Increase this value to increase the size of the key, and also the maximum
// size of the error allowed.
// If you set it too high, operations will fail when they run out of storage space
// in the 64 bit ints. If you set it too low, you will not be able to do very many
// operations in a row.
// The recomended values for good security for these numbers are way too large to
// fit in a uint64, so adjusting them down to show their effects while using uint64s
const size_t c_numKeyBits = 15;
const size_t c_numNoiseBits = 3; //size_t(sqrt(c_numKeyBits));
const size_t c_numMultiplierBits = 4; //c_numKeyBits * c_numKeyBits * c_numKeyBits;
#define Assert(x) if (!(x)) ((int*)nullptr)[0] = 0;
//=================================================================================
// TODO: Replace with something crypto secure if desired!
uint64 RandomUint64 (uint64 min, uint64 max)
{
static std::random_device rd;
static std::mt19937 gen(rd());
std::uniform_int_distribution<uint64> dis(min, max);
return dis(gen);
}
//=================================================================================
void WaitForEnter ()
{
printf("Press Enter to quit");
fflush(stdin);
getchar();
}
//=================================================================================
uint64 GenerateKey ()
{
// Generate an odd random number in [2^(N-1), 2^N)
// N is the number of bits in our key
// The key also defines the maximum amount of error allowed, and thus the number
// of operations allowed in a row.
uint64 key = RandomUint64(0, (uint64(1) << uint64(c_numKeyBits)) - 1);
key = key | (uint64(1) << uint64(c_numKeyBits - 1));
key = key | 1;
return key;
}
//=================================================================================
bool Decrypt (uint64 key, uint64 value)
{
return ((value % key) % 2) == 1;
}
//=================================================================================
uint64 Encrypt (uint64 key, bool value)
{
uint64 keyMultiplier = RandomUint64(0, (1 << c_numMultiplierBits) - 2) + 1;
uint64 noise = RandomUint64(0, (1 << c_numNoiseBits) - 1);
uint64 ret = key * keyMultiplier + 2 * noise + (value ? 1 : 0);
Assert(Decrypt(key, ret) == value);
return ret;
}
//=================================================================================
uint64 XOR (uint64 A, uint64 B)
{
return A + B;
}
//=================================================================================
uint64 AND (uint64 A, uint64 B)
{
return A * B;
}
//=================================================================================
float GetErrorPercent (uint64 key, uint64 value)
{
// Returns what % of maximum error this value has in it. When error >= 100%
// then we have hit our limit and start getting wrong answers.
return 100.0f * float(value % key) / float(key);
}
//=================================================================================
uint64 FullAdder (uint64 A, uint64 B, uint64 &carryBit)
{
// homomorphically add the encrypted bits A and B
// return the single bit sum, and put the carry bit into carryBit
// From http://en.wikipedia.org/w/index.php?title=Adder_(electronics)&oldid=381607326#Full_adder
uint64 sumBit = XOR(XOR(A, B), carryBit);
carryBit = XOR(AND(A, B), AND(carryBit, XOR(A, B)));
return sumBit;
}
//=================================================================================
int main (int argc, char **argv)
{
// run this test a bunch to show that it works. If you get a divide by zero
// in an Assert, that means that it failed, and hopefully it's because you
// increased c_numKeyBits to be too large!
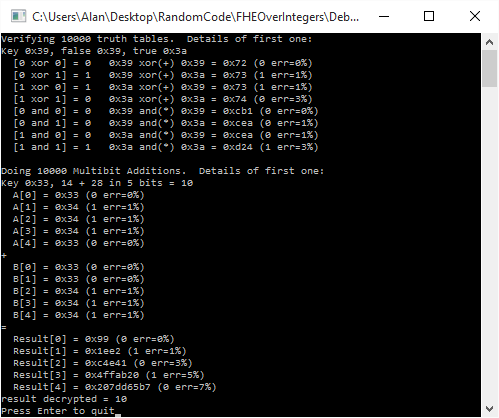
printf("Verifying 10000 truth tables. Details of first one:n");
for (int index = 0; index < 10000; ++index)
{
// make our key and a true and false bit
uint64 key = GenerateKey();
uint64 falseBit1 = Encrypt(key, false);
uint64 falseBit2 = Encrypt(key, false);
uint64 trueBit1 = Encrypt(key, true);
uint64 trueBit2 = Encrypt(key, true);
// report the results for the first iteration of the loop
if (index == 0)
{
printf("Key 0x%" PRIx64 ", false = 0x%" PRIx64 ", 0x%" PRIx64 " true = 0x%" PRIx64 " 0x%" PRIx64 "n", key, falseBit1, falseBit2, trueBit1, trueBit2);
printf(" [0 xor 0] = 0 0x%" PRIx64 " xor(+) 0x%" PRIx64 " = 0x%" PRIx64 " (%i err=%0.2f%%)n", falseBit1, falseBit2, XOR(falseBit1, falseBit2), Decrypt(key, XOR(falseBit1, falseBit2)) ? 1 : 0, GetErrorPercent(key, XOR(falseBit1, falseBit2)));
printf(" [0 xor 1] = 1 0x%" PRIx64 " xor(+) 0x%" PRIx64 " = 0x%" PRIx64 " (%i err=%0.2f%%)n", falseBit1, trueBit2 , XOR(falseBit1, trueBit2 ), Decrypt(key, XOR(falseBit1, trueBit2 )) ? 1 : 0, GetErrorPercent(key, XOR(falseBit1, trueBit2 )));
printf(" [1 xor 0] = 1 0x%" PRIx64 " xor(+) 0x%" PRIx64 " = 0x%" PRIx64 " (%i err=%0.2f%%)n", trueBit1 , falseBit2, XOR(trueBit1 , falseBit2), Decrypt(key, XOR(trueBit1 , falseBit2)) ? 1 : 0, GetErrorPercent(key, XOR(trueBit1 , falseBit2)));
printf(" [1 xor 1] = 0 0x%" PRIx64 " xor(+) 0x%" PRIx64 " = 0x%" PRIx64 " (%i err=%0.2f%%)n", trueBit1 , trueBit2 , XOR(trueBit1 , trueBit2 ), Decrypt(key, XOR(trueBit1 , trueBit2 )) ? 1 : 0, GetErrorPercent(key, XOR(trueBit1 , trueBit2 )));
printf(" [0 and 0] = 0 0x%" PRIx64 " and(*) 0x%" PRIx64 " = 0x%" PRIx64 " (%i err=%0.2f%%)n", falseBit1, falseBit2, AND(falseBit1, falseBit2), Decrypt(key, AND(falseBit1, falseBit2)) ? 1 : 0, GetErrorPercent(key, XOR(falseBit1, falseBit2)));
printf(" [0 and 1] = 0 0x%" PRIx64 " and(*) 0x%" PRIx64 " = 0x%" PRIx64 " (%i err=%0.2f%%)n", falseBit1, trueBit2 , AND(falseBit1, trueBit2 ), Decrypt(key, AND(falseBit1, trueBit2 )) ? 1 : 0, GetErrorPercent(key, XOR(falseBit1, trueBit2 )));
printf(" [1 and 0] = 0 0x%" PRIx64 " and(*) 0x%" PRIx64 " = 0x%" PRIx64 " (%i err=%0.2f%%)n", trueBit1 , falseBit2, AND(trueBit1 , falseBit2), Decrypt(key, AND(trueBit1 , falseBit2)) ? 1 : 0, GetErrorPercent(key, XOR(trueBit1 , falseBit2)));
printf(" [1 and 1] = 1 0x%" PRIx64 " and(*) 0x%" PRIx64 " = 0x%" PRIx64 " (%i err=%0.2f%%)n", trueBit1 , trueBit2 , AND(trueBit1 , trueBit2 ), Decrypt(key, AND(trueBit1 , trueBit2 )) ? 1 : 0, GetErrorPercent(key, XOR(trueBit1 , trueBit2 )));
}
// Verify truth tables for XOR and AND
Assert(Decrypt(key, XOR(falseBit1, falseBit2)) == false);
Assert(Decrypt(key, XOR(falseBit1, trueBit2 )) == true );
Assert(Decrypt(key, XOR(trueBit1 , falseBit2)) == true );
Assert(Decrypt(key, XOR(trueBit1 , trueBit2 )) == false);
Assert(Decrypt(key, AND(falseBit1, falseBit2)) == false);
Assert(Decrypt(key, AND(falseBit1, trueBit2 )) == false);
Assert(Decrypt(key, AND(trueBit1 , falseBit2)) == false);
Assert(Decrypt(key, AND(trueBit1 , trueBit2 )) == true );
}
// Do multi bit addition as an example of using compound circuits to
// do meaningful work.
const size_t c_numBitsAdded = 3;
printf("nDoing 10000 Multibit Additions. Details of first one:n");
std::array<uint64, c_numBitsAdded> numberAEncrypted;
std::array<uint64, c_numBitsAdded> numberBEncrypted;
std::array<uint64, c_numBitsAdded> resultEncrypted;
std::array<uint64, c_numBitsAdded> carryEncrypted;
for (int index = 0; index < 10000; ++index)
{
// generate the numbers we want to add
uint64 numberA = RandomUint64(0, (1 << c_numBitsAdded) - 1);
uint64 numberB = RandomUint64(0, (1 << c_numBitsAdded) - 1);
// generate our key
uint64 key = GenerateKey();
// encrypt our bits
for (int bitIndex = 0; bitIndex < c_numBitsAdded; ++bitIndex)
{
numberAEncrypted[bitIndex] = Encrypt(key, (numberA & (uint64(1) << uint64(bitIndex))) != 0);
numberBEncrypted[bitIndex] = Encrypt(key, (numberB & (uint64(1) << uint64(bitIndex))) != 0);
}
// do our multi bit addition!
// we could initialize the carry bit to 0 or the encrypted value of 0. either one works since 0 and 1
// are also poor encryptions of 0 and 1 in this scheme!
uint64 carryBit = Encrypt(key, false);
for (int bitIndex = 0; bitIndex < c_numBitsAdded; ++bitIndex)
{
carryEncrypted[bitIndex] = carryBit;
resultEncrypted[bitIndex] = FullAdder(numberAEncrypted[bitIndex], numberBEncrypted[bitIndex], carryBit);
}
// decrypt our result
uint64 resultDecrypted = 0;
for (int bitIndex = 0; bitIndex < c_numBitsAdded; ++bitIndex)
{
if (Decrypt(key, resultEncrypted[bitIndex]))
resultDecrypted |= uint64(1) << uint64(bitIndex);
}
// report the results for the first iteration of the loop
if (index == 0)
{
printf("Key 0x%" PRIx64 ", %" PRId64 " + %" PRId64 " in %i bits = %" PRId64 "n", key, numberA, numberB, c_numBitsAdded, (numberA + numberB) % (1 << c_numBitsAdded));
for (int bitIndex = 0; bitIndex < c_numBitsAdded; ++bitIndex)
printf(" A[%i] = 0x%" PRIx64 " (%i err=%0.2f%%)n", bitIndex, numberAEncrypted[bitIndex], Decrypt(key, numberAEncrypted[bitIndex]), GetErrorPercent(key, numberAEncrypted[bitIndex]));
printf("+n");
for (int bitIndex = 0; bitIndex < c_numBitsAdded; ++bitIndex)
printf(" B[%i] = 0x%" PRIx64 " (%i err=%0.2f%%)n", bitIndex, numberBEncrypted[bitIndex], Decrypt(key, numberBEncrypted[bitIndex]), GetErrorPercent(key, numberBEncrypted[bitIndex]));
printf("=n");
for (int bitIndex = 0; bitIndex < c_numBitsAdded; ++bitIndex)
printf(" Result[%i] = 0x%" PRIx64 " (%i err=%0.2f%%)n", bitIndex, resultEncrypted[bitIndex], Decrypt(key, resultEncrypted[bitIndex]), GetErrorPercent(key, resultEncrypted[bitIndex]));
printf("Carry Bits =n");
for (int bitIndex = 0; bitIndex < c_numBitsAdded; ++bitIndex)
printf(" Result[%i] = 0x%" PRIx64 " (%i err=%0.2f%%)n", bitIndex, carryEncrypted[bitIndex], Decrypt(key, carryEncrypted[bitIndex]), GetErrorPercent(key, carryEncrypted[bitIndex]));
printf("result decrypted = %" PRId64 "n", resultDecrypted);
}
// make sure that the results match, keeping in mind that the 4 bit encryption may have rolled over
Assert(resultDecrypted == ((numberA + numberB) % (1 << c_numBitsAdded)));
}
WaitForEnter();
return 0;
}
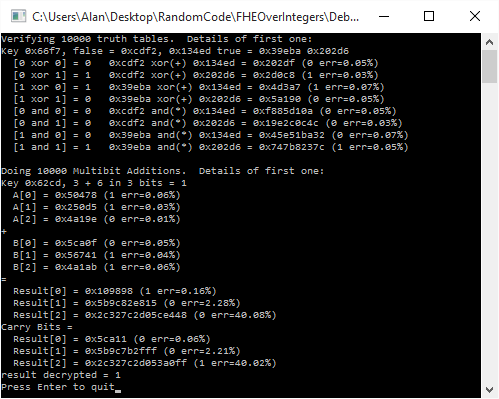
Here’s the output of an example run.
Links
Another paper about symmetric HE over the integers: Symmetric Somewhat Homomorphic Encryption over the Integers
An implementation of FHE: Implementation of the DGHV fully homomorphic encryption scheme
Next Up
Here are some interesting avenues to explore with this stuff. More blog posts coming in the future about these topics, but for now, here they are in case you want to check them out yourself:
- Making the public / private key implementation
- Make this stuff work with multi precision math to be able to make realistically sized and see what sort of perf it gives
- Show how to achieve fully homomorphic encryption using boot strapping and/or modulus switching
- Further explore tuning down security parameters to get game quality HE
- Explore the other known methods for implementing HE. HE over the integers is apparently very easy to understand compared to other methods, but other methods may have different characteristics – like maybe not being crazy gigantic









 ) – This defines how much blur there is. A larger number is a higher amount of blur.
) – This defines how much blur there is. A larger number is a higher amount of blur.

 .
. . So technically, you could use a row from Pascal’s triangle as a 1d kernel and normalize the result, but it isn’t the most accurate.
. So technically, you could use a row from Pascal’s triangle as a 1d kernel and normalize the result, but it isn’t the most accurate.





















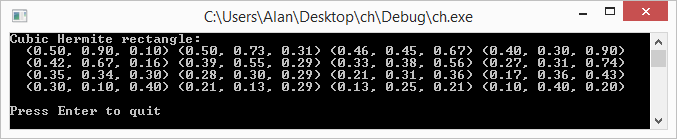
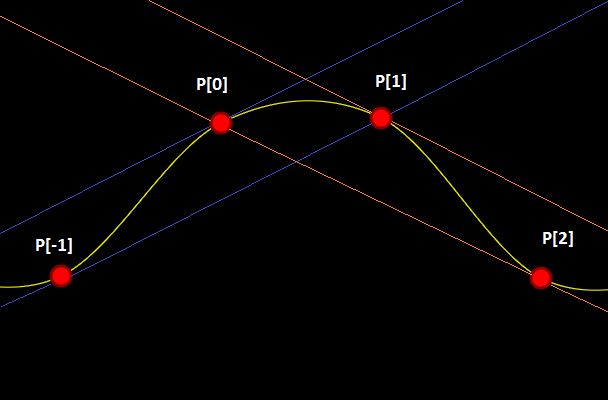
 continuity everywhere!
continuity everywhere! control points on a fixed interval, you can treat it as a bunch of piece wise cubic Hermite splines and evaluate it that way.
control points on a fixed interval, you can treat it as a bunch of piece wise cubic Hermite splines and evaluate it that way.
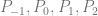 . The curve at time 0 will be at point
. The curve at time 0 will be at point 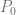 and the slope will be the same slope as a line would have if going from
and the slope will be the same slope as a line would have if going from  to
to  . The curve at time 1 will be at point
. The curve at time 1 will be at point  .
.




 are used to be able to make this interpolation
are used to be able to make this interpolation 



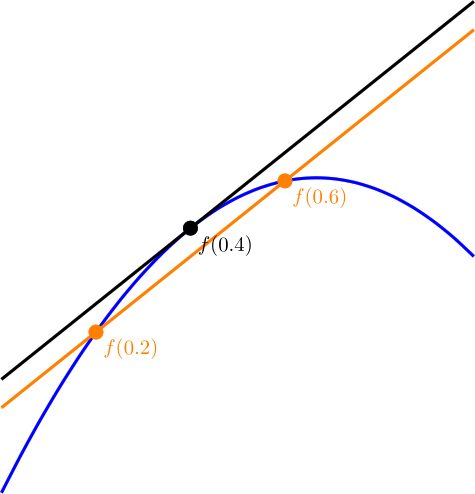
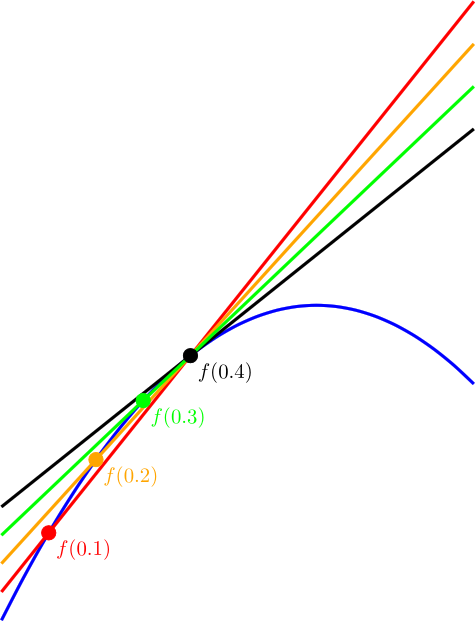
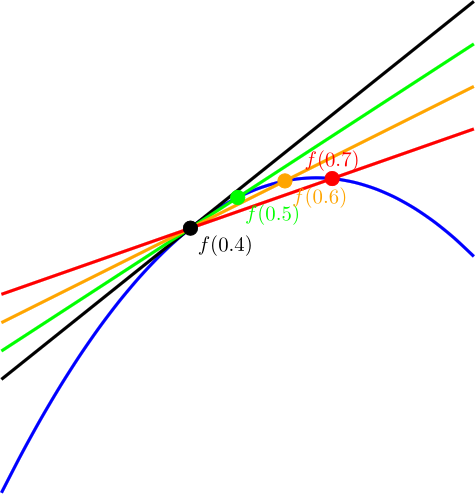
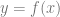 at a specific value of x, you pick an epsilon e and then you calculate both
at a specific value of x, you pick an epsilon e and then you calculate both  and
and  . You subtract the first one from the second and divide by 2*e to get an approximated slope of the function at the specific value of x.
. You subtract the first one from the second and divide by 2*e to get an approximated slope of the function at the specific value of x.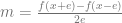
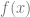 , subtracts the 1st one from the second one and divides the result by e.
, subtracts the 1st one from the second one and divides the result by e.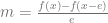
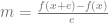





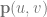 is the point on the surface that you get after you plug in the parameters.
is the point on the surface that you get after you plug in the parameters.  and
and  are the parameters to the surface and should be within the range 0 to 1. These are the same thing as the
are the parameters to the surface and should be within the range 0 to 1. These are the same thing as the 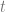 you see in Bezier curves, but there are two of them since there are two axes.
you see in Bezier curves, but there are two of them since there are two axes. go from 0 to
go from 0 to  and the other makes
and the other makes  go from 0 to
go from 0 to  .
. 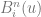 and
and 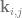 . The number of control on one axis are multiplied by the number of control points on the other axis.
. The number of control on one axis are multiplied by the number of control points on the other axis.