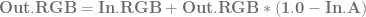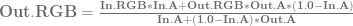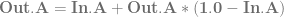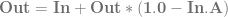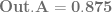If you ever have heard the terms “Box Blur”, “Boxcar Function”, “Box Filter”, “Boxcar Integrator” or other various combinations of those words, you may have thought it was some advanced concept that is hard to understand and hard to implement. If that’s what you thought, prepare to be surprised!
A box filter is nothing more than taking N samples of data (or NxN samples of data, or NxNxN etc) and averaging them! Yes, that is all there is to it 😛
In this post, we are going to implement a box blur by averaging pixels.
1D Case
For the case of a 1d box filter, let’s say we wanted every data point to be the result of averaging it with it’s two neighbors. It’d be easy enough to program that by just doing it, but let’s look at it a different way. What weight would we need to multiply each of the three values by (the value and it’s two neighbors) to make it come up with the average?

Yep, you guessed it! For every data value, you multiply it and it’s neighbors by 1/3 to come up with the average value. We could easily increase the size of the filter to 5 pixels, and multiply each pixel by 1/5 instead. We could continue the pattern as high as we wanted.
One thing you might notice is that if we want a buffer with all the results, we can’t just alter the source data as we go, because we want the unaltered source values of the data to use those weights with, to get the correct results. Because of that, we need to make a second buffer to put the results of the filtering into.
Believe it or not, that diagram above is a convolution kernel, and how we talked about applying it is how you do convolution in 1d! It just so happens that this convolution kernel averages three pixels into one, which also happens to provide a low pass filter type effect.
Low pass filtering is what is done before down sampling audio data to prevent aliasing (frequencies higher than the sample rate can handle, which makes audio sound bad).
Surprise… blurring can also be seen as low pass filtering, which is something you can do before scaling an image down in size, to prevent aliasing.
2D Case
The 2d case isn’t much more difficult to understand than the 1d case. Instead of only averaging on one axis, we average on two instead:

Something interesting to note is that you can either use this 3×3 2d convolution kernel, or, you could apply the 1d convolution kernel described above on the X axis and then the Y axis. The methods are mathematically equivalent.
Using the 2d convolution kernel would result in 9 multiplications per pixel, but if going with the separated axis X and then Y 1d kernel, you’d only end up doing 6 multiplications per pixel (3 multiplications per axis). In general, if you have a seperable 2d convolution kernel (meaning that you can break it into a per axis 1d convolution), you will end up doing N^2 multiplications when using the 2d kernel, versus N*2 multiplications when using the 1d kernels. You can see that this would add up quickly in favor of using 1d kernels, but unfortunately not all kernels are separable.
Doing two passes does come at a cost though. Since you have to use a temporary buffer for each pass, you end up having to create two temporary buffers instead of one.
You can build 2d kernels from 1d kernels by multiplying them as a row vector, by a column vector. For instance, you can see how multiplying the (1/3,1/3,1/3) kernel by itself as a column vector would create the 2nd kernel, that is 3×3 and has 1/9 in every spot.
The resulting 3×3 matrix is called an outer product, or a tensor product. Something interesting to note is that you don’t have to do the same operation on each axis!
Examples
Here are some examples of box blurring with different values, using the sample code provided below.
The source image:

Now blurred by a 10×10 box car convolution kernel:

Now blurred by a 100×10 box car convolution kernel:

Shadertoy
You can find a shadertoy implementation of box blurring here: Shadertoy:DF Box Blur

Code
Here’s the code I used to blur the example images above:
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <stdint.h>
#include <array>
#include <vector>
#include <functional>
#include <windows.h> // for bitmap headers. Sorry non windows people!
typedef uint8_t uint8;
const float c_pi = 3.14159265359f;
struct SImageData
{
SImageData()
: m_width(0)
, m_height(0)
{ }
long m_width;
long m_height;
long m_pitch;
std::vector<uint8> m_pixels;
};
void WaitForEnter ()
{
printf("Press Enter to quit");
fflush(stdin);
getchar();
}
bool LoadImage (const char *fileName, SImageData& imageData)
{
// open the file if we can
FILE *file;
file = fopen(fileName, "rb");
if (!file)
return false;
// read the headers if we can
BITMAPFILEHEADER header;
BITMAPINFOHEADER infoHeader;
if (fread(&header, sizeof(header), 1, file) != 1 ||
fread(&infoHeader, sizeof(infoHeader), 1, file) != 1 ||
header.bfType != 0x4D42 || infoHeader.biBitCount != 24)
{
fclose(file);
return false;
}
// read in our pixel data if we can. Note that it's in BGR order, and width is padded to the next power of 4
imageData.m_pixels.resize(infoHeader.biSizeImage);
fseek(file, header.bfOffBits, SEEK_SET);
if (fread(&imageData.m_pixels[0], imageData.m_pixels.size(), 1, file) != 1)
{
fclose(file);
return false;
}
imageData.m_width = infoHeader.biWidth;
imageData.m_height = infoHeader.biHeight;
imageData.m_pitch = imageData.m_width*3;
if (imageData.m_pitch & 3)
{
imageData.m_pitch &= ~3;
imageData.m_pitch += 4;
}
fclose(file);
return true;
}
bool SaveImage (const char *fileName, const SImageData &image)
{
// open the file if we can
FILE *file;
file = fopen(fileName, "wb");
if (!file)
return false;
// make the header info
BITMAPFILEHEADER header;
BITMAPINFOHEADER infoHeader;
header.bfType = 0x4D42;
header.bfReserved1 = 0;
header.bfReserved2 = 0;
header.bfOffBits = 54;
infoHeader.biSize = 40;
infoHeader.biWidth = image.m_width;
infoHeader.biHeight = image.m_height;
infoHeader.biPlanes = 1;
infoHeader.biBitCount = 24;
infoHeader.biCompression = 0;
infoHeader.biSizeImage = image.m_pixels.size();
infoHeader.biXPelsPerMeter = 0;
infoHeader.biYPelsPerMeter = 0;
infoHeader.biClrUsed = 0;
infoHeader.biClrImportant = 0;
header.bfSize = infoHeader.biSizeImage + header.bfOffBits;
// write the data and close the file
fwrite(&header, sizeof(header), 1, file);
fwrite(&infoHeader, sizeof(infoHeader), 1, file);
fwrite(&image.m_pixels[0], infoHeader.biSizeImage, 1, file);
fclose(file);
return true;
}
const uint8* GetPixelOrBlack (const SImageData& image, int x, int y)
{
static const uint8 black[3] = { 0, 0, 0 };
if (x < 0 || x >= image.m_width ||
y < 0 || y >= image.m_height)
{
return black;
}
return &image.m_pixels[(y * image.m_pitch) + x * 3];
}
void BlurImage (const SImageData& srcImage, SImageData &destImage, unsigned int xblur, unsigned int yblur)
{
// allocate space for copying the image for destImage and tmpImage
destImage.m_width = srcImage.m_width;
destImage.m_height = srcImage.m_height;
destImage.m_pitch = srcImage.m_pitch;
destImage.m_pixels.resize(destImage.m_height * destImage.m_pitch);
SImageData tmpImage;
tmpImage.m_width = srcImage.m_width;
tmpImage.m_height = srcImage.m_height;
tmpImage.m_pitch = srcImage.m_pitch;
tmpImage.m_pixels.resize(tmpImage.m_height * tmpImage.m_pitch);
// horizontal blur from srcImage into tmpImage
{
float weight = 1.0f / float(xblur);
int half = xblur / 2;
for (int y = 0; y < tmpImage.m_height; ++y)
{
for (int x = 0; x < tmpImage.m_width; ++x)
{
std::array<float, 3> blurredPixel = { 0.0f, 0.0f, 0.0f };
for (int i = -half; i <= half; ++i)
{
const uint8 *pixel = GetPixelOrBlack(srcImage, x + i, y);
blurredPixel[0] += float(pixel[0]) * weight;
blurredPixel[1] += float(pixel[1]) * weight;
blurredPixel[2] += float(pixel[2]) * weight;
}
uint8 *destPixel = &tmpImage.m_pixels[y * tmpImage.m_pitch + x * 3];
destPixel[0] = uint8(blurredPixel[0]);
destPixel[1] = uint8(blurredPixel[1]);
destPixel[2] = uint8(blurredPixel[2]);
}
}
}
// vertical blur from tmpImage into destImage
{
float weight = 1.0f / float(yblur);
int half = yblur / 2;
for (int y = 0; y < destImage.m_height; ++y)
{
for (int x = 0; x < destImage.m_width; ++x)
{
std::array<float, 3> blurredPixel = { 0.0f, 0.0f, 0.0f };
for (int i = -half; i <= half; ++i)
{
const uint8 *pixel = GetPixelOrBlack(tmpImage, x, y + i);
blurredPixel[0] += float(pixel[0]) * weight;
blurredPixel[1] += float(pixel[1]) * weight;
blurredPixel[2] += float(pixel[2]) * weight;
}
uint8 *destPixel = &destImage.m_pixels[y * destImage.m_pitch + x * 3];
destPixel[0] = uint8(blurredPixel[0]);
destPixel[1] = uint8(blurredPixel[1]);
destPixel[2] = uint8(blurredPixel[2]);
}
}
}
}
int main (int argc, char **argv)
{
int xblur, yblur;
bool showUsage = argc < 5 ||
(sscanf(argv[3], "%i", &xblur) != 1) ||
(sscanf(argv[4], "%i", &yblur) != 1);
char *srcFileName = argv[1];
char *destFileName = argv[2];
if (showUsage)
{
printf("Usage: <source> <dest> <xblur> <yblur>nn");
WaitForEnter();
return 1;
}
// make sure blur size is odd
xblur = xblur | 1;
yblur = yblur | 1;
printf("Attempting to blur a 24 bit image.n");
printf(" Source=%sn Dest=%sn blur=[%d,%d]nn", srcFileName, destFileName, xblur, yblur);
SImageData srcImage;
if (LoadImage(srcFileName, srcImage))
{
printf("%s loadedn", srcFileName);
SImageData destImage;
BlurImage(srcImage, destImage, xblur, yblur);
if (SaveImage(destFileName, destImage))
printf("Blurred image saved as %sn", destFileName);
else
{
printf("Could not save blurred image as %sn", destFileName);
WaitForEnter();
return 1;
}
}
else
{
printf("could not read 24 bit bmp file %snn", srcFileName);
WaitForEnter();
return 1;
}
return 0;
}
Next Up
Next up will be a Gaussian blur, and I’m nearly done w/ that post but wanted to make this one first as an introductory step!
Before we get there, I wanted to mention that if you do multiple box blurs in a row, it will start to approach Gaussian blurring. I’ve heard that three blurs in a row will make it basically indistinguishable from a Gaussian blur.











 continuity everywhere!
continuity everywhere! control points on a fixed interval, you can treat it as a bunch of piece wise cubic Hermite splines and evaluate it that way.
control points on a fixed interval, you can treat it as a bunch of piece wise cubic Hermite splines and evaluate it that way.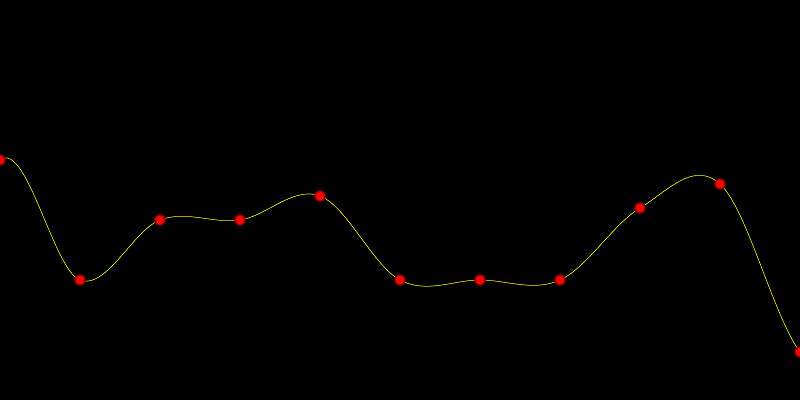
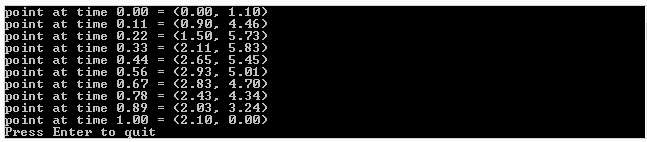
 . The curve at time 0 will be at point
. The curve at time 0 will be at point  and the slope will be the same slope as a line would have if going from
and the slope will be the same slope as a line would have if going from  to
to  . The curve at time 1 will be at point
. The curve at time 1 will be at point  .
.


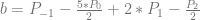


 are used to be able to make this interpolation
are used to be able to make this interpolation 


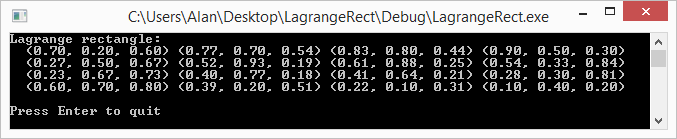

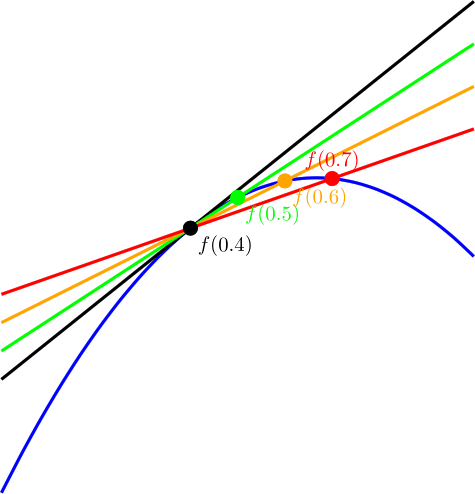
 at a specific value of x, you pick an epsilon e and then you calculate both
at a specific value of x, you pick an epsilon e and then you calculate both  and
and  . You subtract the first one from the second and divide by 2*e to get an approximated slope of the function at the specific value of x.
. You subtract the first one from the second and divide by 2*e to get an approximated slope of the function at the specific value of x.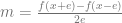

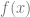 , subtracts the 1st one from the second one and divides the result by e.
, subtracts the 1st one from the second one and divides the result by e.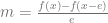

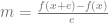


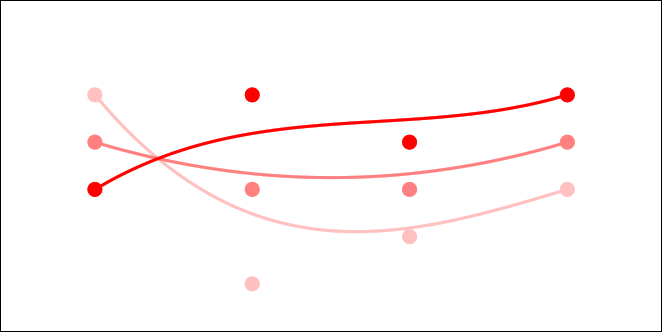


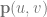 is the point on the surface that you get after you plug in the parameters.
is the point on the surface that you get after you plug in the parameters.  and
and  are the parameters to the surface and should be within the range 0 to 1. These are the same thing as the
are the parameters to the surface and should be within the range 0 to 1. These are the same thing as the 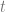 you see in Bezier curves, but there are two of them since there are two axes.
you see in Bezier curves, but there are two of them since there are two axes. go from 0 to
go from 0 to  and the other makes
and the other makes  go from 0 to
go from 0 to  .
.  and
and 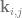 . The number of control on one axis are multiplied by the number of control points on the other axis.
. The number of control on one axis are multiplied by the number of control points on the other axis.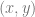 data pairs. The resulting function passes through all the data points you give it (like a Catmull-Rom spline does), so can be used to find a function to interpolate between data sets.
data pairs. The resulting function passes through all the data points you give it (like a Catmull-Rom spline does), so can be used to find a function to interpolate between data sets. degree polynomial. So, if you interpolate two data points, you’ll get a degree 1 polynomial (a line). If you interpolate three data points, you’ll get a degree 2 polynomial (a quadratic).
degree polynomial. So, if you interpolate two data points, you’ll get a degree 1 polynomial (a line). If you interpolate three data points, you’ll get a degree 2 polynomial (a quadratic).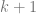 data points:
data points:

 ) just means that we are going to loop a variable j from 0 to k (including k), and we are going to sum up the total of everything on the right for all values of j. When you see a capital sigma, think sum (note they both start with an s).
) just means that we are going to loop a variable j from 0 to k (including k), and we are going to sum up the total of everything on the right for all values of j. When you see a capital sigma, think sum (note they both start with an s).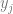 . That is just the y value from our jth control point. That is essentially controlPoints[j].y.
. That is just the y value from our jth control point. That is essentially controlPoints[j].y. . That is just the function for the jth control point that we multiply the control point by (aka the basis function), evaluated for the specific value x.
. That is just the function for the jth control point that we multiply the control point by (aka the basis function), evaluated for the specific value x.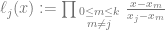
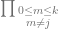 . This means that we are going to do a loop, but instead of adding the results of the loop, we are going to multiply them together. Where a capital sigma means sum, capital pi means product.
. This means that we are going to do a loop, but instead of adding the results of the loop, we are going to multiply them together. Where a capital sigma means sum, capital pi means product. , the notation $latex 0\le m\le k\\$ says that implicitly. That same notation can be used with sigma, or the more explicit style notation could be used with pi.
, the notation $latex 0\le m\le k\\$ says that implicitly. That same notation can be used with sigma, or the more explicit style notation could be used with pi. . That means that the case where
. That means that the case where  . This part is pretty easy to read.
. This part is pretty easy to read.  is the parameter to the function of course,
is the parameter to the function of course,  is just controlPoints[m].x where
is just controlPoints[m].x where  ), and
), and  is just controlPoints[j].x where
is just controlPoints[j].x where  ).
).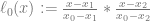
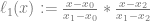


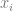 is just controlPoints[i].x and
is just controlPoints[i].x and  is just controlPoints[i].y.
is just controlPoints[i].y.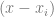 , but make sure and not include the x of the actual control point that we are multiplying against.
, but make sure and not include the x of the actual control point that we are multiplying against.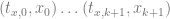



 !
! and
and 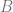 at time
at time 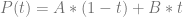 .
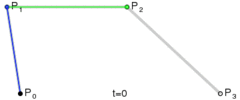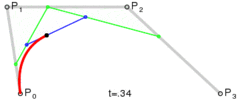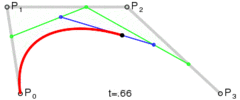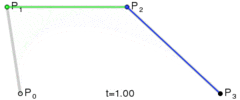
. . A quadratic curve is just a linear interpolation between two curves of degree 1 (aka linear curves). Specifically, you take a linear interpolation between
. A quadratic curve is just a linear interpolation between two curves of degree 1 (aka linear curves). Specifically, you take a linear interpolation between  , and a linear interpolation between
, and a linear interpolation between  , and then take a linear interpolation between those two results. That will give you your quadratic curve.
, and then take a linear interpolation between those two results. That will give you your quadratic curve.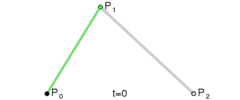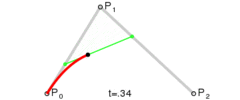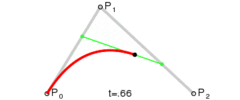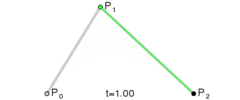
 . A cubic curve is just a linear interpolation between two quadratic curves. Specifically, the first quadratic curve is defined by control points
. A cubic curve is just a linear interpolation between two quadratic curves. Specifically, the first quadratic curve is defined by control points  .
.
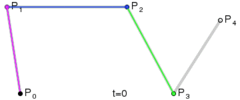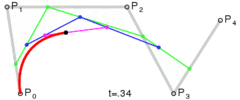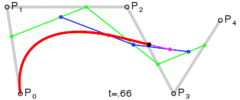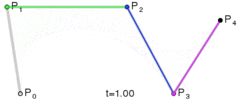
 . A quartic curve is just a linear interpolation between two cubic curves. The first cubic curve is defined by control points
. A quartic curve is just a linear interpolation between two cubic curves. The first cubic curve is defined by control points  .
.

 is just
is just  )
)
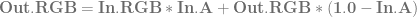
 and
and  , using the alpha of the pixel you are writing to determine the weighting for the lerp.
, using the alpha of the pixel you are writing to determine the weighting for the lerp.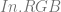 is already multipled by
is already multipled by  which results in slightly less math:
which results in slightly less math: