Shadertoy.com recently added multipass rendering, and one of the founders – iq – introduced the feature to us by (ab)using an off screen texture to store state from previous frames. This was interesting because up until that point, you had to render each frame using only the current time, and current input from the user – you had no knowledge whatsoever of the past. He ended up making a brick breaking game, which is pretty awesome. You can see it here: Shadertoy: Bricks Game.
I decided to follow that path too and make a snake game in shadertoy. This is a high level overview of how the game works and various considerations that came up while creating the game.
Play Shadertoy: Snake Game

Simulation vs. Presentation
When you start making a shadertoy shader, you have a single pixel shader program to work in. In the past this is where you did all your work to display the image to the user.
Now with multipass rendering you have the option of creating an off screen buffer (up to four of them actually, but we only need one for this discussion), which you write a pixel shader program for as well. This program is able to write to the off screen buffer by emitting pixels (like usual), but interestingly, it can also read from the same off screen buffer. Since it can both read and write the image, this allows it to preserve state across frames.
Since this pixel shader has state (unlike the main on screen pixel shader), this is where all your “simulation code” has to go. This is where you do all your game logic. Strangely, even though this buffer is a full screen buffer, you only need to process as many pixels as you need for storage of your game state. You can use the “discard” keyword for all other pixels, to get a quick “early out” in the pixel processing.
The on screen pixel shader is able to read this off screen buffer which stores game state, but it isn’t able to write to it. Because of this, the on screen pixel shader is essentially the visualization of the simulation.
Simulation Considerations
The simulation had quite a few considerations. Some of these were a little mind bending at first, but made sense after thinking about it for a while.
Perhaps the single strangest thing about the simulation pixel shader program is this: The pixel shader program can only write the value of the pixel that it represents. Let’s talk some details about what that means.
Reading and Writing Variables
In the snake game, there is a grid of 16×16 pixels, where each pixel stores the state of a game cell. Besides this, there are four other pixels that store various pieces of game state – like what direction the snake is moving in, whether the snake is dead or not, and the location of the apple.
One complication of this is that to spawn an apple, we have to set the apple’s location variable, but we also have to mark that an apple is in the specific grid cell where it should be. What we essentially have to do is pick a random location for the apple to go to, and then we essentially have to say “if the pixel that this shader program is running for, is the specific grid cell where the apple should spawn at, then emit a pixel color that represents the necessary data to represent an apple”.
That is kind of weird. Even weirder perhaps, you have to remember that this pixel shader program is being run for several pixels per frame (once per variable you have in your state!), and they all have to be in agreement about the random position of the apple so that only one apple gets written to the board, so your random numbers have to be deterministic, yet still seemingly random to the player.
It’s odd to think that the entire game simulation is running per variable in your simulation, but that is what is happening.
There’s a trap that’s easy to fall in here too, where you might be tempted to write code like this: “If the pixel that we are running the shader program for is the new location that the snake wants to move to, and that grid cell contains a snake body part, then set the game over game state variable flag to true”
The problem there is that our if statement guarantees that we are running the pixel shader program for a grid cell, not for the game over game state variable, so when we change the game over state variable, it doesn’t get written out, since this pixel shader program instance isn’t running for that variable.
I actually wrote that exact code and it took me a little while to figure out why the game wouldn’t end when the snake crashed into itself, but it would end if it went out of bounds. The code looked very similar, and was very simple, and one worked, but the other didn’t.
The answer here is that instead of only running the logic for the grid cell that the snake head wants to enter, you have to make the logic run for all instances. So, unfortunately that means a texture read to read the grid cell that the snake head wants to enter into. That way, all instances have the information they need to run the same logic.
Technically, I guess it’s only the “game over” variable that needs to do the texture read, but it’s a lot easier and safer if you make all pixels run the same code deterministically. Also, having each pixel run the same code is likely a performance gain.
You might be able to squeeze some more performance out of being clever, but it’s real easy to bite you in the end too! In this case, the snake game runs well enough (60fps on my machine, even with the camera edge on which is the worst case) so I’m calling it good.
Numerical Problems
One gotcha to be wary of is that since you are storing game state variables in pixels, is that every variable is a vec4 of floats, and that they can only store floating point values between 0 and 1. So, if you are storing the position of a cell in a grid, you need to “normalize it” to be between 0 and 1.
Sadly, the floating point isn’t really guaranteed to be a full 32 bit floating point number either, and might be an 8 bit fixed point number or similar on some platforms. This makes it real easy to have numerical problems when you normalize your values into the 0 to 1 range.
Random Apple Spawning
When an apple is eaten (or the game is starting) an apple needs to spawn in a random location that isn’t yet taken by the snake’s body. This would mean generating random numbers in a loop until we found an empty spot. This could possibly be a perf problem for the pixel shader, possibly doing a large number of iterations, and possibly not finding a valid location by the time it ran out of it’s fixed size for loop indices.
I went with a different solution. When there is no apple spawned, the simulation generates a random position to put the apple at, and if it’s empty, it puts the apple there. If the position already was taken by a snake body part, it leaves the apple unspawned and tries again next frame. With a suitably high frame rate (it runs at 60fps for me!) it ought to be able to find an empty spot pretty quickly, even if you have a really large snake.
Frame Rate Independent Gameplay
When making games on any platform, it’s very easy to have problems with objects moving faster on machines that have higher FPS. The typical way to solve this is to keep track of how much time has elapsed between frames, keeping a total as the frames progress, and when the total gets above a certain point, you do a game update and reset the total back to zero (or the remainder after subtracting your “tick time” out of the total).
This was luckily very easy to do in shadertoy as well. There is a value you are provided called “iTimeDelta” which is how long the last frame took to render, in seconds. I divide this number by how many ticks i want per second so that the total will always be between 0 and 1, and then add it into a state variable (which is stored in a pixel). When doing the add, if the result is ever greater than 1, i do a tick, and reset it to 0.
Doing the tick just means moving the snake and handling whether the snake ate an apple, died, etc.
Low Latency Input
At first I had my input handling be handled inside of the tick. This was a problem because the tick happens 12 times a second, which means if you want the snake to change directions, you better have the key pressed down during one of those ticks. If you press it and then release it between ticks, the key press is lost and the snake doesn’t change direction and you die. This was extremely noticeable and made for really bad controls.
To solve this, I moved the key press handling to be OUTSIDE the tick, and had it be processed every frame. Instead of changing the snake’s direction right away though, I queued it up to be handled on the next tick. This way, you can quickly tap keys and they are registered as they should be on the next tick. The controls feel fine now and all is well.
Visualization & Rendering
The rendering of the snake game had fewer considerations than the simulation, but there are a couple things worth mentioning.
There are just a few parts to the rendering:
- If the ray hits the game board, make it look like the game board
- If the ray enters the small box of “play area” above the game board, it raytraces the contents of the game board
- If the ray misses everything, it does a lookup in a cube map texture to get the background
- If the ray hits anything, it uses some variables (normal, diffuse color, shinyness) from the collision to do the shading. It also does a lookup in the cube map texture to do some environment mapping to give the impression that reflection is happening, even though it isn’t
The second bullet item is the most interesting. What the code does is find the grid cells that the ray enters and leaves the play area, and then it walks from the start to the end, checking each cell to see if it has anything in it, and if so, doing a raytrace test against it.
At first I used the Bresenham line algorithm to walk the grid cells, but when there were holes in some of my spheres in strange places, I realized my problem. Bresenham isn’t meant to draw to (visit) every grid cell that a line passes through – it is only meant to draw to the most important ones!
So, I replaced Bresenham with a grid traversal algorithm and all was well.
The game is rendered using real time raytracing, but it only does PRIMARY rays. It doesn’t do reflection, refraction or shadows. This is because doing any of those things means raytracing against the game board (grid cells) more than once. Since we have to do a texture lookup per grid cell we want to raytrace, this could equal a lot of texture lookups as you can imagine. There is a hard limit to the number you can do (I’m pretty sure, although I don’t know what it is, and it probably varies from machine to machine), so I wanted to try and not push things too hard, and just stayed with primary rays only.
That’s All!
That’s basically it. Multipass rendering is an awesome feature in shadertoy. On one hand it makes me a bit sad getting it, because people don’t have to work within such tight constraints when doing the amazing things they do in shadertoy. On the other hand though, I think multipass rendering really ought to empower people to do some much more amazing things than in previous days – including but not limited to games.
I really look forward to learning from what other people are doing to learn more about how to leverage multipass rendering in interesting ways.
I also look forward to contributing my own game and non game multipass shaders. I have some ideas for both, keep an eye out (:


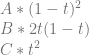
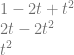

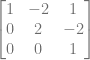
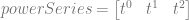
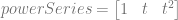
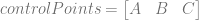

![value = result[0] + result[1] + result[2]](https://s0.wp.com/latex.php?latex=value+%3D+result%5B0%5D+%2B+result%5B1%5D+%2B+result%5B2%5D+&bg=ffffff&fg=666666&s=0&c=20201002)
























 ) – This defines how much blur there is. A larger number is a higher amount of blur.
) – This defines how much blur there is. A larger number is a higher amount of blur.

 .
. . So technically, you could use a row from Pascal’s triangle as a 1d kernel and normalize the result, but it isn’t the most accurate.
. So technically, you could use a row from Pascal’s triangle as a 1d kernel and normalize the result, but it isn’t the most accurate.






