
In the post How to Train Neural Networks With Backpropagation I said that you could also calculate the gradient of a neural network by using dual numbers or finite differences.
By special request, this is that post!
The post I already linked to explains backpropagation.
If you want an explanation of dual numbers, check out these posts:
If you want an explanation of finite differences, check out this post:
Finite Differences
Since the fundamentals are explained in the links above, we’ll go straight to the code.
We’ll be getting the gradient (learning values) for the network in example 4 in the backpropagation post:

Note that I am using “central differences” for the gradient, but it would be more efficient to do a forward or backward difference, at the cost of some accuracy. I’m using an epsilon of 0.001.
I didn’t compare the running times of each method as my code is meant to be readable, not fast, and the code isn’t doing enough work to make a meaningful performance test IMO. If you did do a speed test, the finite differences should be by far the slowest, backpropagation should be the fastest, and dual numbers are probably going to be closer to backpropagation than to finite differences.
The output of the program is below. Both backpropagation and dual numbers get the exact derivatives (within the tolerances of floating point math of course!) because they use the chain rule, whereas finite differences is a numerical approximation. This shows up in the fact that backpropagation and dual numbers agree for all values, where finite differences has some small error in the derivatives.
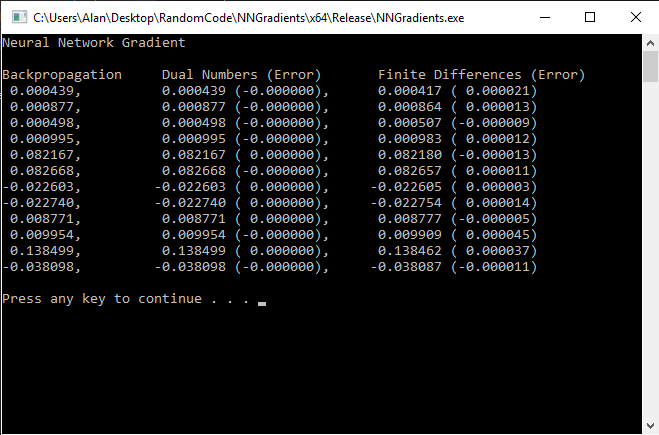
And here is the code:
#include <stdio.h>
#include <cmath>
#include <array>
#include <algorithm>
#define PI 3.14159265359f
#define EPSILON 0.001f // for numeric derivatives calculation
//----------------------------------------------------------------------
// Dual Number Class - CDualNumber
//----------------------------------------------------------------------
template <size_t NUMVARIABLES>
class CDualNumber
{
public:
// constructor to make a constant
CDualNumber (float f = 0.0f) {
m_real = f;
std::fill(m_dual.begin(), m_dual.end(), 0.0f);
}
// constructor to make a variable value. It sets the derivative to 1.0 for whichever variable this is a value for.
CDualNumber (float f, size_t variableIndex) {
m_real = f;
std::fill(m_dual.begin(), m_dual.end(), 0.0f);
m_dual[variableIndex] = 1.0f;
}
// Set a constant value.
void Set (float f) {
m_real = f;
std::fill(m_dual.begin(), m_dual.end(), 0.0f);
}
// Set a variable value. It sets the derivative to 1.0 for whichever variable this is a value for.
void Set (float f, size_t variableIndex) {
m_real = f;
std::fill(m_dual.begin(), m_dual.end(), 0.0f);
m_dual[variableIndex] = 1.0f;
}
// storage for real and dual values
float m_real;
std::array<float, NUMVARIABLES> m_dual;
};
//----------------------------------------------------------------------
// Dual Number Math Operations
//----------------------------------------------------------------------
template <size_t NUMVARIABLES>
inline CDualNumber<NUMVARIABLES> operator + (const CDualNumber<NUMVARIABLES> &a, const CDualNumber<NUMVARIABLES> &b)
{
CDualNumber<NUMVARIABLES> ret;
ret.m_real = a.m_real + b.m_real;
for (size_t i = 0; i < NUMVARIABLES; ++i)
ret.m_dual[i] = a.m_dual[i] + b.m_dual[i];
return ret;
}
template <size_t NUMVARIABLES>
inline CDualNumber<NUMVARIABLES> operator - (const CDualNumber<NUMVARIABLES> &a, const CDualNumber<NUMVARIABLES> &b)
{
CDualNumber<NUMVARIABLES> ret;
ret.m_real = a.m_real - b.m_real;
for (size_t i = 0; i < NUMVARIABLES; ++i)
ret.m_dual[i] = a.m_dual[i] - b.m_dual[i];
return ret;
}
template <size_t NUMVARIABLES>
inline CDualNumber<NUMVARIABLES> operator * (const CDualNumber<NUMVARIABLES> &a, const CDualNumber<NUMVARIABLES> &b)
{
CDualNumber<NUMVARIABLES> ret;
ret.m_real = a.m_real * b.m_real;
for (size_t i = 0; i < NUMVARIABLES; ++i)
ret.m_dual[i] = a.m_real * b.m_dual[i] + a.m_dual[i] * b.m_real;
return ret;
}
template <size_t NUMVARIABLES>
inline CDualNumber<NUMVARIABLES> operator / (const CDualNumber<NUMVARIABLES> &a, const CDualNumber<NUMVARIABLES> &b)
{
CDualNumber<NUMVARIABLES> ret;
ret.m_real = a.m_real / b.m_real;
for (size_t i = 0; i < NUMVARIABLES; ++i)
ret.m_dual[i] = (a.m_dual[i] * b.m_real - a.m_real * b.m_dual[i]) / (b.m_real * b.m_real);
return ret;
}
// NOTE: the "special functions" below all just use the chain rule, which you can also use to add more functions
template <size_t NUMVARIABLES>
inline CDualNumber<NUMVARIABLES> sqrt (const CDualNumber<NUMVARIABLES> &a)
{
CDualNumber<NUMVARIABLES> ret;
float sqrtReal = sqrt(a.m_real);
ret.m_real = sqrtReal;
for (size_t i = 0; i < NUMVARIABLES; ++i)
ret.m_dual[i] = 0.5f * a.m_dual[i] / sqrtReal;
return ret;
}
template <size_t NUMVARIABLES>
inline CDualNumber<NUMVARIABLES> pow (const CDualNumber<NUMVARIABLES> &a, float y)
{
CDualNumber<NUMVARIABLES> ret;
ret.m_real = pow(a.m_real, y);
for (size_t i = 0; i < NUMVARIABLES; ++i)
ret.m_dual[i] = y * a.m_dual[i] * pow(a.m_real, y - 1.0f);
return ret;
}
template <size_t NUMVARIABLES>
inline CDualNumber<NUMVARIABLES> exp (const CDualNumber<NUMVARIABLES>& a)
{
CDualNumber<NUMVARIABLES> ret;
ret.m_real = exp(a.m_real);
for (size_t i = 0; i < NUMVARIABLES; ++i)
ret.m_dual[i] = a.m_dual[i] * exp(a.m_real);
return ret;
}
template <size_t NUMVARIABLES>
inline CDualNumber<NUMVARIABLES> sin (const CDualNumber<NUMVARIABLES> &a)
{
CDualNumber<NUMVARIABLES> ret;
ret.m_real = sin(a.m_real);
for (size_t i = 0; i < NUMVARIABLES; ++i)
ret.m_dual[i] = a.m_dual[i] * cos(a.m_real);
return ret;
}
template <size_t NUMVARIABLES>
inline CDualNumber<NUMVARIABLES> cos (const CDualNumber<NUMVARIABLES> &a)
{
CDualNumber<NUMVARIABLES> ret;
ret.m_real = cos(a.m_real);
for (size_t i = 0; i < NUMVARIABLES; ++i)
ret.m_dual[i] = -a.m_dual[i] * sin(a.m_real);
return ret;
}
template <size_t NUMVARIABLES>
inline CDualNumber<NUMVARIABLES> tan (const CDualNumber<NUMVARIABLES> &a)
{
CDualNumber<NUMVARIABLES> ret;
ret.m_real = tan(a.m_real);
for (size_t i = 0; i < NUMVARIABLES; ++i)
ret.m_dual[i] = a.m_dual[i] / (cos(a.m_real) * cos(a.m_real));
return ret;
}
template <size_t NUMVARIABLES>
inline CDualNumber<NUMVARIABLES> atan (const CDualNumber<NUMVARIABLES> &a)
{
CDualNumber<NUMVARIABLES> ret;
ret.m_real = tan(a.m_real);
for (size_t i = 0; i < NUMVARIABLES; ++i)
ret.m_dual[i] = a.m_dual[i] / (1.0f + a.m_real * a.m_real);
return ret;
}
// templated so it can work for both a CDualNumber<1> and a float
template <typename T>
inline T SmoothStep (const T& x)
{
return x * x * (T(3.0f) - T(2.0f) * x);
}
//----------------------------------------------------------------------
// Driver Program
//----------------------------------------------------------------------
enum EWeightsBiases
{
e_weight0 = 0,
e_weight1,
e_weight2,
e_weight3,
e_weight4,
e_weight5,
e_weight6,
e_weight7,
e_bias0,
e_bias1,
e_bias2,
e_bias3,
e_count
};
// our dual number needs a "dual" for every value we want a derivative for: aka every weight and bias
typedef CDualNumber<EWeightsBiases::e_count> TDualNumber;
// templated so it can work for both the dual numbers, as well as the float finite differences
template <typename TBaseType>
void ForwardPass (const std::array<TBaseType, 2>& input, const std::array<TBaseType, 2>& desiredOutput, const std::array<TBaseType, EWeightsBiases::e_count>& weightsBiases, TBaseType& cost)
{
// calculate hidden layer neuron activations
TBaseType Z0 = input[0] * weightsBiases[e_weight0] + input[1] * weightsBiases[e_weight1] + weightsBiases[e_bias0];
TBaseType O0 = TBaseType(1.0f) / (TBaseType(1.0f) + exp(Z0 * TBaseType(-1.0f)));
TBaseType Z1 = input[0] * weightsBiases[e_weight2] + input[1] * weightsBiases[e_weight3] + weightsBiases[e_bias1];
TBaseType O1 = TBaseType(1.0f) / (TBaseType(1.0f) + exp(Z1 * TBaseType(-1.0f)));
// calculate output layer neuron activations
TBaseType Z2 = O0 * weightsBiases[e_weight4] + O1 * weightsBiases[e_weight5] + weightsBiases[e_bias2];
TBaseType O2 = TBaseType(1.0f) / (TBaseType(1.0f) + exp(Z2 * TBaseType(-1.0f)));
TBaseType Z3 = O0 * weightsBiases[e_weight6] + O1 * weightsBiases[e_weight7] + weightsBiases[e_bias3];
TBaseType O3 = TBaseType(1.0f) / (TBaseType(1.0f) + exp(Z3 * TBaseType(-1.0f)));
// calculate the cost: 0.5 * ||target-actual||^2
// aka cost = half (error squared)
TBaseType diff1 = TBaseType(desiredOutput[0]) - O2;
TBaseType diff2 = TBaseType(desiredOutput[1]) - O3;
cost = TBaseType(0.5f) * (diff1*diff1 + diff2*diff2);
}
// backpropagation
void ForwardPassAndBackpropagation (
const std::array<float, 2>& input, const std::array<float, 2>& desiredOutput,
const std::array<float, EWeightsBiases::e_count>& weightsBiases,
float& error, float& cost, std::array<float, 2>& actualOutput,
std::array<float, EWeightsBiases::e_count>& deltaWeightsBiases
) {
// calculate Z0 and O0 for neuron0
float Z0 = input[0] * weightsBiases[e_weight0] + input[1] * weightsBiases[e_weight1] + weightsBiases[e_bias0];
float O0 = 1.0f / (1.0f + std::exp(-Z0));
// calculate Z1 and O1 for neuron1
float Z1 = input[0] * weightsBiases[e_weight2] + input[1] * weightsBiases[e_weight3] + weightsBiases[e_bias1];
float O1 = 1.0f / (1.0f + std::exp(-Z1));
// calculate Z2 and O2 for neuron2
float Z2 = O0 * weightsBiases[e_weight4] + O1 * weightsBiases[e_weight5] + weightsBiases[e_bias2];
float O2 = 1.0f / (1.0f + std::exp(-Z2));
// calculate Z3 and O3 for neuron3
float Z3 = O0 * weightsBiases[e_weight6] + O1 * weightsBiases[e_weight7] + weightsBiases[e_bias3];
float O3 = 1.0f / (1.0f + std::exp(-Z3));
// the actual output of the network is the activation of the output layer neurons
actualOutput[0] = O2;
actualOutput[1] = O3;
// calculate error
float diff0 = desiredOutput[0] - actualOutput[0];
float diff1 = desiredOutput[1] - actualOutput[1];
error = std::sqrt(diff0*diff0 + diff1*diff1);
// calculate cost
cost = 0.5f * error * error;
//----- Neuron 2 -----
// calculate how much a change in neuron 2 activation affects the cost function
// deltaCost/deltaO2 = O2 - target0
float deltaCost_deltaO2 = O2 - desiredOutput[0];
// calculate how much a change in neuron 2 weighted input affects neuron 2 activation
// deltaO2/deltaZ2 = O2 * (1 - O2)
float deltaO2_deltaZ2 = O2 * (1 - O2);
// calculate how much a change in neuron 2 weighted input affects the cost function.
// This is deltaCost/deltaZ2, which equals deltaCost/deltaO2 * deltaO2/deltaZ2
// This is also deltaCost/deltaBias2 and is also refered to as the error of neuron 2
float neuron2Error = deltaCost_deltaO2 * deltaO2_deltaZ2;
deltaWeightsBiases[e_bias2] = neuron2Error;
// calculate how much a change in weight4 affects the cost function.
// deltaCost/deltaWeight4 = deltaCost/deltaO2 * deltaO2/deltaZ2 * deltaZ2/deltaWeight4
// deltaCost/deltaWeight4 = neuron2Error * deltaZ/deltaWeight4
// deltaCost/deltaWeight4 = neuron2Error * O0
// similar thing for weight5
deltaWeightsBiases[e_weight4] = neuron2Error * O0;
deltaWeightsBiases[e_weight5] = neuron2Error * O1;
//----- Neuron 3 -----
// calculate how much a change in neuron 3 activation affects the cost function
// deltaCost/deltaO3 = O3 - target1
float deltaCost_deltaO3 = O3 - desiredOutput[1];
// calculate how much a change in neuron 3 weighted input affects neuron 3 activation
// deltaO3/deltaZ3 = O3 * (1 - O3)
float deltaO3_deltaZ3 = O3 * (1 - O3);
// calculate how much a change in neuron 3 weighted input affects the cost function.
// This is deltaCost/deltaZ3, which equals deltaCost/deltaO3 * deltaO3/deltaZ3
// This is also deltaCost/deltaBias3 and is also refered to as the error of neuron 3
float neuron3Error = deltaCost_deltaO3 * deltaO3_deltaZ3;
deltaWeightsBiases[e_bias3] = neuron3Error;
// calculate how much a change in weight6 affects the cost function.
// deltaCost/deltaWeight6 = deltaCost/deltaO3 * deltaO3/deltaZ3 * deltaZ3/deltaWeight6
// deltaCost/deltaWeight6 = neuron3Error * deltaZ/deltaWeight6
// deltaCost/deltaWeight6 = neuron3Error * O0
// similar thing for weight7
deltaWeightsBiases[e_weight6] = neuron3Error * O0;
deltaWeightsBiases[e_weight7] = neuron3Error * O1;
//----- Neuron 0 -----
// calculate how much a change in neuron 0 activation affects the cost function
// deltaCost/deltaO0 = deltaCost/deltaZ2 * deltaZ2/deltaO0 + deltaCost/deltaZ3 * deltaZ3/deltaO0
// deltaCost/deltaO0 = neuron2Error * weight4 + neuron3error * weight6
float deltaCost_deltaO0 = neuron2Error * weightsBiases[e_weight4] + neuron3Error * weightsBiases[e_weight6];
// calculate how much a change in neuron 0 weighted input affects neuron 0 activation
// deltaO0/deltaZ0 = O0 * (1 - O0)
float deltaO0_deltaZ0 = O0 * (1 - O0);
// calculate how much a change in neuron 0 weighted input affects the cost function.
// This is deltaCost/deltaZ0, which equals deltaCost/deltaO0 * deltaO0/deltaZ0
// This is also deltaCost/deltaBias0 and is also refered to as the error of neuron 0
float neuron0Error = deltaCost_deltaO0 * deltaO0_deltaZ0;
deltaWeightsBiases[e_bias0] = neuron0Error;
// calculate how much a change in weight0 affects the cost function.
// deltaCost/deltaWeight0 = deltaCost/deltaO0 * deltaO0/deltaZ0 * deltaZ0/deltaWeight0
// deltaCost/deltaWeight0 = neuron0Error * deltaZ0/deltaWeight0
// deltaCost/deltaWeight0 = neuron0Error * input0
// similar thing for weight1
deltaWeightsBiases[e_weight0] = neuron0Error * input[0];
deltaWeightsBiases[e_weight1] = neuron0Error * input[1];
//----- Neuron 1 -----
// calculate how much a change in neuron 1 activation affects the cost function
// deltaCost/deltaO1 = deltaCost/deltaZ2 * deltaZ2/deltaO1 + deltaCost/deltaZ3 * deltaZ3/deltaO1
// deltaCost/deltaO1 = neuron2Error * weight5 + neuron3error * weight7
float deltaCost_deltaO1 = neuron2Error * weightsBiases[e_weight5] + neuron3Error * weightsBiases[e_weight7];
// calculate how much a change in neuron 1 weighted input affects neuron 1 activation
// deltaO1/deltaZ1 = O1 * (1 - O1)
float deltaO1_deltaZ1 = O1 * (1 - O1);
// calculate how much a change in neuron 1 weighted input affects the cost function.
// This is deltaCost/deltaZ1, which equals deltaCost/deltaO1 * deltaO1/deltaZ1
// This is also deltaCost/deltaBias1 and is also refered to as the error of neuron 1
float neuron1Error = deltaCost_deltaO1 * deltaO1_deltaZ1;
deltaWeightsBiases[e_bias1] = neuron1Error;
// calculate how much a change in weight2 affects the cost function.
// deltaCost/deltaWeight2 = deltaCost/deltaO1 * deltaO1/deltaZ1 * deltaZ1/deltaWeight2
// deltaCost/deltaWeight2 = neuron1Error * deltaZ2/deltaWeight2
// deltaCost/deltaWeight2 = neuron1Error * input0
// similar thing for weight3
deltaWeightsBiases[e_weight2] = neuron1Error * input[0];
deltaWeightsBiases[e_weight3] = neuron1Error * input[1];
}
int main (int argc, char **argv)
{
// weights and biases, inputs and desired output
const std::array<float, EWeightsBiases::e_count> weightsBiases =
{
0.15f, // e_weight0
0.2f, // e_weight1
0.25f, // e_weight2
0.3f, // e_weight3
0.4f, // e_weight4
0.45f, // e_weight5
0.5f, // e_weight6
0.55f, // e_weight7
0.35f, // e_bias0
0.35f, // e_bias1
0.6f, // e_bias2
0.6f // e_bias3
};
const std::array<float, 2> inputs =
{
0.05f,
0.1f
};
std::array<float, 2> desiredOutput = {
0.01f,
0.99f
};
// =====================================================
// ===== FINITE DIFFERENCES CALCULATED DERIVATIVES =====
// =====================================================
std::array<float, EWeightsBiases::e_count> gradientFiniteDifferences;
std::array<float, EWeightsBiases::e_count> weightsBiasesFloat;
for (size_t i = 0; i < EWeightsBiases::e_count; ++i)
weightsBiasesFloat[i] = weightsBiases[i];
// use central differences to approximate the gradient
for (size_t i = 0; i < EWeightsBiases::e_count; ++i)
{
float costSample1 = 0.0f;
weightsBiasesFloat[i] = weightsBiases[i] - EPSILON;
ForwardPass(inputs, desiredOutput, weightsBiasesFloat, costSample1);
float costSample2 = 0.0f;
weightsBiasesFloat[i] = weightsBiases[i] + EPSILON;
ForwardPass(inputs, desiredOutput, weightsBiasesFloat, costSample2);
gradientFiniteDifferences[i] = (costSample2 - costSample1) / (EPSILON * 2.0f);
weightsBiasesFloat[i] = weightsBiases[i];
}
// ==============================================
// ===== DUAL NUMBER CALCULATED DERIVATIVES =====
// ==============================================
// dual number weights and biases
std::array<TDualNumber, EWeightsBiases::e_count> weightsBiasesDual;
for (size_t i = 0; i < EWeightsBiases::e_count; ++i)
weightsBiasesDual[i].Set(weightsBiases[i], i);
// dual number inputs and desired output
std::array<TDualNumber, 2> inputsDual;
for (size_t i = 0; i < inputsDual.size(); ++i)
inputsDual[i].Set(inputs[i]);
std::array<TDualNumber, 2> desiredOutputDual;
for (size_t i = 0; i < desiredOutputDual.size(); ++i)
desiredOutputDual[i].Set(desiredOutput[i]);
// dual number derivatives
TDualNumber gradientDualNumbers;
ForwardPass(inputsDual, desiredOutputDual, weightsBiasesDual, gradientDualNumbers);
// ==================================================
// ===== BACKPROPAGATION CALCULATED DERIVATIVES =====
// ==================================================
float error;
float cost;
std::array<float, 2> actualOutput;
std::array<float, EWeightsBiases::e_count> gradientBackPropagation;
ForwardPassAndBackpropagation(inputs, desiredOutput, weightsBiases, error, cost, actualOutput, gradientBackPropagation);
// ==========================
// ===== Report Results =====
// ==========================
printf("Neural Network GradientnnBackpropagation Dual Numbers (Error) Finite Differences (Error)n");
for (size_t i = 0; i < EWeightsBiases::e_count; ++i)
{
float diffDual = gradientBackPropagation[i] - gradientDualNumbers.m_dual[i];
float diffFinitDifferences = gradientBackPropagation[i] - gradientFiniteDifferences[i];
printf("% 08f, % 08f (% 08f), % 08f (% 08f)n",
gradientBackPropagation[i],
gradientDualNumbers.m_dual[i], diffDual,
gradientFiniteDifferences[i], diffFinitDifferences
);
}
printf("n");
system("pause");
return 0;
}
