
There is ~400 lines of standalone C++ code that implements the main ideas in this post. You can find it at: https://github.com/Atrix256/MetropolisMCMC
In previous posts I showed how to generate random numbers from a specific distributing by using two techniques:
Rejection Sampling: https://blog.demofox.org/2017/08/08/generating-random-numbers-from-a-specific-distribution-with-rejection-sampling/
Inverting the CDF: https://blog.demofox.org/2017/08/05/generating-random-numbers-from-a-specific-distribution-by-inverting-the-cdf/
This post will show how to do it using a Markov Chain Monte Carlo method called “The Metropolis Algorithm”. This post also talks about using it for numerical integration.
If you want an intro or review to either Markov Chains or Monte Carlo, these two posts can help you out.
Monte Carlo: https://blog.demofox.org/2018/06/12/monte-carlo-integration-explanation-in-1d/
Markov Chains: https://blog.demofox.org/2019/05/11/markov-chain-text-generation/
Overview
The Metropolis algorithm lets you generate random numbers that follow a distribution given by any function y=f(x), where y is the probability of choosing x.
Rejection sampling does this as well, but you have to throw away an unknown number of bad samples before getting each good sample.
Inverting the CDF doesn’t throw out any samples, but it’s limited in the type of distributions it can do: It can be mathematically complex, or impossible, to find the inverted CDF for a given function analytically.
In these ways, the Metropolis algorithm is the best of both worlds. You can sample from a distribution defined from any function, and you don’t have to throw out any samples while doing it.
Another interesting thing about the Metropolis algorithm is that it can work blindly. It never actually has to KNOW what function describes the probability distribution. If there is a black box you can give an x to get a y, the Metropolis algorithm can generate random numbers from the distribution hidden in that black box.
The Metropolis algorithm also works in any dimension: you can use it with functions like z=f(x,y) or t = f(x,y,z,w,s).
In higher dimensions such as z=f(x,y), the z is the probability of a 2d random number (x,y) being chosen. It sounds weird but this situation is like if you rolled two dice, the value that one die came up as affected the probability of the other die. Maybe when the first die was a larger number, it made it be more probable for the other die to be a larger number too.
As weird as that is, if you can describe the relationship as a z=f(x,y) function, this can generate (x,y) random numbers from that distribution for you.
It’s worth noting that the Metropolis algorithm is a simpler special case of the Metropolis-Hastings algorithm, and these are just two of many Markov Chain Monte Carlo algorithms.
The Metropolis Algorithm
The metropolis algorithm is pretty simple.
You start with an x value and calculate y which is just f(x). This is the initial sample and hopefully is a location where y is greater than 0.
To get the next sample, we first need to calculate a candidate sample, and then choose whether to take it or not.
To make a candidate sample, take a small random step from the current x point to get a new x, either in the negative or positive direction. Calculate y which is just f(x) using the new x.
Calculate a value A (for acceptance value) which is the candidate y divided by the last y value. This is the percentage chance you should take the new sample as the current sample, otherwise you take the old sample as the current sample.
To make the decision, you just generate a random number between 0 and 1 and accept the new sample if it’s below the A value.
Rinse and repeat for as many samples as you want.
Here’s a simple but fully featured implementation that you can find in the code that goes with this post(https://github.com/Atrix256/MetropolisMCMC)

The x axis of each sample is a random number drawn from the distribution described by y=f(x). If you keep track of the average x value seen, you’ll get the expected value of the PDF.
The y axis of each sample isn’t that useful directly. It’s the pdf(x) but scaled up by an unknown amount – the normalization constant for the function.
The convergence rate of Metropolis MCMC isn’t as well understood as monte carlo integration, since Metropolis has dependent samples (a random walk that knows where it was last step) vs independent samples (a stateless random sample).
In higher dimensions, you just take a random step on each axis, instead of only the x axis. The rest of the algorithm remains the same.
Regarding the random walk, it’s possible to use many different types of random numbers to take a step, but it’s most common to use a normal distribution.
Metropolis Burn in and 0.234
Metropolis is stateless, and has no memory of the past. Despite this, it’s common to do a “burn in” with MCMC where you throw out some number of samples before you start.
This might sound weird, but the reason for it is that there are good places to sample from and bad places to sample from, and this is an attempt to have the random walk find a better place to sample from.
For instance, if you were sampling from y=sin(x)*sin(x)*x from 0 to 2 pi, you’d have a pdf that had a shape like the bimodal function below:
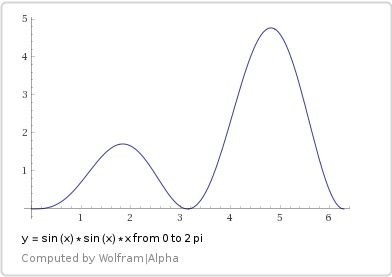
If you started the random walk at 2, you’d be doing a random walk in the left, less probable hump, and it would be hard to break out into the right side which was supposed to be more probable.
You should eventually get into the larger hump and stay there longer, but your initial guesses may get stuck in a local minimum and not do a very good job of following the distribution.
While burn in can help situations like these, this is also an example of how the Metropolis algorithm can fail.
It’s worth noting that using a normal distribution for the random walk can help it not get stuck in bad places. If you have a uniform random distribution that can generate numbers between -k and +k, you can get stuck in situations where you need to take a larger than k step to get to a better (more probable) location. If instead you use a normal distribution, the sigma allows you to have a good idea of how big most of the steps will be, but there will always be a greater than zero chance that you can take a step of ANY size, which could get you out of a local minimum.
There is a rule of thumb that the step size you use (the sigma in the case of a normal distribution) should make it so you are accepting a new step on your random walk 23.4% of the time. This supposedly is a good balance between exploration (finding better places elsewhere) and exploitation (staying in a good place) in many situations.
This isn’t fully settled though, as this is only true some of the time, and counter research has come up. (https://www.sciencedirect.com/science/article/pii/S0304414907002177)
I experimented at having a “Burn in” phase where it also adjusted the sigma to try and reach that 23.4% acceptance rate over the previous N samples. I didn’t play with it very long though, and was unable to get it to reliably reach that acceptance rate.
Even beyond the 0.234 acceptance rate goal, tuning the step size for your specific situation can help you get better or worse results. I didn’t play around with that much in my experimentation though, and found a sigma of 0.2 worked pretty well when working with functions in the 0-pi and 0-2pi range.
The initial starting point of your random walk can affect performance too obviously, since the burn in stage is supposed to find a better starting position.
Limiting the Function’s Range
In one of the tests I did, I used the function y=sin(x) with x going from 0 to pi/2.
At first i tried clamping x to 0 to pi/2, to keep it in range but doing that made the technique fall apart. There were plenty of times the random walk would try to step out of bounds, but instead of taking that step, it would clamp to the border. This meant that the random walk had a significantly higher chance of reaching the boundary than anywhere else on the graph, and that broke the algorithm.
The correct thing to do was to just make the function return 0 when x was out of range. In this way, it would end up taking any out of range location with 0% probability, but there was no bias about more or less likely places visited by the random walk, other than it preferring higher (more probable) parts of the function.
Something else worth noting about the function is that if the function ever returns a negative number, it ends up being the same as if it returned zero probability.
If use Metropolis MCMC for integration, this can be an important fact, because it will basically ignore the negative values, and treat them as zero.
Discrete Case
As described, this algorithm works with continuous random numbers, drawing them from a PDF.
The same concepts work for discrete states though too (a more traditional looking markov chain), drawing from a PMF instead.
When handling the discrete case, it needs to be possible to be in any state at any point in time. A usual way to avoid the edge case of probabilities being such that you can only be in some nodes on even steps and others on odd steps, is to have a “self loop” on at least one node, which has a greater than zero probability of staying at the same node.
This page has some great info about the discrete case:
Markov Chain Monte Carlo Without all the Bullshit
Integration
Using the Metropolis algorithm for numerical integration is possible, but is not as straightforward as Monte Carlo integration.
In Monte Carlo integration, to get a single estimate of an integral you calculate f(x) / pdf(x). f(x) is the function value at the random location x, and pdf(x) is the probability of that x value being chosen. You take the average of N such estimates and as N approaches infinity, the error of the average of estimates approaches 0.
In Metropolis MCMC we do have N number of samples, and it almost seems like we have enough data to do this, but it turns out that we don’t.
For f(x) which is the function value at the random location, you literally do have f(x). It’s the y component of each sample generated.
The problem is that we don’t have pdf(x).
The probability of choosing x is in fact based on the function we are evaluating f(x), but the function is essentially an un-normalized pdf, but we are able to draw random numbers from the pdf without knowing the normalization constant.
So, pdf(x) is some scalar multiple of f(x), but we have no idea what the multiplier is. That multiplier, the normalization constant, turns out to be the integration value we want to search for.
So we’ve gone in a circle and are no closer to being able to integrate with Metropolis.
There are some ways to deal with this though.
One way is to do mathematical tricks to make it so things “cancel out” and leave the normalization constant.
There is something called the “Harmonic Mean Estimator” that does this, but has infinite variance so is called “The Worst Monte Carlo Method Ever”.
https://radfordneal.wordpress.com/2008/08/17/the-harmonic-mean-of-the-likelihood-worst-monte-carlo-method-ever/
There is another way though, that I use in the code that goes with this post.
Imagine that while you are doing your Metropolis MCMC you have some interval [a,b] that whenever you get a random number drawn in that range, you increment a counter.
After N total samples, you’ll have M samples that fell in this interval. An estimate of the integral of the normalized pdf over this interval is M/N.
Now, you can do regular Monte Carlo integration of the function over this range to get the integral of the UN-normalized pdf over this interval.
When you divide the unnormallized pdf value by the normalized pdf value, you’ll get the normalization constant aka the integral of the function.
A smaller interval size is better for the Monte Carlo integration because it will converge faster (better results in fewer samples), but it’s worse for the Metropolis integration because a smaller interval is less likely to be accurate with the random walk.
My intuition tells me that if you keep a histogram of the x values you’ve seen be generated from the Metropolis algorithm, that the ones with higher counts are more likely to be accurate. So I just integrate over whatever histogram bucket has the highest count. I haven’t done any real analysis of whether or not this is true, or how good this integration estimate is in general.
For the Monte Carlo integration, I used white noise (regular old random numbers) to integrate, but in reality you’d get much better results from something like sobol. I used white noise because i made the code generic for N dimensions and white noise generalizes to any dimension.
Experiment Results
I didn’t play around much with initial guesses, sigmas, trying to reach the 0.234 acceptance rate, or burn in, but here’s some results from the code that goes with the post.
In the below, the blue line – normalized function value – is the actual desired PDF . The red line – Percentage – is how many samples we actually got in that histogram bucket. When these lines match up, we are happy and everything worked like we wanted it to.
y=sin(x) x in [0,pi]

y=|sin(x)| x in [0, 2pi]

y=sin(x)*sin(x) x in [0, 2pi]

It’s interesting to see the last one be so far from the real PDF. That function must trap the random walk in one side or the other a bit too much.
There is also a 2d function z=f(x,y) that is tested in the c++ code that goes with this post. I don’t know of any easy ways to make a 2d histogram so don’t have any results to show.
Links and Closing
The Metropolis algorithm is pretty neat but it’s just the beginning of MCMC methods. I’ve heard that Hamiltonian Monte Carlo can give much better results by using derivatives to make more intelligently sized step sizes.
Something I find interesting is that plain Monte Carlo uses white noise, quasi Monte Carlo uses low discrepancy sequences (and i think blue noise would fit in here), while Metropolis MCMC uses a random walk, which is red noise.
I’m not sure what to make of that, but my brief reading about Hamiltonian Monte Carlo was that it allows the samples to be less dependent, and that’s why it improves things. Maybe there are some secrets to red noise, like there are for blue noise? I’m not really sure but will keep looking 😛
A great write up on Metropolis MCMC
https://stephens999.github.io/fiveMinuteStats/MH_intro.html
Another small but useful write up
http://www.pmean.com/07/MetropolisAlgorithm.html
A 35 minute video about Metropolis MCMC
A mathier set of videos about Metropolis MCMC that is actually very easy to understand:
“A Zero-Math Introduction to Markov Chain Monte Carlo Methods”
https://towardsdatascience.com/a-zero-math-introduction-to-markov-chain-monte-carlo-methods-dcba889e0c50
A more mathy overview of Metropolis
https://ermongroup.github.io/cs323-notes/probabilistic/mh/
A series of posts aimed at being a gentle introduction to MCMC
https://theclevermachine.wordpress.com/tag/monte-carlo-integration/
A mutli branch twitter thread talking about some interesting MCMC related things
“Introduction to MCMC”
“MCMC Burn In”
