
UPDATE 6/25/2020: The bottom of the post now has a section about using 2D low discrepancy sequences with an alias table and compares results vs the 1D methods. The code has been updated as well to include that stuff.
In this post we are going to talk about Round Robin first, then Weighted Round Robin.
The ~500 lines of standalone C++ that generated the data for this blog post can be found at https://github.com/Atrix256/WeightedRR
Round Robin
Let’s say you find yourself in one of these 2 equivalent scenarios:
- You want to repeatedly choose from a list of 10 objects in a fair way, where the objects are chosen at roughly the same rate – like, a loot drop table for killing monsters in a game.
- You have 10 queues of work that you want to process work items from in a fair way, where work is consumed from the queues at roughly the same rate.
In either case you want a stream of integers between 0 and 9 where ideally any section – large or small – should have roughly even counts of those numbers chosen. In other words, it should have a flat histogram for both large and small sections.
One way to deal with this is to just walk through the numbers 0 through 9 over and over and over. You could increment a number whenever you wanted the next index and use modulus to ensure it was between 0 and 9.
I’m calling this “Sequential” in the graphs and that would work, but depending on your usage case, it might be undesirable that it was so obviously going in order from 0 to 9.
Another way to deal with this would be to roll a random integer 0 through 9 and use that as your answer. In the code, I roll a random float between 0 and 1 and remap that to an integer 0 through 9 so it’s more like the other methods. I’m calling this “White Noise” in the graphs and that also would work in that the histogram is going to be flat after an infinite number of samples, but it won’t be very flat in small numbers of samples.
Yet another way to deal with this is to use a low discrepancy sequence (deterministic or randomized aka blue noise) such as the golden ratio additive recurrence low discrepancy sequence which looks like this:
float GetNextValue(float x)
{
float newX = x + 1.61803398875f;
return newX - floor(newX);
}
In the above, the first value you ever plug into this function can be any number. It can be 0.0, but it doesn’t have to be.
1.61803398875 is the golden ratio and since we are dealing with values between 0 and 1, you could also use 0.61803398875 instead which is the fractional part of the golden ratio, but is also 1 divided by the golden ratio (the golden ratio conjugate).
The golden ratio is a good choice here because it’s an irrational number, meaning that from a mathematical point of view (ignoring limitations of computers for a second) it won’t ever repeat values.
The golden ratio is also an excellent choice among irrational numbers because it is the most irrational number. Less irrational numbers – like pi – still don’t repeat but they have “near repeats” which make them less good of a choice. Then there are numbers like the square root of 2, which are pretty decently irrational – more than pi, but less than the golden ratio.
An alternate way to write the code is like this, which gives you “random access” to the sequence, but is more prone to having floating point precision issues.
float GetValue(int index, float seed)
{
float newX = seed + float(index) * 1.61803398875f;
return newX - floor(newX);
}
If you use this in our problem for generating floating point values between 0 and 1 and remapping to integers 0 through 9, you will get fairly even counts of occurrences of those integers (a fairly flat histogram) from both small and large sections of the sequence.
Here is a screenshot of the program generating a sequence of 80 items, using the techniques talked about so far.

It’s hard to tell what the histogram looks like from that, but it is still a bit interesting looking at the difference in patterns of the numbers chosen. There are seeming patterns even in the golden ratio because the values are quantized to 10 possible values.
Here are histograms of 100 samples. It shows that white noise is doing noticeably worse than the irrational numbers, but the irrational numbers don’t have a winner that is easy to discern with the naked eye. Sequential can’t even be seen because it is by definition a completely flat histogram and so is a flat line at y=0.1.

Here are histograms of 10,000 samples. White noise and pi look about the same, but golden ratio and square root of 2 are much closer to the actual flat histogram value / sequential sequence.

Here are histograms of 1,000,000 samples. White noise is way worse than everything else, but it’s hard to see a winner from the rest of the group.

Here we remove white noise from the graph to see the others better. Pi shows being the worst. Square root of two is next, and then the golden ratio which is closest to the sequential / flat histogram line.

Round Robin vs Random Integers
When using white noise, round robin is just random integers. It’s the same as rolling dice. So what is the difference?
In the last section I say that using a low discrepancy sequence is better than using white noise, because it reaches the target histogram more accurately with fewer samples – fewer rolls of the dice.
The downside to this though is that the numbers are no longer random… a person viewing the sequence of numbers can almost certainly guess what the next number is going to be.
So, that makes it not useful to use these for places where randomization is important – like when gambling or for cryptography.
But, where this is useful is for places where fairness matters but randomness does not.
One example could be pulling work items from a work queue. Who cares if it is possible to guess which thread is going to get assigned the next item of work? The important thing is that the work is spread evenly.
Another example is in numerical integration in monte carlo integration, and also other stochastic rendering situations. This is more what I care about. In these situations, you don’t care if the choice can be predicted or not, but if you can reduce the amount of error vs the target distribution in fewer samples that means you’ll have less noise in your resulting image, which is ::chef kiss:: oh so great. A better image for the same processing power.
If you were in a situation that wanted randomness, but you still wanted some of these benefits, you should check out “blue noise”, which is a randomized version of low discrepancy sequences. A good place to start might be my post on generating blue noise in 2 dimensions, which you could modify to only generate 1 dimensional blue noise and use for this purpose.
Weighted Round Robin
Let’s say you find yourself in the same situation as before but now there are weighted probabilities involved.
- For the loot drop situation, different loot should be awarded with different probabilities.
- For the work queues, you could have different powered CPUs servicing the work queues maybe. More powerful processors should be more likely to get work served to them perhaps.
For our situation, we’ll say that the weight of item 0 is 1, the weight of item 1 is 2, and so on, up to the weight of item 9 being 10.
Let’s check out our options again.
First, we could go sequentially. This means that our sequence would go like this: 011222333344444… etc.
A possible issue with this (again, depending on your specific needs) is that it is even, but it goes through every occurrence of a number before moving to the next number. If it was desired that the numbers be visited in a more interleaved fashion, you’d want to try something else.
The next thing you could try is to take the item weights and divide them by the total of the item weights, so that they add up to 1.0. This would make them normalized. From here, we could roll a random floating point number between 0 and 1, find the item that has the range that contains that floating point number, and use that as the selected item.
That would solve the problem I mentioned, but would introduce the problem of white noise: while large sample counts have the right histogram (distribution), small sample counts don’t.
We could also use irrational numbers again, which would do better at reaching the correct histogram than white noise but become deterministic like sequential, but still shuffled “a bit”.
Here’s the program output for 80 item sequences of the various techniques:
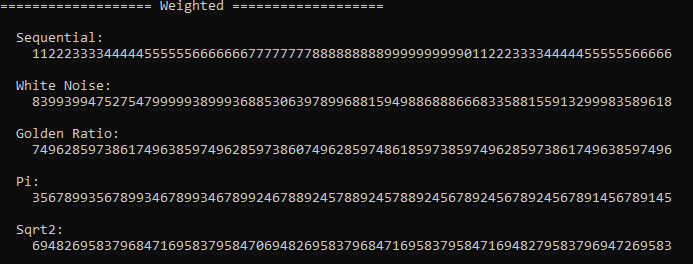
Here are histograms with 100 samples. The irrationals are all doing pretty well. White noise is not doing great. Strangely, sequential is also not doing real great for the last value because the sequence length doesn’t divide 100 evenly this time!
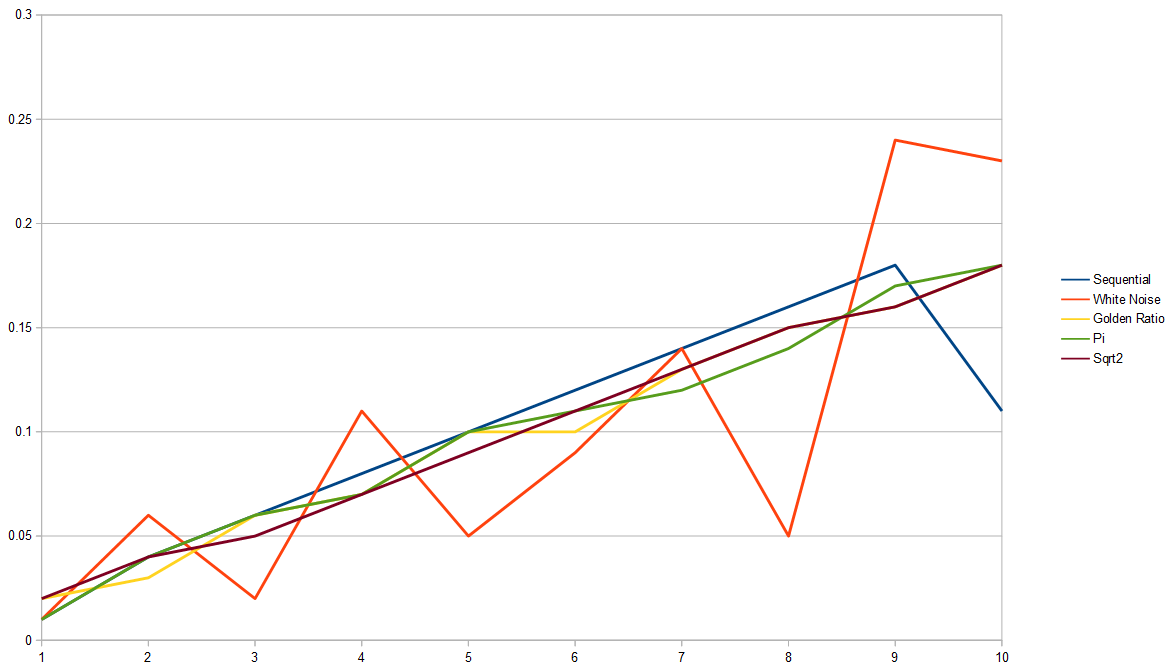
Here are histograms with 10,000 samples. It’s harder to see for sure who is winning by nature of the graph, compared to the last section, but we can see white noise is not doing great.
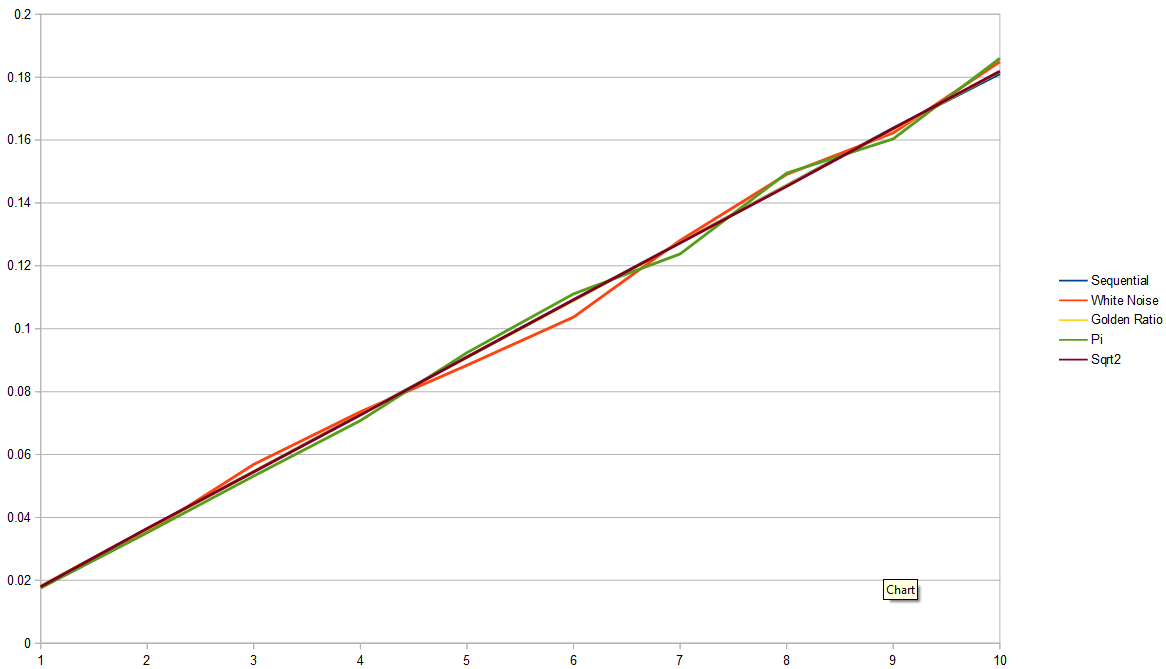
Here are histograms with 1,000,000 samples. It’s nearly impossible to see anything about it.

Here is the graph of subtracting sequential from the others. It shows that white noise is by far the worst.
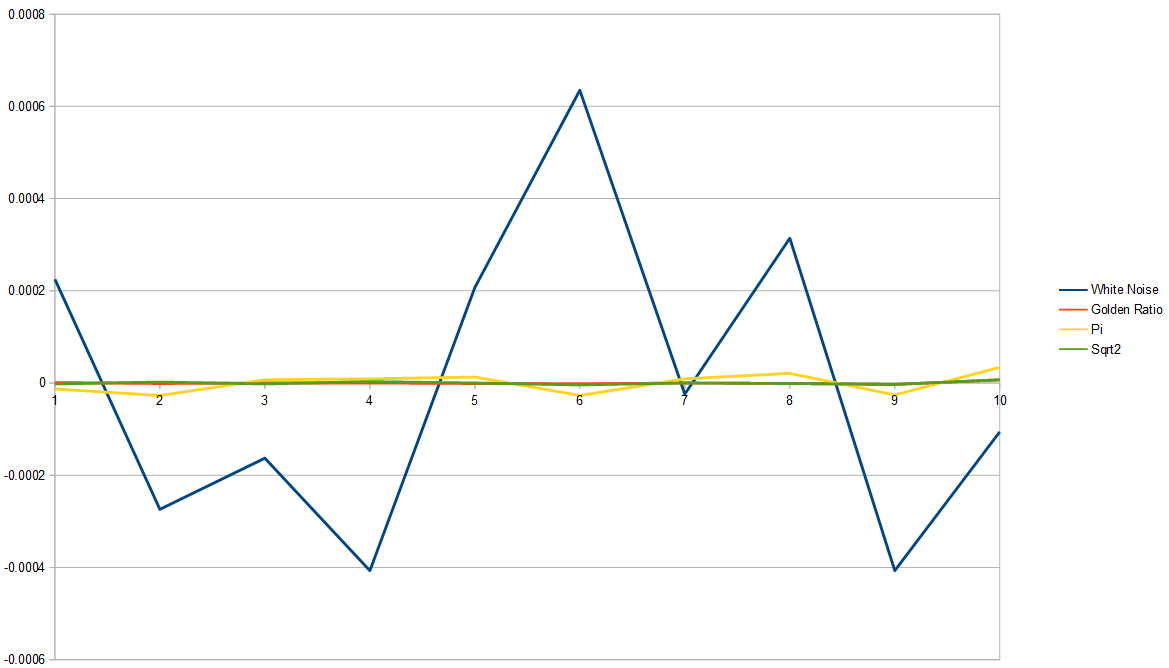
Removing white noise from that graph, we can see that pi is worst, golden ratio is best, and square root of 2 isn’t far behind the golden ratio.
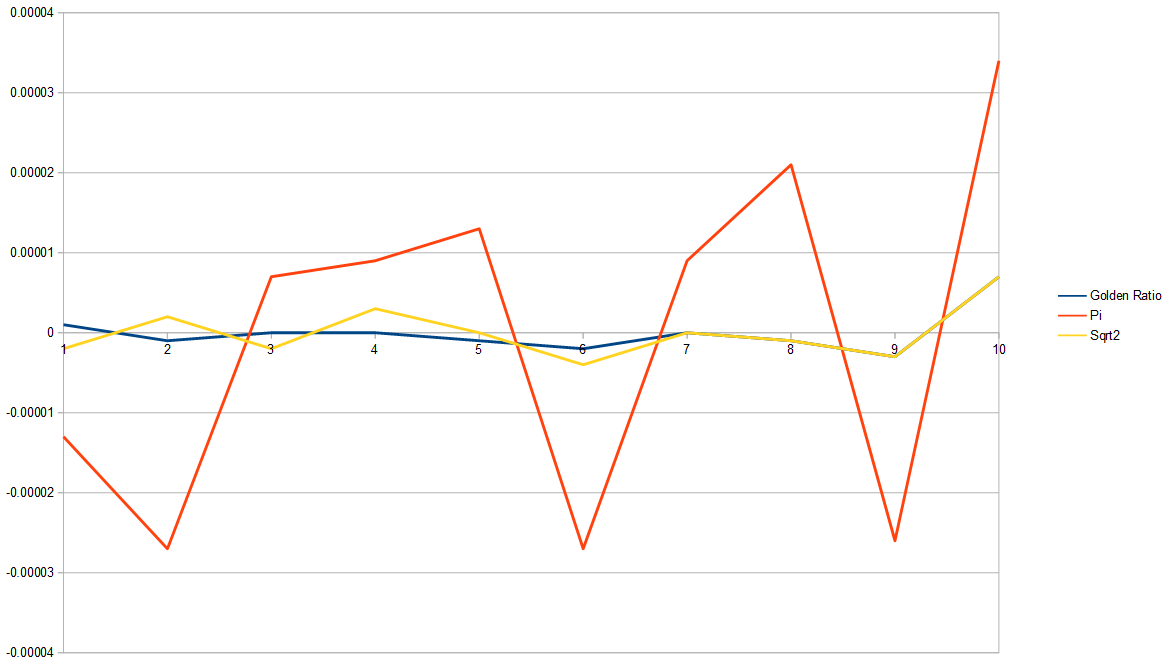
Old Closing (Before Alias Table Section Added)
If you look at the code, you might be saying to yourself that the weighted version isn’t great because you need a loop to convert the 1D floating point value in [0,1] to the weighted item chosen. If you switched to using an alias table, it’d be an O(1) constant time operation, but then the 1D value would not be enough – you’d need a 1d value and a biased coin flip. AKA just a 2d value that is [0,1] on each axis. It would be interesting to compare an alias table / 2D LDS sequence to see how it converged versus this method. I really, really, should have done that in this post and should do it soon.
Another option though would be to use a “branchless, fixed step count, binary search” which would also be a constant time lookup. Basically, if you had 16 items you were searching through, you can do it with four branchless operations. This is great for shaders, SIMD programming, hardware, and similar. You can read more about that technique in my post here: https://blog.demofox.org/2017/06/20/simd-gpu-friendly-branchless-binary-search/
Alias Tables & 2D Low Discrepancy Sequences
This section shows the effect of using 2d low discrepancy sequences with an alias table to find the weighted item in constant time O(1), instead of having to loop through the weights to find the correct item.
Using an alias table is faster, but having to use 2d low discrepancy sequences instead of 1d has the possibility to change things. The concept of evenly spaced and similar ideas gets a lot more open to interpretation when you leave the first dimension.
So, first things first, here’s a graph of 1d white noise compared with 2d white noise used to do a lookup into an alias table, for 10,000 samples. This is to show that the alias table works just like not using one, and that we are doing apples to apples comparisons. I’ve also added a “weights” to the graphs as the actual ground truth of the histogram, instead of relying on sequential which was imperfect.

I’m using three 2d low discrepancy sequences. They are:
- R2 – a generalization of the golden ratio to 2 dimensions. (more info here: http://extremelearning.com.au/unreasonable-effectiveness-of-quasirandom-sequences/)
- Sobol – a very strong and well known LDS, which is often the best LDS shown in the papers i’ve seen (except when reading blue noise papers, but that’s a different usage case and quality metric hehe)
- Golden Ratio / Square root of 2 – I use the golden ratio sequence on the x axis and the square root of 2 sequence on the y axis.
Here are the histograms for 100 samples, comparing the 3 LDSs vs white noise and the actual weights. 1D golden ratio is also here to compare how the 2d alias method techniques compare to the 1d golden ratio sampling. It seems to be showing that white noise and Sobol are the worst outliers, and everything else is better behaved.

Here are 10,000 samples. I’m switching to error (subtracted out “weights”) so it’s easier to see small differences. Now alias table white noise is the single outlier, and everything else seems to be playing pretty nicely and all just about even.
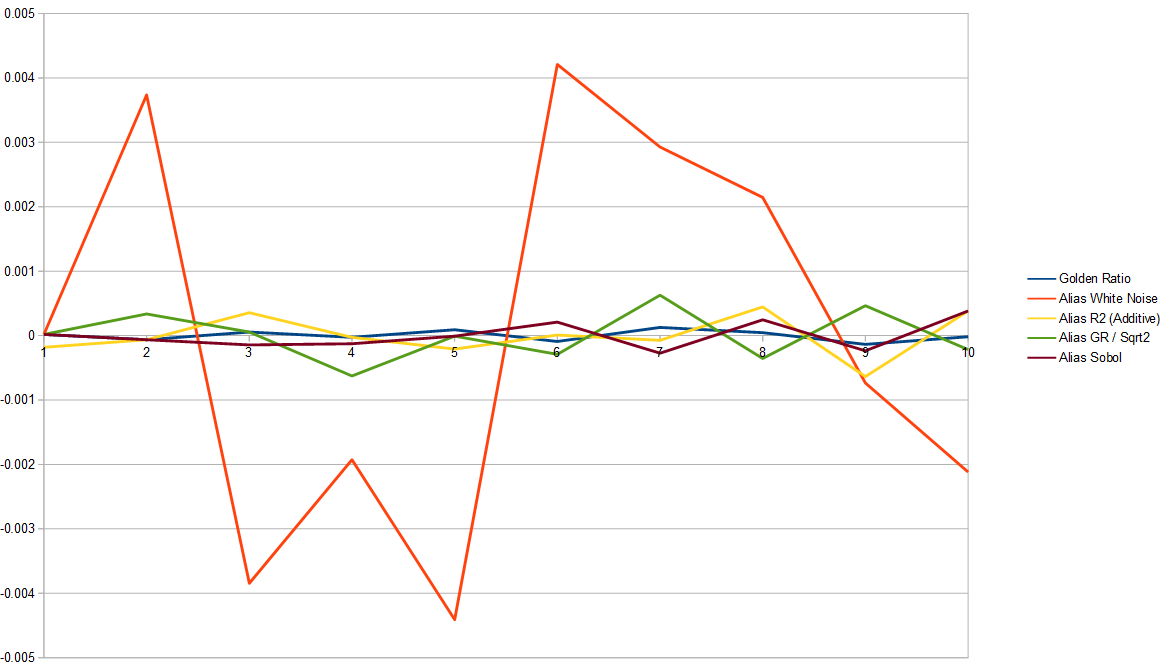
If we remove white noise we can zoom in and see things a little better. It looks like 1D golden ratio is the best, then Sobol. It’s hard to tell, but R2 seems like it might be doing better than golden ratio / square root of 2.
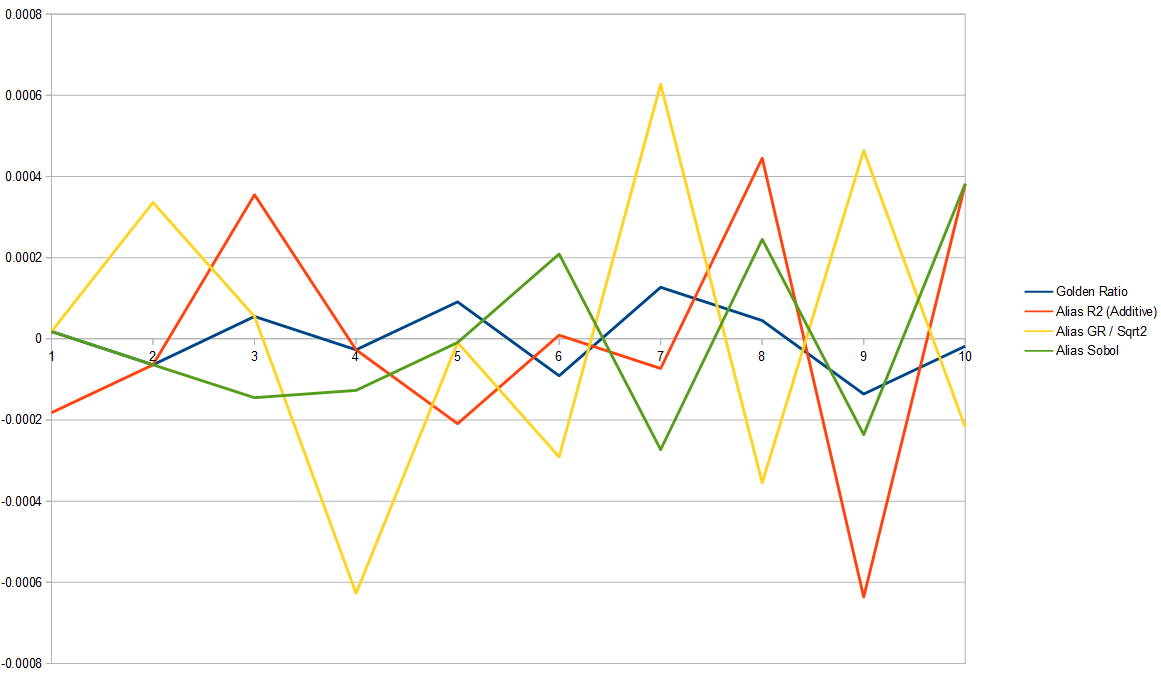
Here is the same for one million samples. 1D golden ratio seems to be the winner here and the others all seem to be doing about as well as each other.
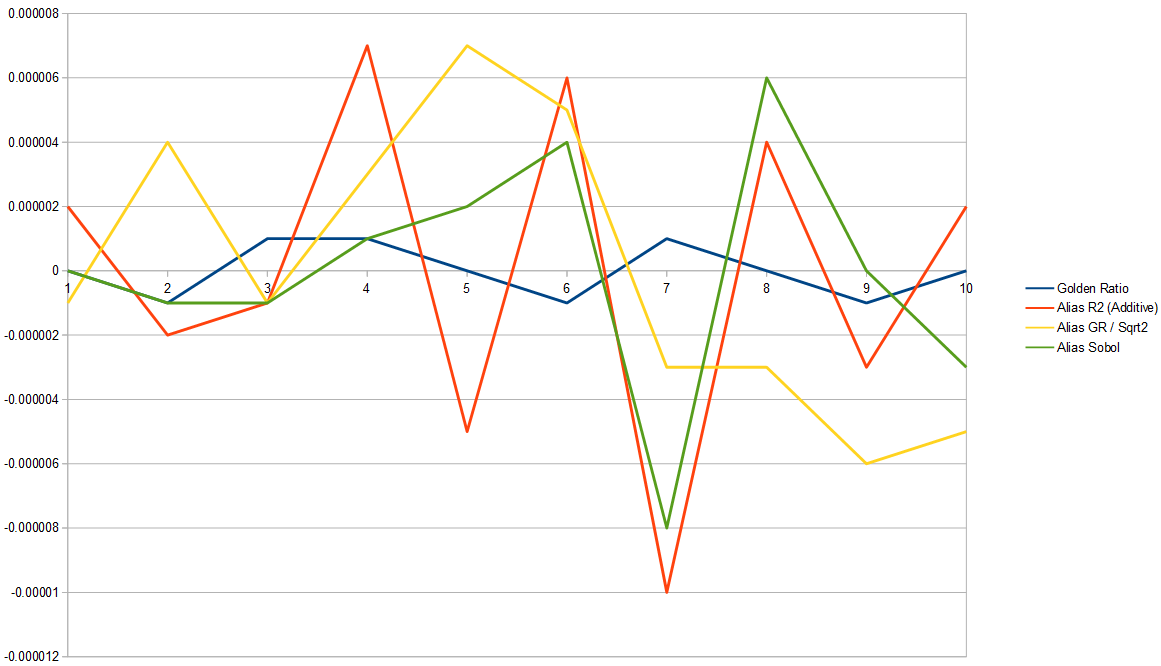
Conclusion: If you are using an alias table, you definitely should use a decent 2d low discrepancy sequence. However, it looks like you will not do as well quality wise, as using 1d golden ratio sampling without an alias table. Maybe there is a different sampling pattern to use in the alias table case that will do better though. If you know of such a thing, please share!
I wanted to show one more thing though before we go. You might notice the graphs all call R2 “additive”. If you are wondering why that is, it’s this 2D irrational low discrepancy sequence can be calculated two different ways, just like the 1D golden ratio low discrepancy sequence can. You can either multiply an index by the irrational number(s) and fract it to get the result, or you can start at index 1, add the irrational number(s) in, fract it, then go to index 2, repeating until you get to the index you want.
Doing it the first way with a multiply causes you to run into numerical issues (error due to floating point rounding, due to finite memory storage for floats), while the second has better precision. The second way is “additive” and i want to show you just how big a difference this makes by showing you the error of both kinds after 1 million samples, along with the error for white noise.

The error from r2 done via multiplication is so large that it dwarves even the error from white noise. It isn’t as noticeable at lower sample counts, because the floating point numbers are smaller, so will hit less severe rounding problems, but it still exists at lower sample counts. This isn’t unique to R2 either… this is true of any irrational additive recurrence low discrepancy sequence (including the 1D golden ratio sequence).
You probably would have better luck with doubles.
Another thing you can do is make it into a fixed point “unsigned int” representation of the irrational so that you don’t waste storage bits on features you don’t need from floats. More info on that here:
http://marc-b-reynolds.github.io/distribution/2020/01/24/Rank1Pre.html
Links
If you found this post interesting, you might like this other post, which talks about using LDS and blue noise for making loot drop tables, and how that helps the average player experience be more predictable, compared to regular old random numbers.
“Using Low Discrepancy Sequences & Blue Noise in Loot Drop Tables for Games”
https://blog.demofox.org/2020/03/01/using-low-discrepancy-sequences-blue-noise-in-loot-drop-tables-for-games/
There is a great video from numberphile that talks about why the golden ratio is the most irrational number. Check it out 🙂
When making the alias table, i used the stable Vose method from this page: https://www.keithschwarz.com/darts-dice-coins/

Really interesting! Thanks for adding the section about alias tables. I’d never heard of it and the explanation at https://www.keithschwarz.com/darts-dice-coins/ was brilliant.
In the Old Closing section, you state that for a lookup into an alias table, “you’d need a 1d value and a fair coin flip.”
What do you mean by that?
Don’t we need a 2D LDS (as you later state), which is different from a 1D value + fair coin flip?
LikeLike
Oops, sorry. you’d need a 1d value and a biased coin flip, which is just another 1d value. So, a 2d value in total. I’ll fix 🙂
LikeLike